This is the multi-page printable view of this section. Click here to print.
Release Notes
- 1: Unreleased
- 2: Version 7.12
- 2.1: New Features
- 2.2: Preview Features (experimental)
- 2.3: Breaking Changes
- 2.4: Upgrade Notes
- 2.5: Change Log
- 3: Version 7.11
- 3.1: New Features
- 3.2: Preview Features (experimental)
- 3.3: Breaking Changes
- 3.4: Upgrade Notes
- 3.5: Change Log
- 4: Version 7.10
- 4.1: New Features
- 4.2: Preview Features (experimental)
- 4.3: Breaking Changes
- 4.4: Upgrade Notes
- 4.5: Change Log
- 5: Version 7.9
- 5.1: New Features
- 5.2: Preview Features (experimental)
- 5.3: Breaking Changes
- 5.4: Upgrade Notes
- 5.5: Change Log
- 6: Version 7.8
- 6.1: New Features
- 6.2: Preview Features (experimental)
- 6.3: Breaking Changes
- 6.4: Upgrade Notes
- 6.5: Change Log
- 7: Version 7.7
- 7.1: New Features
- 7.2: Preview Features (experimental)
- 7.3: Breaking Changes
- 7.4: Upgrade Notes
- 7.5: Change Log
- 8: Version 7.6
- 8.1: New Features
- 8.2: Preview Features (experimental)
- 8.3: Breaking Changes
- 8.4: Upgrade Notes
- 8.5: Change Log
- 9: Version 7.5
- 9.1: New Features
- 9.2: Preview Features (experimental)
- 9.3: Breaking Changes
- 9.4: Upgrade Notes
- 9.5: Change Log
- 10: Version 7.4
- 10.1: New Features
- 10.2: Preview Features (experimental)
- 10.3: Breaking Changes
- 10.4: Upgrade Notes
- 10.5: Change Log
- 11: Version 7.3
- 11.1: New Features
- 11.2: Preview Features (experimental)
- 11.3: Breaking Changes
- 11.4: Upgrade Notes
- 11.5: Change Log
- 12: Version 7.2
- 12.1: New Features
- 12.2: Preview Features (experimental)
- 12.3: Breaking Changes
- 12.4: Upgrade Notes
- 12.5: Change Log
- 13: Version 7.1
- 14: Version 7.0
- 15: Version 6.1
- 16: Version 6.0
1 - Unreleased
2 - Version 7.12
2.1 - New Features
X509 Data Feed Identities
Data Feed Identities (formally Data Feed Keys v7.11) have been changed to include identities that authenticate using X509 certificates.
See Also
Auto Content Creation Changes
Additional configuration properties have been added to provide more control over auto-generated content.
See Also
2.2 - Preview Features (experimental)
There are no preview features in this release.
2.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.Stroom
No Stroom specific breaking changes.
Stroom-Proxy
No Stroom-Proxy specific breaking changes.
Stroom & Stroom-Proxy
The following breaking changes are common to both Stroom and Stroom Proxy.
Data Feed Keys
The property .receive.dataFeedKeysDir has been renamed to .receive.dataFeedIdentitiesDir.
The required structure of the files in this directory has changed. See Data Feed Identities for more details.
2.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom/Stroom-Proxy instance.Upgrade Path
You can upgrade to v7.12.x from any v7.x release that is older than the version being upgraded to.
If you want to upgrade to v7.12.x from v5.x or v6.x we recommend you do the following:
- Upgrade v5.x to the latest patch release of v6.0.
- Upgrade v6.x to the latest patch release of v7.0.
- Upgrade v7.x to the latest patch release of v7.12.
Warning
v7.12 cannot migrate content in legacy formats, i.e. content created in v5/v6. You must therefore upgrade to v7.0.x first to migrate this content, before upgrading to v7.12.x.Java Version
Stroom v7.12 requires Java 25.
Warning
This is different to the java version required for Stroom v7.9 (Java 21).Ensure the Stroom and Stroom-Proxy hosts are running the latest patch release of Java v25.
Configuration File Changes
Common Configuration Changes
These changes are common to both Stroom and Stroom Proxy.
