This is the multi-page printable view of this section. Click here to print.
Version 7.3
- 1: New Features
- 2: Preview Features (experimental)
- 3: Breaking Changes
- 4: Upgrade Notes
- 5: Change Log
1 - New Features
User Interface
-
Add a Copy button to the Processors sub-tab on the Pipeline screen. This will create a duplicate of an existing filter.
-
Add a Line Wrapping toggle button to the Server Tasks screen. This will enable/disable line wrapping on the Name and Info cells.
-
Allow pane resizing in dashboards without needing to be in design mode.
-
Add Copy and Jump to hover buttons to the Stream Browser screen to copy the value of the cell or (if it is a document) jump to that document.
-
Tagging of individual explorer nodes was introduced in v7.2. v7.3 however adds support for adding/removing tags to/from multiple explorer tree nodes via the explorer context menu.

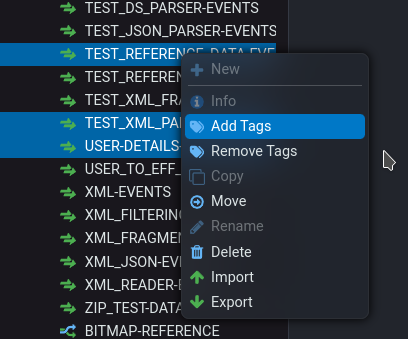
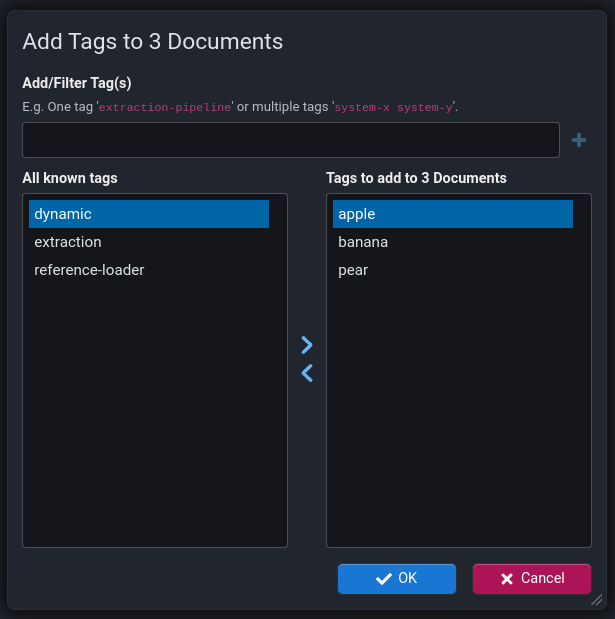
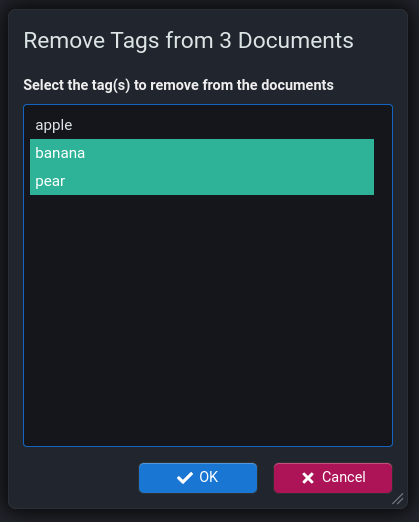
Explorer Tree
-
Additional buttons on the top of the explorer tree pane.
-
Add Expand All and Collapse All buttons to the explorer pane to open or close all items in the tree respectively.
-
Add a Locate Current Item button to the explorer pane to locate the currently open document in the explorer tree.
