The page that you are currently viewing is for an old version of Stroom (7.1). The documentation for the latest version of Stroom (7.12) can be found using the version drop-down at the top of the screen or by clicking here.
Indexing
Before you can visualise your data with dashboards you have to index the data.
Note
Stroom uses Apache Lucene for indexing its data but can also can also integrate with Solr and Elastic Search. For this Quick Start Guide we are going to use Stroom’s internal Lucence indexing.Create the index
We can create an index by adding an index entity
 to the explorer tree.
You do this in the same way you create any of the items.
to the explorer tree.
You do this in the same way you create any of the items.
-
Right click on the
 Stroom 101 folder and select:
Stroom 101 folder and select:
-
Call the index Stroom 101. Click OK.
This will open the new
Stroom 101 index as a new tab,
Stroom 101
×
.
Assign a volume group
In the settings tab we need to specify the Volume where we will store our index shards.
- Click the Settings sub-tab.
- In the Volume Group dropdown select Default Volume Group.
- Click the
 button.
button.
Adding fields
Now you need to add fields to this index.
The fields in the index may map 1:1 with the fields in the source data but you may want to index only a sub-set of the fields, e.g. if you would only ever want to filter the data on certain fields. Fields can also be created that are an abstraction of multiple fields in the data, e.g. adding all text in the record into one field to allow filtering on some text appearing anywhere in the record/event.
Click the Fields sub-tab.
We need to create fields in our index to match the fields in our source data so that we can query against them.
Click on the
button to add a new index field.
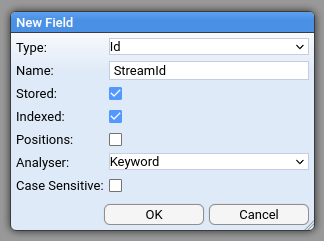
Now create the fields using these values.
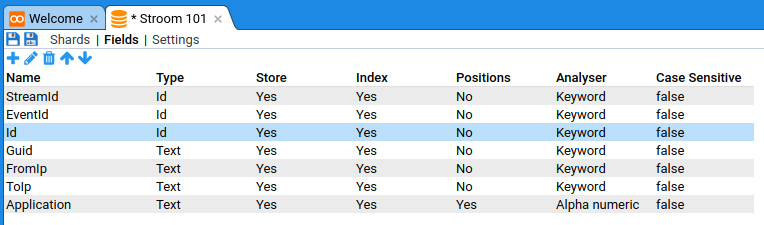
| Name | Type | Store | Index | Positions | Analyser | Case Sensitive |
|---|---|---|---|---|---|---|
| StreamId | Id | Yes | Yes | No | Keyword | false |
| EventId | Id | Yes | Yes | No | Keyword | false |
| Id | Id | Yes | Yes | No | Keyword | false |
| Guid | Text | Yes | Yes | No | Keyword | false |
| FromIp | Text | Yes | Yes | No | Keyword | false |
| ToIp | Text | Yes | Yes | No | Keyword | false |
| Application | Text | Yes | Yes | Yes | Alpha numeric | false |
Note
There are two mandatory fields that need to be added:StreamId and EventId.
These are not in the source records but are assigned to cooked events/records by Stroom.
You will see later how these fields get populated.
You should now have:
When you’ve done that, save the new index by clicking the
button.
Create empty index XSLT
In order for Stroom to index the data, an XSLT is required to convert the event XML into an Index record. This can be a simple 1:1 mapping from event field to index field or something more complex, e.g. combining multiple event fields into one index field.
To create the XSLT for the Index:
-
Right click on the
Stroom 101 folder in the explorer tree, then select:

-
Name it
Stroom 101. -
Click OK.
We will add the XSLT content later on.
Index pipeline
Now we are going to create a pipeline to send the processed data (Events) to the index we just created. Typically in Stroom all Raw Events are first processed into normalised Events conforming to the same XML schema to allow common onward processing of events from all sources.
We will create a pipeline to index the processed Event streams containing XML data.