Changes to receive Branch
The property dataFeedIdentitiesDir has been renamed from dataFeedKeysDir, and its default value has changed to data_feed_identities.
dataFeedIdentitiesDir: "data_feed_identities" # Default value changed from "data_feed_keys"
Stroom’s config.yml
Changes to autoContentCreation Branch
autoContentCreation:
# An optional group to add the group defined by groupTemplate to.
# The value of this property is the name of a group. It can be the same
# as groupParentGroupName if required.
# It allows all the templated groups to belong to a common group for easier
# permission management.
additionalGroupParentGroupName: "Data Feed Developer" # New property
# If set, when Stroom auto-creates a feed, it will create an additional user group with a
# name derived from this template. This is in addition to the user group defined by 'groupTemplate'.
# If not set, only the latter user group will be created. Default value is 'grp-${accountid}-dev'.
# If this property is set in the YAML file, use single quotes to prevent the
# variables being expanded when the config file is loaded.
additionalGroupTemplate: "grp-${accountid}-dev" # Default value changed from "grp-${accountid}-sandbox"
# An optional templated sub-path of 'destinationExplorerPathTemplate'. If set, copied dependencies (e.g.
# XSLT filters, Test Converters, etc.) will be created in the sub-directory defined by this template.
# If not set, that content will be created in the directory
destinationExplorerSubPathTemplate: "dev" # New property
# An optional group to add the group defined by groupTemplate to.
# The value of this property is the name of a group.
# It allows all the templated groups to belong to a common group for easier
# permission management.
groupParentGroupName: "Data Feed Reader" # New property
stroom.data.meta.dataFormats
An additional default value of JSON_LINES has been added for handling data in JSON Lines format, i.e. one complete JSON object per line.
This is a useful format for JSON log events.
Stroom-Proxy’s config.yml
No Stroom-Proxy specific configuration changes have been made.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrage command to just migrate the database and not fully boot Stroom.
See migrage command for more details.
Migration Scripts
There are no database migrations in v7.12.
2.5 - Change Log
New Features and Changes
-
Feature #5427 : Change the Data Feed Key authentication mechanism to support authentication by X509 certificate DN. Add a new allowed type of
CERTIFICATE_IDENTITYto.receive.enabledAuthenticationTypes. Rename property.receive.dataFeedKeysDirto.receive.dataFeedIdentitiesDirand change the structure of the files in it, all files will have to be replaced. Rename property.receive.dataFeedKeyOwnerMetaKeyto.receive.dataFeedOwnerMetaKey. Change the default value of.receive.dataFeedIdentitiesDirfromdata_feed_keystodata_feed_identities. -
Feature #5442 : Add more configuration options to
stroom.autoContentCreationto improve the explorer structure and permissions of the generated content. Add propertiesadditionalGroupParentGroupName,destinationExplorerSubPathTemplateandgroupParentGroupName. All have sensible defaults. -
Feature #5473 : Add
JSON_LINESto the base list of data formats in the.data.meta.dataFormatsproperty.
Bug Fixes
-
Bug #5532 : Relax Data Feed Identities validation so salt is optional.
-
Bug : Add missing directories (data_feed_identities, git_repo, lmdb_library, planb, reference_staging_data) as volumes in the docker image.
Code Refactor
No Code Refactor changes.
Dependency Changes
No Dependency changes.
3 - Version 7.11
3.1 - New Features
Integrated Pipeline Construction and Translation Development (Stepping)
Improvements have been made in how to construct pipelines and step through data with them. A pipeline can either be opened directly from the explorer tree or via the large Enter Stepping Mode button from the Data Preview pane of the data browser.
Clicking the Enter Stepping Mode button also allows the user to create a new pipeline (by clicking ) rather than opening an existing one if needed.
Stepping mode is used to develop/test a pipeline against some data and change the translation interactively. Once a pipeline is open, stepping mode can be toggled on and off by pressing the Enter Stepping Mode toggle button on the pipeline Structure tab. Opening a pipeline from the data browser button opens a pipeline and immediately enters Stepping Mode. In stepping mode the user will be able to select individual streams to step through from the meta list by clicking on the Source pipeline element.
When Stepping Mode is off the user can make any changes they wish to the pipeline structure or properties. Going back into stepping mode immediately applies any structure or property changes to the stepping process. The results of any changes made to pipeline structure and referenced docs can be viewed by pressing the Refresh Current Step button.
These improvements allow a user to change any aspect of a pipeline in one place and immediately see the impact applied to some test data without saving pipeline changes or navigating to another tab. The source data being tested in stepping mode can be changed at any time by selecting a different input stream on the Source tab. The user can change the filter on the Source pane to find different data to test.
When entering stepping mode from the Data Preview pane of the Data Browser Enter Stepping Mode button, only the data from that context is initially included in the filter. Users must change the filter to choose different data.
Ask Stroom AI
The new Ask Stroom AI feature provides information and AI insights into data contained in search result tables or any other tabular data in Stroom. Ask Stroom UI can be accessed from any table context menu or the toolbar wherever you see the Ask Stroom AI button.