-
Finding Things
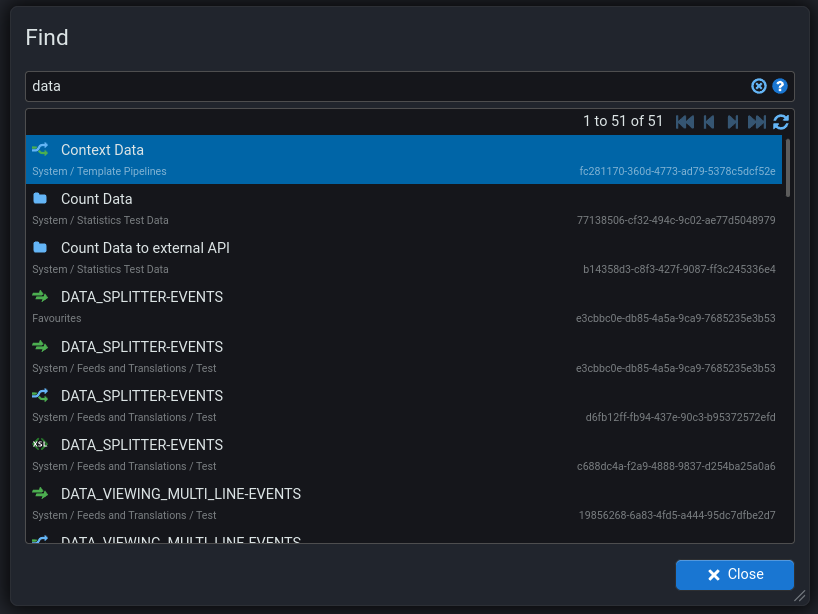
Find
New screen for finding documents by name. Accessed using Shift ⇧ + Alt + f or
Find In Content
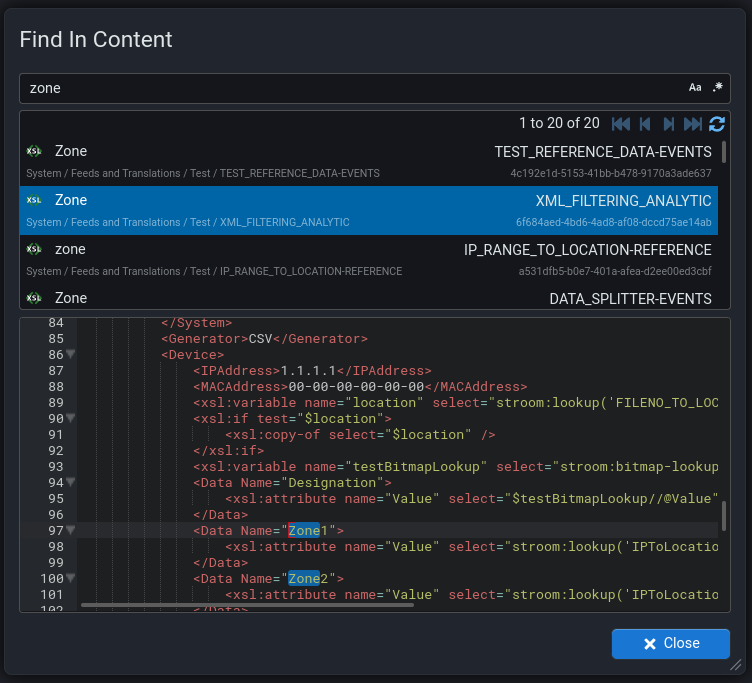
Improvements to the Find In Content screen so that it now shows the content of the document and highlights the matched terms. Now accessible using shift,ctrl + f or
Recent Items
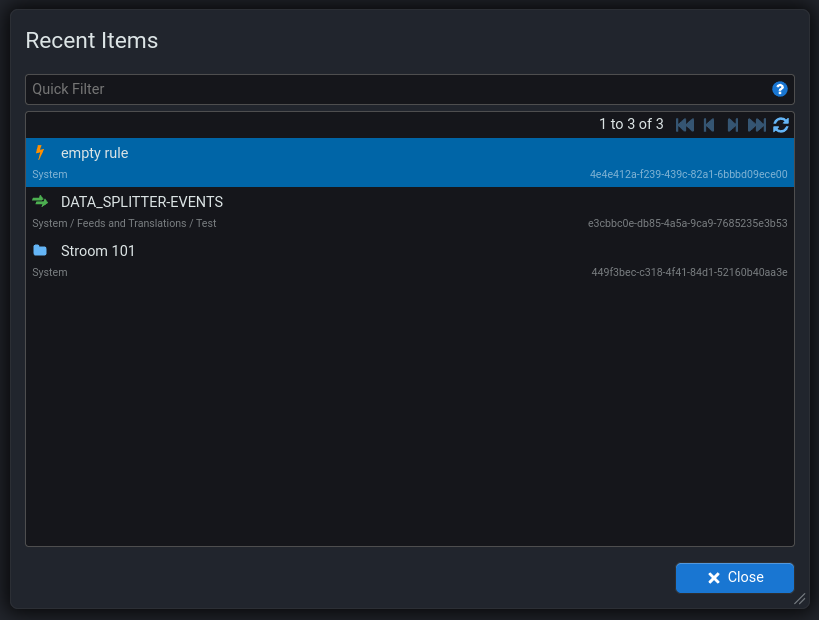
New screen for finding recently used documents. Accessed using Ctrl ^ + e or
Editor Snippets
Snippets are a way of quickly adding snippets of pre-defined text into the text editors in Stroom. Snippets have been available in previous versions of Stroom however there have been various additions to the library of snippets available which makes creating/editing content a lot easier.