-
Right click on the
Stroom 101 folder in the explorer tree, then select:

-
Name it
Stroom 101. -
Click OK.
Select the Structure sub-tab to edit the structure of the pipeline.
Pipelines can inherit from other pipelines in Stroom so that you can benefit from re-use. We will inherit from an existing indexing template pipeline and then modify it for our needs.
- On the Structure sub tab, click the
 in the Inherit From entity picker.
in the Inherit From entity picker. - Select
Template Pipelines /
Indexing
You should now see the following structure:

Inheriting from another pipeline often means the structure is there but some properties may not have been set, e.g. xslt in the xsltFilter.
If a property has been set in the partent pipeline then you can either use the inherited value or override it.
See the Pipeline Element Reference for details of what each element does.
Now we need to set the xslt property on the xsltFilter to point at the XSLT document we created earlier and set the index property on the indexFilter to point to the index we created.
- Assign the XSLT document
- Click on the
 XSLTFilter
element.
XSLTFilter
element. - In the middle Properties pane double-click on the
xsltrow. - Click the
in the Value document picker
- Select:
Stroom 101 /
Stroom 101. - Click .
- Click on the
- Assign the Index document
- Click on the
 IndexingFilter
element.
IndexingFilter
element. - In the middle Properties pane double-click on the
indexrow. - Click the
...in the Value document picker - Select:
Stroom 101 /
Stroom 101. - Click .
- Click on the
Once that’s done you can save your new pipeline by clicking the
button.
Develop index translation
Next we need to create an XSLT that the indexingFilter understands.
The best place to develop a translation is in the
Stepper
as it allows you to simulate running the data through the pipeline without producing any persistent output.
Open the
 CSV_FEED
Feed
we created earlier in the quick-start guide.
CSV_FEED
Feed
we created earlier in the quick-start guide.
- In the top pane of the Data Browser select the Events Events stream.
- In the bottom pane you will see the XML data the you processed earlier.
- Click the
 button to open the Stepper.
button to open the Stepper. - In the Choose Pipeline To Step With dialog select our index pipeline:
Stroom 101 /
Stroom 101.
This will open a Stepper tab showing only the elements of the selected pipeline that can be stepped. The data pane of the Source element will show the first event in the stream.
To add XSLT content click the
xsltFilter element.
This will show the three pane view with editable content (empty) in the top pane and input and output in the bottom two panes.
The input and output panes will be identical as there is no XSLT content to transform the input.
<?xml version="1.1" encoding="UTF-8"?>
<Events xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Event StreamId="25884" EventId="1">
<Id>1</Id>
<Guid>10990cde-1084-4006-aaf3-7fe52b62ce06</Guid>
<FromIp>159.161.108.105</FromIp>
<ToIp>217.151.32.69</ToIp>
<Application>Tres-Zap</Application>
</Event>
</Events>
<?xml version="1.1" encoding="UTF-8"?>
<Events xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Event StreamId="25884" EventId="1">
<Id>1</Id>
<Guid>10990cde-1084-4006-aaf3-7fe52b62ce06</Guid>
<FromIp>159.161.108.105</FromIp>
<ToIp>217.151.32.69</ToIp>
<Application>Tres-Zap</Application>
</Event>
</Events>
Paste the following content into the top pane.