One or more AI models must be configured to be able to use Ask Stroom AI. The models used must conform to the OpenAI API standard. Once configured users can ask questions such as “Summarise this table” and the Ask Stroom AI feature will provide AI insights for the provided data.
At present the Ask Stroom AI feature is a preview feature with many enhancements planned for subsequent versions of Stroom.
Dense Vector LLM (AI)
Dense vector index field support allows Stroom to perform approximation queries to find document containing similar words, similar meaning or sentiment, similar spelling plus errors etc.
Dense vector support leverages the AI model configuration provided for the Ask Stroom AI feature. Support is included for LLM embedded tokenisation and dense vector field storage in both Elastic and Lucene search indices. The Elastic and Lucene implementations are different and both are experimental in this release.
For the Lucene version you can now create a new field type in the UI and set it to be a dense vector field. The dense vector field has many configuration options to choose from such as the AI embedding model to use and limits on context size etc. Once an index is created with a dense vector field and the LLM has provided the tokens for the field data Stroom is able to search using the field.
When querying search terms are substituted for tokens using the LLM and then matched against the dense vector field. This mechanism allows for connections between words and tokens in both the data and the query to find documents approximately related to the search terms.
Plan B Histograms, Metrics, Sessions
Multiple improvements to Plan B to store:
- Histogram data, e.g. counts of things within specific time periods.
- Metric data, e.g. values at points in time, CPU Use %, Memory Use % etc.
- Session data, recording start and end periods for certain events, e.g. user uses application X between time A and B.
Trace Log Support In Plan B
Plan B can now store trace logs supplied via pipelines. There are new additions to the Plan B schema to capture trace log data so it can be supplied to a Plan B store.
Improved Annotations
Annotations have been improved to add several new features and improvements:
- Labels
- Collections
- Data Retention
- Access permissions
- Links between annotations
- Recording table row details
- Instant update of decorated tables after annotation edits
Pipeline Processing Dependencies and Delayed Execution
It is now possible to delay processing of event data until required reference data is present. For each dependency Stroom will delay processing until reference data arrives that is newer than the event data you want to process. Stroom needs to wait until reference data arrives that is newer than the event data it needs to process so that it knows it has definitely received effective reference data for the events.
Minimum Delay
Once reference data has been received and processed we can process the event data, however as reference data is cached we may want to add additional delay to the processing, this is achieved by setting a minimum delay. Even without any processing dependencies a minimum delay can be added so Stroom will wait the specified period of time before processing.
Maximum Delay
In some cases reference data might be late, and we might not want to wait too long before processing. In these cases the user can set a maximum delay so that processing will occur after the specified time delay even without the dependant data being present.
Git Integration
You can now create Git controlled folders in Stroom that will synchronise all child content with a Git repository. Git content can be pulled and pushed if the correct credentials have been provided via the new Credentials feature.
See Git Repo for details.
Content Store
Stroom now has a mechanism for providing standard content from one or more user defined content stores. Content stores are lists of specific content items described in files with Git repositories. The content store shows a list of items in the user interface that the user can choose to add to their Stroom instance, e.g. standard pipelines, schemas and visualisations.
See Content Store for details.
Credentials
Many features in Stroom require credentials to be provided to authenticate connections to external services, e.g. Git repositories, OpenAI APIs, HTTPS connections. The credentials feature provides a location to store and manage the secrets required to authenticate these services.
Credentials can manage:
- User name and passwords
- API keys and tokens
- SSH keys
- Key stores and trust stores in JKS and PKCS12 format.
See Credentials for details.
Smaller Changes
- Pipeline elements now have user friendly names and can be renamed without breaking pipelines.
- Main Stroom tabs can be reordered by clicking and dragging.
- Main Stroom tabs can be closed to the left or right of the selected tab via a context menu.
- The underline selection colour of a Stroom tab can be customised by a configuration property.
- Dashboards now allow individual panes to be maximised so that a table or visualisation can be viewed full screen.
- Table cells, rows, columns, selected rows and entire tables, now have numerous copy and export options.
New XSLT functions
A number of new XSLT functions have been added:
add-meta(String key, String value)- Add meta to be written to output destination.split-document(String doc, String segmentSize, String overlapSize)- Split a document for LLM tokenisation (experimental for Elastic dense vector indexing).
Dashboard & StroomQL Functions
A number of new dashboard and StroomQL functions have been added:
Create Annotation
Since annotation editing is now performed as a primary Stroom feature via a button and context menu on dashboard and query tables we no longer need to create or edit annotations via a hyperlink.
There are some remaining use cases where users want to create and initialise some annotation values based on some table row content.