-
Add snippets for Data Splitter. For the list of available snippets see here.
-
Add snippets for XMLFragmentParser. For the list of available snippets see here.
-
Add new XSLT snippets for
<xsl:element>and<xsl:message>. For the list of available snippets see here. -
Add snippets for StroomQl StroomQl Stroom Query Language is Stroom’s own query language. It has similarities with Structured Query Language (SQL) as used in databases. StroomQL is sometimes referred to as sQL to distinguish it from SQL.Click to see more details.... For the list of available snippets see here.
API Keys
API Keys are a means for client systems to authenticate with Stroom. In v7.2 of Stroom, the ability to use API Keys was removed if you were using an external Identity Provider (IDP) Identity Provider (IDP) An Identity Provider is a system or service that can authenticate a user and assert their identity. Identity providers can support single sign on (SSO), which allows the user to sign in once to the Identity Provider so they are then authenticated to all systems using that IDP.Click to see more details... as client systems could get tokens from the IDP themselves. In v7.3 the ability to use API Keys with an external IDP has returned as we felt it offered client systems a choice and removed the complexity of dealing with the IDP.
The API Keys screen has undergone various improvements:
- Look/feel brought in line with other screens in Stroom.
- Ability to temporarily enable/disable API Keys. A key that is disabled in Stroom cannot be authenticated against.
- Deletion of an API Key prevents any future authentication against that key.
- Named API Keys to indicate purpose, e.g. naming a key with the client system’s name.
- Comments for keys to add additional context/information for a key.
- API Key prefix to aid with identifying an API Key.
- The full API key string is no longer stored in Stroom and cannot be viewed after creation.

Key Creation
The screens for creating a new API Key are as follows:
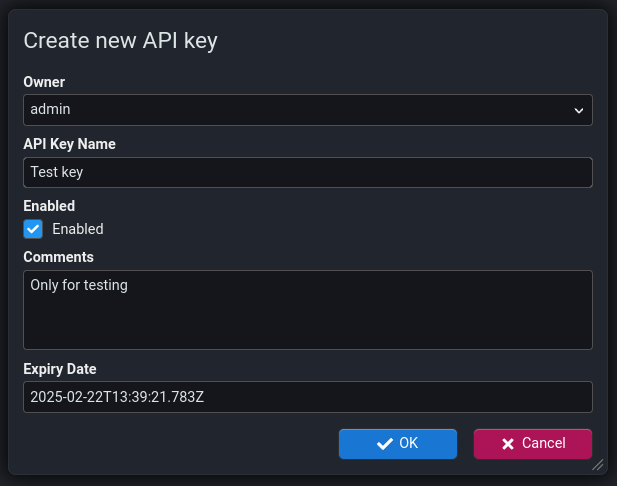
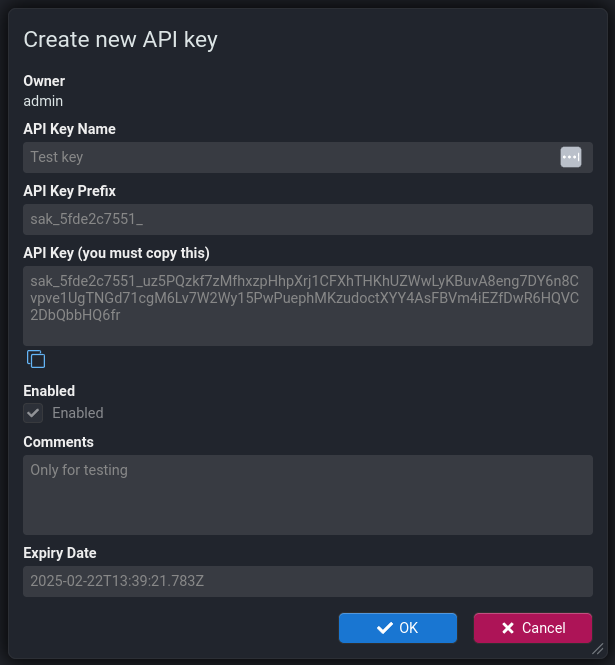
Warning
Note that the actual API Key is ONLY visible on the second dialog. Once that dialog is closed Stroom cannot show you the API Key string as it does not store it. This is for security reasons. You must copy the created key and give it to the recipient at this point.Key Format
We have also made changes to the format of the API Key itself. In v7.2, the API Key was an OAuth token so had data baked into it. In v7.3, the API Key is essentially just a dumb random string, like a very long and secure password. The following is an example of a new API Key:
sak_e1e78f6ee0_6CyT2Mpj2seVJzYtAXsqWwKJzyUqkYqTsammVerbJpvimtn4BpE9M5L2Sx6oeG5prhyzcA7U6fyV5EkwTxoXJPfDWLneQAq16i5P75qdQNbqJ99Wi7xzaDhryMdhVZhs
The structure of the key is as follows:
sak- The key type, Stroom API Key._- separator- Truncated SHA2-256 hash (truncated to 10 chars) of the whole API Key.
