1 - Elasticsearch integration
Introduction
Stroom v6.1 can pass data to Elasticsearch for indexing.
Indices created using this process (i.e. those containing a StreamId and EventId corresponding to a particular Stroom instance)
are searchable via a Stroom dashboard, much like a Stroom Lucene index.
This integration provides operators with the flexibility to utilise the additional capabilities of Elasticsearch, (like clustering and replication) and expose indexed data for consumption by external analytic or processing tools.
This guide will take you through creating an Elasticsearch index, setting up an indexing pipeline, activating a stream processor and searching the indexed data in both Stroom and Elasticsearch.
Assumptions
- You have created an Elasticsearch cluster. For test purposes, you can quickly create a single-node cluster using Docker by following the steps in the Elasticsearch Docs (external link).
- The Elasticsearch cluster is reachable via HTTP/S from all Stroom nodes participating in stream processing.
- Elasticsearch security is disabled.
- You have a feed containing
Eventdata.
Key differences
- Unlike with Solr indexing, Elasticsearch field mappings are managed outside of Stroom, usually via the REST API (external link).
- Aside from creating the mandatory
StreamIdandEventIdfield mappings, explicitly defining mappings for other fields is optional. It is however, considered good practice to define these mappings, to ensure each field’s data type is correctly parsed and represented. For text fields, it also pays to ensure that the appropriate mapping parameters are used (external link), in order to satisfy your search and analysis requirements - and meet system resource constraints. - Unlike both Solr and Lucene indexing, it is not necessary to mark a field as
stored(i.e. storing its raw value in the inverted index). This is because Elasticsearch stores the content of the original document in the_sourcefield (external link), which is retrieved when populating search results. Provided the_sourcefield is enabled (as it is by default), a field is treated asstoredin Stroom and its value doesn’t need to be retrieved via an extraction pipeline.
Indexing data
Creating an index in Elasticsearch
The following cURL command creates an index named stroom_test in Elasticsearch cluster http://localhost:9200 consisting of the following fields:
StreamId(mandatory, must be of data typelong)EventId(mandatory, must also belong)Name(text). Uses the default analyzer, which tokenizes the text for matching on terms.fielddatais enabled, which allows for aggregating on these terms (external link).State(keyword). Supports exact matching.
The created index consists of 5 shards.
Note that the shard count cannot be changed after index creation, without a reindex.
See this guide (external link) on shard sizing.
After creating the index, you can add additional field mappings. Note the limitations (external link) in doing so, particularly the fact that it will not cause existing documents to be re-indexed. It is worthwhile to test index mappings on a subset of data before committing to indexing a large event feed, to ensure the resulting search experience meets your requirements.
Registering the index in Stroom
This step creates an Elasticsearch Index in the Stroom Tree and tells Stroom how to connect to your Elasticsearch cluster and index. Note that this process needs to be repeated for each index you create.
Steps
- Right-click on the folder in the Explorer Tree where you wish to create the index
- Select
New/Elasticsearch Index - Enter a valid name for the index. It is a good idea to choose one that reflects either the feed name being indexed, or if indexing multiple feeds, the nature of data they represent.
- In the index tab that just opened:
- Select the
Settingstab - Set the
Indexto the name of the index in Elasticsearch (e.g.stroom_testfrom the previous example) - Set the
Connection URLsto one or more Elasticsearch node URLs. If multiple, separate each URL with,. For example, a URL likehttp://data-0.elastic:9200,http://data-1.elastic:9200will balance requests to two data nodes within an Elasticsearch cluster. See this document for guidance on node roles. - Click
Test Connection. If the connection succeeds, and the index is found, a dialog is shown indicating the test was successful. Otherwise, an error message is displayed. - If the test succeeded, click the save button in the top-left. The
Fieldstab will now be populated with fields from the Elasticsearch index.
- Select the
Note
The field mappings list is only updated when index settings are changed, or a Stroom indexing or search task begins. The refresh button in theFields tab does not have any effect.
Setting index retention
As with Solr indexing, index document retention is determined by defining a Stroom query.
Setting a retention query is optional and by default, documents will be retained in an index indefinitely.
It is recommended for indices containing events spanning long periods of time, that Elasticsearch Index Lifecycle Management (external link) be used instead. The capabilities provided, such as automatic rollover to warm or cold storage tiers, are well worth considering, especially in high-volume production clusters.