The createAnnotation function can be used for this purpose and shows a hyperlink that will open the annotation edit screen pre-populated with the supplied values ready to create a new annotation.
The function takes the arguments:
createAnnotation(text, title, subject, status, assignedTo, comment, eventIdList)
Example:
createAnnotation('Create Annotation', 'My Annotation Title', ${SubjectField}, 'New', 'UserA', 'Look at this thing', '123:2,123444:3')
See createAnnotation for details.
HostAddress
Returns the host address (IP) for the given host string.
hostAddress(host)
Example
hostAddress('google.com')
> '142.251.29.102'
HostName
Returns the host name for the given host string.
hostName(host)
Example
hostName('142.251.29.102')
> 'google.com'
InRange
Returns true if the value is between lower and upper (inclusive). All parameters must be either numbers or ISO date strings.
- The input value to test
- The lower bound (inclusive)
- The upper bound (inclusive)
inRange(value, lower, upper)
Example
inRange(5, 2, 6)
> true
inRange(5, 5, 5)
> true
inRange(5, 6, 7)
> false
inRange(5, 3, 4)
> false
Stroom Proxy
API Key Verification
When you have more that one Stroom Proxy in a chain (e.g. Remote Stroom Proxy -> Local Stroom Proxy -> Stroom), the remote Stroom Proxy may receive requests from client using Api Keys API Key API Keys are a form of authentication token that are created within Stroom for use by Stroom-Proxy instances or other clients that want to use Stroom’s API. It is an encrypted string that contains details of the user and the expiration date of the token. Possession of a valid API Key for a user account means that you can do anything that the user can do in the user interface via the API.Click to see more details.... On its own, Stroom Proxy is unable to authenticate an API Key as they were created by Stroom. Instead it needs to make a request to the downstream Stroom Proxy to authenticate the API Key. This Stroom Proxy can in turn make a similar request to Stroom.
Each Stroom Proxy is now able to cache and persist the verified keys so that it can perform the authentication without having to always make requests downstream. As it can now persist verified keys in a hashed form, it is able to perform authentication even when it is unable to contact its downstream host.
The following configuration controls this caching:
proxyConfig:
downstreamHost:
# How long to cache verified keys for in memory
maxCachedKeyAge: "PT10M"
# How long keys will be persisted for on disk in case the downstream
# can't be connected to
maxPersistedKeyAge: "P30D"
# The delay to use after there is an error connecting to the downstream
noFetchIntervalAfterFailure: "PT30S"
# The hash algorithm used to hash persisted API keys.
persistedKeysHashAlgorithm: "SHA2_512"
3.2 - Preview Features (experimental)
Pathways
Trace logs describe the operation of applications and user interactions with applications. Pathways is designed to analyse trace logs over a period of time and remember patterns of activity. The intent is for Pathways to identify unexpected behaviour or changes to services once regular behaviour has been learnt.
Once trace logs have been added to a Plan B store it can be analysed with Pathways. Pathways examines trace logs and identifies unique paths in trace logs between methods or service calls, e.g. A -> B -> C. It also records alternate paths, e.g. A -> B -> D. Each path is remembered by Pathways and logged to an output stream. Whenever a new unique path is found the fact is logged so that it is easy to identify changes.
Pathways also records and monitors changes to span attributes within traces.
Pathways makes no judgement about the changes it logs, it is up to users to add analytic rules to fire against pathway logs.
Data Receipt Rules
Data Receipt Rules is a new feature that serves as an alternative to the existing feed status checking performed by Stroom Proxy and Stroom. It provides a much richer mechanism for controlling which received data streams are Received, Rejected or Dropped. It allows anyone with the Manage Data Receipt Rules Application Permission to create one or more rules to controls the receipt of data.
Data Receipt Rules can be accessed as follows:
Each rule is defined by a boolean expression (as used in Dashboards and Stream filtering) and the Action (Receive, Reject, Drop_ that will be performed if the data matches the rule. Rules are evaluated in ascending order by Rule Number. The action is taken from the first rule to match.
If no rules match then the data will be rejected by default, i.e. the rules are include rather than exclude filters.
If you want data to be received if no rules match then you can create a rule at the end of the list with an Action of Receive and no expression terms.
If a stream matches a rule that has an Accept action, it will still be subject to a check to see if the Feed actually exists.
This means that the rules do not need to contain an Accept rule to cover all of the Feeds in the system.
They only need to cover
The client will receive a 101 Feed is not defined error if it does not exist.

The screen operates in a similar way to Data Retention Rules in that rules can be moved up/down to change their importance, or enabled/disabled.