_- separator- 128 crypto random chars in the Base58 character set.
This character set ensures no awkward characters that might need escaping and removes some ambiguous characters (
0OIl).
Features of the new format are:
- Fixed length of 143 chars with fixed prefix (
sak_) that make it easier to search for API Keys in config, e.g. to stop API Keys being leaked into online public repositories and the like. - Unique prefix (e.g.
sak_e1e78f6ee0_) to help link an API being used by a client with the API Key record stored in Stroom. This part of the key is stored and displayed in Stroom. - The hash part acts as a checksum for the key to ensure it is correct. The following CyberChef recipe shows how you can validate the hash part of a key.
Analytics
-
Add distributed processing for streaming analytics. This means streaming analytics can now run on all nodes in the cluster rather than just one.
-
Add multiple recipients to rule notification emails. Previously only one recipient could be added.
Search
-
Add support for Lucene 9.8.0 and supporting multiple version of Lucene. Stroom now stores the Lucene version used to create an index shard against the shard so that the correct Lucene version is used when reading/writing from that shard. This will allow Stroom to harness new Lucene features in future while maintaining backwards compatibility with older versions.
-
Add support for
field inandfield in dictionaryto StroomQl StroomQl Stroom Query Language is Stroom’s own query language. It has similarities with Structured Query Language (SQL) as used in databases. StroomQL is sometimes referred to as sQL to distinguish it from SQL.Click to see more details....
Processing
-
Improve the display of processor filter state. The columns
Tracker MsandTracker %have been removed and theStatuscolumn has been improved better reflect the state of the filter tracker. -
Stroom now supports the XSLT standard element
<xsl:message>. This element will be handled as follows:<!-- Log `some message` at severity `FATAL` and terminate processing of that stream part immediately. Note that `terminate="yes"` will trump any severity that is also set. --> <xsl:message terminate="yes">some message</xsl:message> <!-- Log `some message` at severity `ERROR`. --> <xsl:message>some message</xsl:message> <!-- Log `some message` at severity `FATAL`. --> <xsl:message><fatal>some message</fatal></xsl:message> <!-- Log `some message` at severity `ERROR`. --> <xsl:message><error>some message</error></xsl:message> <!-- Log `some message` at severity `WARNING`. --> <xsl:message><warn>some message</warn></xsl:message> <!-- Log `some message` at severity `INFO`. --> <xsl:message><info>some message</info></xsl:message> <!-- Log $msg at severity `ERROR`. --> <xsl:message><xsl:value-of select="$msg"></xsl:message>The namespace of the severity element (e.g.
<info>is ignored. -
Add the following pipeline element properties to allow control of logged warnings for removal/replacement respectively.
- Add property
warnOnRemovalto InvalidCharFilterReader . - Add property
warnOnReplacementto InvalidXMLCharFilterReader .
- Add property
XSLT Functions
- Add XSLT function
stroom:hex-to-string(hex, charsetName). - Add XSLT function
stroom:cidr-to-numeric-ip-rangeXSLT function. - Add XSLT function
stroom:ip-in-cidrfor testing whether an IP address is within the specified CIDR range.
For details of the new functions, see XSLT Functions.