Considerations when implementing ILM
- It is recommended that data streams are used when indexing data. These allow easier rollover and work well with ILM policies. A data stream is essentially a container for multiple date-based indices and to a search client such as Stroom, appears and is searchable like a normal Elasticsearch index.
- Use of data streams requires that a
@timestampfield of typedatebe defined for each document (instead of say,EventTime). - Implementing ILM policies requires careful capacity planning, including anticipating search and retention requirements.
Creating an indexing pipeline
As with Lucene and Solr indexing pipelines, indexing data using Elasticsearch uses a pipeline filter.
This filter accepts <record> elements and for each, sends a document to Elasticsearch for indexing.
Each <data> element contained within a <record> sets the document field name and value. You should ensure the name attribute
of each <data> element exactly matches the mapping property of the Elasticsearch index you created.
Steps
- Create a pipeline inheriting from the built-in
Indexingtemplate. - Modify the
xsltFilterpipeline stage to output the correct<records>XML (see the Quick-Start Guide. - Delete the default
indexingFilterand in its place, create anElasticIndexingFilter(see screenshot below). - Review and set the following properties:
batchSize(default:10,000). Number of documents to send in a single request to the Elasticsearch Bulk API (external link). Should usually be set to1,000or more. The higher the number, the more memory is required by both Stroom and Elasticsearch when sending or receiving the request.index(required). Set this to the target Elasticsearch index in the Stroom Explorer Tree.refreshAfterEachBatch(default:false). Refreshes the Elasticsearch index after each batch has finished processing. This makes any documents ingested in the batch available for searching. Unless search results are needed in near-real-time, it is recommended this be set tofalseand the index refresh interval be set to an appropriate value. See this document (external link) for guidance on optimising indexing performance.

Creating and activating a stream processor
Follow the steps as in this guide.
Checking data has been indexed
Query Elasticsearch, checking the fields you expect are there, and of the correct data type:
The following query displays five results:
You can also get an exact document count, to ensure this matches the number of events you are expecting:
For more information, see the Elasticsearch Search API documentation (external link).
Reindexing data
By default, the original document values are stored in an Elasticsearch index and may be used later on to re-index data (such as when a change is made to field mappings). This is done via the Reindex API (external link). Provided these values have not changed, it would likely be more efficient to use this API to perform a re-index, instead of processing data from scratch using a Stroom stream processor.
On the other hand, if the content of documents being output to Elasticsearch has changed, the Elasticsearch index will need to be re-created and the stream re-processed. Examples of where this would be required include:
- A new field is added to the indexing filter, which previously didn’t exist. That field needs to be searchable for all historical events.
- A field is renamed
- A field data type is changed
If a field is omitted from the indexing translation, there is no need for a re-index, unless you wish to reclaim the space occupied by that field.
Reindexing using a pipeline processor
- Delete the index. While it is possible to delete by query (external link), it is more efficient to drop the index. Additionally, deleting by query doesn’t actually remove data from disk, until segments are merged.
- Re-create the index (as shown earlier)
- Create a new pipeline processor to index the documents
Searching
Once indexed in Elasticsearch, you can search either using the Stroom Dashboard user interface, or directly against the Elasticsearch cluster.
The advantage of using Stroom to search is that it allows access to the raw source data (i.e. it is not limited to what’s stored in the index). It can also use extraction pipelines to enrich search results for export in a table.
Elasticsearch on the other hand, provides a rich Search REST API (external link) with powerful aggregations that can be used to generate reports and discover patterns and anomalies. It can also be readily queried using third-party tools.
Stroom
See the Dashboard page in the Quick-Start Guide.
Instead of selecting a Lucene index, set the target data source to the desired Elasticsearch index in the Stroom Explorer Tree.
Once the target data source has been set, the Dashboard can be used as with a Lucene or Solr index data source.
Elasticsearch
Elasticsearch queries can be performed directly against the cluster using the Search API (external link).
Alternatively, there are tools that make search and discovery easier and more intuitive, like Kibana (external link).
Security
It is important to note that Elasticsearch data is not encrypted at rest, unless this feature is enabled and the relevant licensing tier (external link) is purchased. Therefore, appropriate measures should be taken to control access to Elasticsearch user data at the file level.
For production clusters, the Elasticsearch security guidelines (external link) should be followed, in order to control access and ensure requests are audited.