<?xml version="1.0" encoding="UTF-8" ?>
<xsl:stylesheet
xmlns="records:2"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
version="2.0">
<!-- Match on the top level Events element -->
<xsl:template match="/Events">
<!-- Create the wrapper element for all the events/records -->
<records
xsi:schemaLocation="records:2 file://records-v2.0.xsd"
version="2.0">
<!-- Apply any templates to this element or its children -->
<xsl:apply-templates />
</records>
</xsl:template>
<!-- Match on any Event element at this level -->
<xsl:template match="Event">
<!-- Create a record element and populate its data items -->
<record>
<data name="StreamId">
<!-- Added to the event by the IdEnrichmentFiler -->
<xsl:attribute name="value" select="@StreamId" />
</data>
<data name="EventId">
<!-- Added to the event by the IdEnrichmentFiler -->
<xsl:attribute name="value" select="@EventId" />
</data>
<data name="Id">
<xsl:attribute name="value" select="./Id" />
</data>
<data name="Guid">
<xsl:attribute name="value" select="./Guid" />
</data>
<data name="FromIp">
<xsl:attribute name="value" select="./FromIp" />
</data>
<data name="ToIp">
<xsl:attribute name="value" select="./ToIp" />
</data>
<data name="Application">
<xsl:attribute name="value" select="./Application" />
</data>
</record>
</xsl:template>
</xsl:stylesheet>
The XSLT is converting Events/Event elements into Records/Record elements conforming to the records:2 XML Schema, which is the expected input format for the
IndexingFilter
.
The IndexingFilter expects a set of Record elements wrapped in a Records element.
Each Record element needs to contain one Data element for each Field in the Index.
Each Data element needs a Name attribute (the Index Field name) and a Value attribute (the value from the event to index).
Now click the
 refresh button to refresh the step with the new XSLT content.
refresh button to refresh the step with the new XSLT content.
The Output should have changed so that the Input and Output now look like this:
<?xml version="1.1" encoding="UTF-8"?>
<Events xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Event StreamId="25884" EventId="1">
<Id>1</Id>
<Guid>10990cde-1084-4006-aaf3-7fe52b62ce06</Guid>
<FromIp>159.161.108.105</FromIp>
<ToIp>217.151.32.69</ToIp>
<Application>Tres-Zap</Application>
</Event>
</Events>
<?xml version="1.1" encoding="UTF-8"?>
<records
xmlns="records:2"
xmlns:stroom="stroom"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="records:2 file://records-v2.0.xsd"
version="2.0">
<record>
<data name="StreamId" value="25884" />
<data name="EventId" value="1" />
<data name="Id" value="1" />
<data name="Guid" value="10990cde-1084-4006-aaf3-7fe52b62ce06" />
<data name="FromIp" value="159.161.108.105" />
<data name="ToIp" value="217.151.32.69" />
<data name="Application" value="Tres-Zap" />
</record>
</records>
You can use the stepping controls (



 ) to check that the ouput is correct for other input events.
) to check that the ouput is correct for other input events.
Once you are happy with your translation click the
button to save the XSLT content to the Stroom 101 XSLT document.
Processing the indexing pipeline
To get our indexing pipeline processing data we need to create a Processor Filter to select the data to process through the pipeline.
Go back to your
Stroom 101 pipeline and go to the Processors sub-tab.
Click the add button
and you will be presented with a Filter
Expression Tree
in the Add Filter dialog.
To configure the filter do the following:
- Right click on the root AND operator and click
Add Term.
A new expression is added to the tree as a child of the operator and it has three dropdowns in it (
Field
,
Condition
and value).
- To create an expression term for the Feed:
- Field:
Feed - Condition:
is - Value:
CSV_FEED
- Field:
- To create an expression term for the Stream Type:
- Field:
Type - Condition:
= - Value:
Events
- Field:
This filter will process all Streams of type Events in the Feed CSV_FEED.
Enable processing for the
Pipeline and the
 Processor Filter by clicking the checkboxes in the Enabled column.
Processor Filter by clicking the checkboxes in the Enabled column.
Stroom should then index the data, assuming everything is correct.
If there are errors you’ll see error streams produced in the data browsing page of the CSV_FEED Feed or the Stroom 101 Pipeline. If no errors have occurred, there will be no rows in the data browser page as the IndexFilter does not output any Streams.
To verify the data has been written to the Index:
- Open the
Stroom 101 Index.
- Select the Shards sub-tab.
- Click
 refresh.
You many need to wait a bit for the data to be flushed to the index shards.
refresh.
You many need to wait a bit for the data to be flushed to the index shards.
You should eventually see a Doc Count of 2,000 to match the number of events processed in the source Stream.
Now that we have finished indexing we can display data on a dashboard.