API
- Add the un-authenticated API method
/api/authproxy/v1/noauth/fetchClientCredsTokento effectively proxy for the IDP's Identity Provider (IDP) An Identity Provider is a system or service that can authenticate a user and assert their identity. Identity providers can support single sign on (SSO), which allows the user to sign in once to the Identity Provider so they are then authenticated to all systems using that IDP.Click to see more details... token endpoint to obtain an access token using the client credentials flow. The request contains the client credentials and looks like{ "clientId": "a-client", "clientSecret": "BR9m.....KNQO" }. The response media type istext/plainand contains the access token.
2 - Preview Features (experimental)
S3 Storage
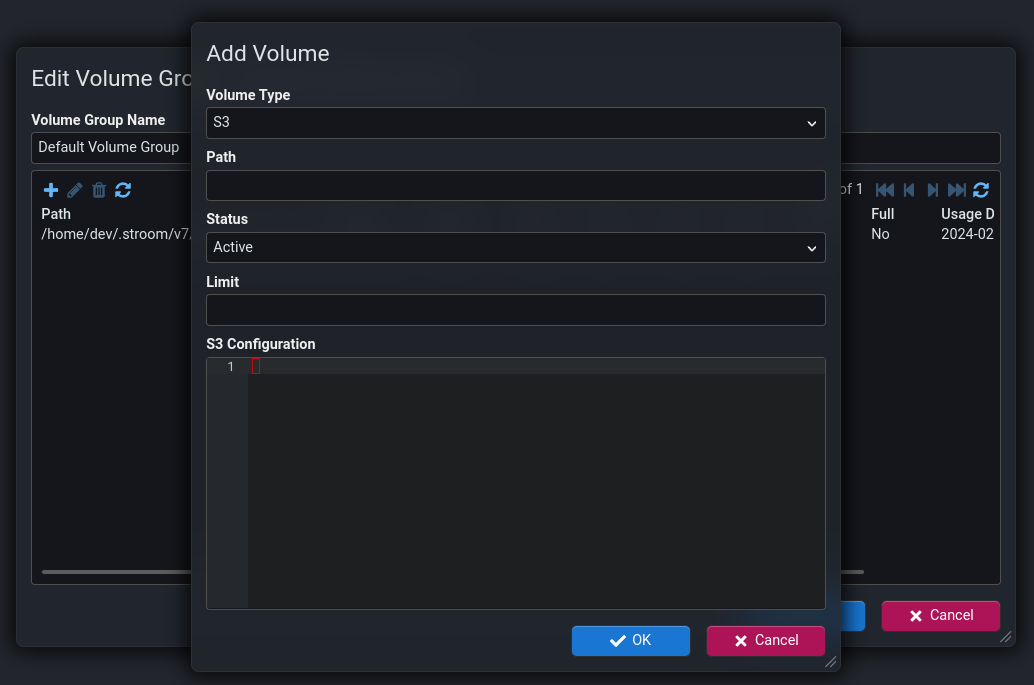
Integration with S3 storage has been added to allow Stroom to read/write to/from S3 storage, e.g. S3 on AWS.
A data volume can now be create as either Standard or S3.
If configured as S3 you need to supply the S3 configuration data.
This is an experimental feature at this stage and may be subject to change. The way Stroom reads and writes data has not been optimised for S3 so performance at scale is currently unknown.
3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.-
The Hessian based feed status RPC service
/remoting/remotefeedservice.rpchas been removed as it is using the legacyjavax.servletdependency that is incompatible withjakarta.servletthat is now in use in stroom. This was used by Stroom-Proxy up to v5. -
The StroomQL keyword combination
vis ashas been replaced withshow.
4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom instance.Java Version
Stroom v7.3 requires Java v21. Previous versions of Stroom used Java v17 or lower. You will need to upgrade Java on the Stroom and Stroom-Proxy hosts to the latest patch release of Java v21.
API Keys
With the change to the format of API Keys (see here), it is recommended to migrate legacy API Keys over to the new format. There is no hard requirement to do this as legacy keys will continue to work as is, however the new keys are easier to work with and Stroom has more control over the new format keys, making them more secure. You are encouraged to create new keys for client systems and ask them to change the keys over.
Legacy Key Migration
The new API Keys are now stored in a new table api_key.
Legacy keys will be migrated into this table and given a key name and prefix like LEGACY_API_KEY_N, where N is a unique number.