You might want to consider implementing role-based access control (external link) to prevent unauthorised users of the native Elasticsearch API or tools like Kibana, from creating, modifying or deleting data within sensitive indices.
2 - Search API
-
Create an API Key for yourself, this will allow the API to authenticate as you and run the query with your privileges.
-
Create a Dashboard that extracts the data you are interested in. You should create a Query and Table.
-
Download the JSON for your Query. Press the download icon in the Query Pane to generate a file containing the JSON. Save the JSON to a file named query.json.
-
Use curl to send the query to Stroom.
-
The query response should be in a file named response.out.
-
Optional step: reformat the response to csv using
jq.
3 - Solr integration
Assumptions
- You are familiar with Lucene indexing within Stroom
- You have some data to index
Points to note
- A Solr core is the home for exactly one Stroom index.
- Cores must initially be created in Solr.
- It is good practice to name your Solr core the same as your Stroom Index.
Method
-
Start a docker container for a single solr node.
-
Check your Solr node. Point your browser at http://yourSolrHost:8983
-
Create a core in Solr using the CLI.
-
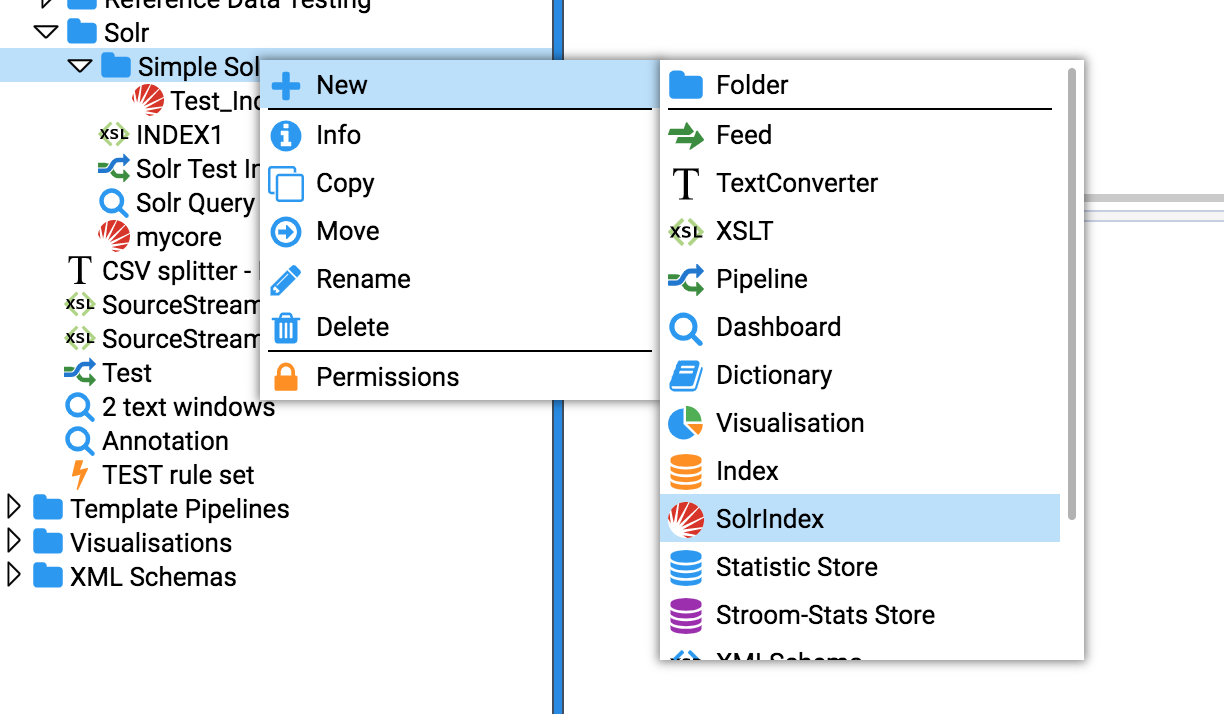
Create a SolrIndex in Stroom
-
Update settings for your new Solr Index in Stroom then press “Test Connection”. If successful then press Save. Note the “Solr URL” field is a reference to the newly created Solr core.
-
Add some Index fields. e.g.EventTime, UserId
-
Retention is different in Solr, you must specify an expression that matches data that can be deleted.
-
Your Solr Index can now be used as per a Stroom Lucene Index. However, your Indexing pipeline must use a SolrIndexingFilter instead of an IndexingFilter.