As the whole API was previously visible in v7.2, the API Key string is migrated into the Comments field so remains visible in the UI.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Migration Scripts
For information purposes only, the following are the database migrations that will be run when upgrading to 7.3.0 from the previous minor version.
Note, the legacy module will run first (if present) then the other module will run in no particular order.
Module stroom-data
Script V07_03_00_001__fs_volume_s3.sql
Path: stroom-data/stroom-data-store-impl-fs-db/src/main/resources/stroom/data/store/impl/fs/db/migration/V07_03_00_001__fs_volume_s3.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
CREATE TABLE IF NOT EXISTS fs_volume_group (
id int NOT NULL AUTO_INCREMENT,
version int NOT NULL,
create_time_ms bigint NOT NULL,
create_user varchar(255) NOT NULL,
update_time_ms bigint NOT NULL,
update_user varchar(255) NOT NULL,
name varchar(255) NOT NULL,
-- 'name' needs to be unique because it is used as a reference
UNIQUE (name),
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
DROP PROCEDURE IF EXISTS V07_03_00_001;
DELIMITER $$
CREATE PROCEDURE V07_03_00_001 ()
BEGIN
DECLARE object_count integer;
-- Add volume type
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'fs_volume'
AND column_name = 'volume_type';
IF object_count = 0 THEN
ALTER TABLE `fs_volume` ADD COLUMN `volume_type` int NOT NULL;
ALTER TABLE `fs_volume` ADD COLUMN `data` longblob;
UPDATE `fs_volume` set `volume_type` = 0;
END IF;
-- Add default group
SELECT COUNT(*)
INTO object_count
FROM fs_volume_group
WHERE name = "Default";
IF object_count = 0 THEN
INSERT INTO fs_volume_group (
version,
create_time_ms,
create_user,
update_time_ms,
update_user,
name)
VALUES (
1,
UNIX_TIMESTAMP() * 1000,
"Flyway migration",
UNIX_TIMESTAMP() * 1000,
"Flyway migration",
"Default Volume Group");
END IF;
-- Add volume group
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'fs_volume'
AND column_name = 'fk_fs_volume_group_id';
IF object_count = 0 THEN
ALTER TABLE `fs_volume`
ADD COLUMN `fk_fs_volume_group_id` int NOT NULL;
UPDATE `fs_volume` SET `fk_fs_volume_group_id` = (SELECT `id` FROM `fs_volume_group` WHERE `name` = "Default Volume Group");
ALTER TABLE fs_volume
ADD CONSTRAINT fs_volume_group_fk_fs_volume_group_id
FOREIGN KEY (fk_fs_volume_group_id)
REFERENCES fs_volume_group (id);
END IF;
END $$
DELIMITER ;
CALL V07_03_00_001;
DROP PROCEDURE IF EXISTS V07_03_00_001;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Module stroom-index
Script V07_03_00_001__index_field.sql
Path: stroom-index/stroom-index-impl-db/src/main/resources/stroom/index/impl/db/migration/V07_03_00_001__index_field.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP PROCEDURE IF EXISTS drop_field_source;
DELIMITER //
CREATE PROCEDURE drop_field_source ()
BEGIN
IF EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'field_info') THEN
DROP TABLE field_info;
END IF;
IF EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'field_source') THEN
DROP TABLE field_source;
END IF;
IF EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'field_schema_history') THEN
DROP TABLE field_schema_history;
END IF;
END//
DELIMITER ;
CALL drop_field_source();
DROP PROCEDURE drop_field_source;
--
-- Create the field_source table
--
CREATE TABLE IF NOT EXISTS `index_field_source` (
`id` int NOT NULL AUTO_INCREMENT,
`type` varchar(255) NOT NULL,
`uuid` varchar(255) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `index_field_source_type_uuid` (`type`, `uuid`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
--
-- Create the index_field table
--
CREATE TABLE IF NOT EXISTS `index_field` (
`id` bigint NOT NULL AUTO_INCREMENT,
`fk_index_field_source_id` int NOT NULL,
`type` tinyint NOT NULL,
`name` varchar(255) NOT NULL,
`analyzer` varchar(255) NOT NULL,
`indexed` tinyint NOT NULL DEFAULT '0',
`stored` tinyint NOT NULL DEFAULT '0',
`term_positions` tinyint NOT NULL DEFAULT '0',
`case_sensitive` tinyint NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `index_field_source_id_name` (`fk_index_field_source_id`, `name`),
CONSTRAINT `index_field_fk_index_field_source_id` FOREIGN KEY (`fk_index_field_source_id`) REFERENCES `index_field_source` (`id`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set tabstop=4 shiftwidth=4 expandtab:
Script V07_03_00_005__index_field_change_pk.sql
Path: stroom-index/stroom-index-impl-db/src/main/resources/stroom/index/impl/db/migration/V07_03_00_005__index_field_change_pk.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DELIMITER $$
DROP PROCEDURE IF EXISTS modify_field_source$$
-- The surrogate PK results in fields from different indexes all being mixed together
-- in the PK index, which causes deadlocks in batch upserts due to gap locks.
-- Change the PK to be (fk_index_field_source_id, name) which should keep the fields
-- together.
CREATE PROCEDURE modify_field_source ()
BEGIN
-- Remove existing PK
IF EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.columns
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'index_field'
AND COLUMN_NAME = 'id') THEN
ALTER TABLE index_field DROP COLUMN id;
END IF;
-- Add the new PK
IF NOT EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.table_constraints
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'index_field'
AND CONSTRAINT_NAME = 'PRIMARY') THEN
ALTER TABLE index_field ADD PRIMARY KEY (fk_index_field_source_id, name);
END IF;
-- Remove existing index that is now served by PK
IF EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.table_constraints
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'index_field'
AND CONSTRAINT_NAME = 'index_field_source_id_name') THEN
ALTER TABLE index_field DROP INDEX index_field_source_id_name;
END IF;
END $$
DELIMITER ;
CALL modify_field_source();
DROP PROCEDURE IF EXISTS modify_field_source;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set tabstop=4 shiftwidth=4 expandtab:
Module stroom-processor
Script V07_03_00_001__processor.sql
Path: stroom-processor/stroom-processor-impl-db/src/main/resources/stroom/processor/impl/db/migration/V07_03_00_001__processor.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP PROCEDURE IF EXISTS modify_processor;
DELIMITER //
CREATE PROCEDURE modify_processor ()
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.table_constraints
WHERE table_schema = database()
AND table_name = 'processor'
AND constraint_name = 'processor_pipeline_uuid';
IF object_count = 1 THEN
ALTER TABLE processor DROP INDEX processor_pipeline_uuid;
END IF;
SELECT COUNT(1)
INTO object_count
FROM information_schema.table_constraints
WHERE table_schema = database()
AND table_name = 'processor'
AND constraint_name = 'processor_task_type_pipeline_uuid';
IF object_count = 0 THEN
CREATE UNIQUE INDEX processor_task_type_pipeline_uuid ON processor (task_type, pipeline_uuid);
END IF;
END//
DELIMITER ;
CALL modify_processor();
DROP PROCEDURE modify_processor;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Script V07_03_00_005__processor_filter.sql
Path: stroom-processor/stroom-processor-impl-db/src/main/resources/stroom/processor/impl/db/migration/V07_03_00_005__processor_filter.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- --------------------------------------------------
DELIMITER $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS processor_run_sql_v1 $$
-- DO NOT change this without reading the header!
CREATE PROCEDURE processor_run_sql_v1 (
p_sql_stmt varchar(1000)
)
BEGIN
SET @sqlstmt = p_sql_stmt;
SELECT CONCAT('Running sql: ', @sqlstmt);
PREPARE stmt FROM @sqlstmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS processor_add_column_v1$$
-- DO NOT change this without reading the header!
CREATE PROCEDURE processor_add_column_v1 (
p_table_name varchar(64),
p_column_name varchar(64),
p_column_type_info varchar(64) -- e.g. 'varchar(255) default NULL'
)
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = p_table_name
AND column_name = p_column_name;
IF object_count = 0 THEN
CALL processor_run_sql_v1(CONCAT(
'alter table ', database(), '.', p_table_name,
' add column ', p_column_name, ' ', p_column_type_info));
ELSE
SELECT CONCAT(
'Column ',
p_column_name,
' already exists on table ',
database(),
'.',
p_table_name);
END IF;
END $$
-- idempotent
CALL processor_add_column_v1(
'processor_filter',
'max_processing_tasks',
'int NOT NULL DEFAULT 0');
-- vim: set shiftwidth=4 tabstop=4 expandtab:
5 - Change Log
For a detailed list of all the changes in v7.3 see: v7.3 CHANGELOG