Fields
The fields available to use in the expression terms can be defined in the Fields tab. The terms will be evaluated against the stream’s meta data, i.e. a combination of the HTTP headers sent by the client and any that have been populated by Stroom Proxy or Stroom. This allows for the use of custom headers to aid in the filtering of data into Stroom.
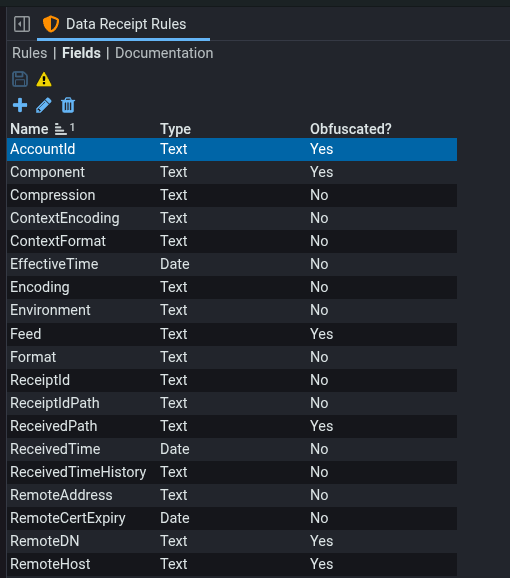
Dictionaries are supported for use with the in dictionary condition.
The contents of the dictionary and any of the dictionaries that it inherits will be included in the data fetched by Stroom Proxy.
Note
You cannot use the same dictionary for multiple fields if any one of those fields is obfuscated.
Should you need to use the same dictionary for an obfuscated and a non-obfuscated field, you can create one empty dictionary for each and make them both import from the same source dictionary.
Stroom Configuration
Data Receipt Rules are controlled by the following configuration:
appConfig:
receiptPolicy:
# List of fields whose values will be obfuscated when the rules
# are fetched by Stroom Proxy
obfuscatedFields:
- "AccountId"
- "AccountName"
- "Component"
# ... truncated
- "UploadUserId"
- "UploadUsername"
- "X-Forwarded-For"
# The hash algorithm used to hash obfuscated values, one of:
# * SHA3_256
# * SHA2_256
# * BCRYPT
# * ARGON_2
# * SHA2_512
obfuscationHashAlgorithm: "SHA2_512"
# The initial list of fields to bootstrap a Stroom environment.
# Changing this has no effect one an environment has been started up.
receiptRulesInitialFields:
AccountId: "Text"
Component: "Text"
Compression: "Text"
content-length: "Text"
# ... truncated
Type: "Text"
UploadUsername: "Text"
UploadUserId: "Text"
user-agent: "Text"
X-Forwarded-For: "Text"
receive:
# The action to take if there is a problem with the data receipt rules, e.g.
# Stroom Proxy has been unable to contact Stroom to fetch the rules.
fallbackReceiveAction: "RECEIVE"
# The data receipt checking mode, one of:
# * FEED_STATUS - Use the legacy Feed Status Check method
# * RECEIPT_POLICY - Use the new Data Receipt Rules
# * RECEIVE_ALL - Receive ALL data with no checks
# * DROP_ALL - Drop ALL data with no checks
# * REJECT_ALL - Reject ALL data with no checks
receiptCheckMode: "RECEIPT_POLICY"
Stroom Proxy Configuration
appConfig:
receiptPolicy:
# Only set this if you need to supply a non-standard full url
# By default Proxy will used the known path for the Data Receipt Rules resource
# combined with the host/port/scheme from the `downstreamHost` config property.
receiveDataRulesUrl: null
# The frequency that the rules will be fetched from the downstream Stroom instance.
syncFrequency: "PT1M"
# Identical configuration to Stroom as described above.
# Stroom and Stroom Proxy can use different `receiptCheckMode` values, but typically
# they will be the same.
receiptPolicy:
Stroom Proxy Rule Synchronisation
If Stroom Proxy is configured with receiptCheckMode set to RECEIPT_POLICY and has downstreamHost configured, then it will periodically send a request to Stroom to fetch the latest copy of the Data Receipt Rules.
If Stroom Proxy is unable to contact Stroom it will use the latest copy of the rules that it has.
Given that Stroom Proxy will only synchronise periodically, once a change is made to the rule set, there will be a delay before the new rules take effect.
Term Value Obfuscation
As a Stroom administrator you may not want the values used in the Data Receipt Rule expression terms to be visible when they are fetched by a remote Stroom Proxy (that may be maintained by another team).
It is therefore possible to obfuscate the values used for the expression terms for certain configured fields.
The fields that are obfuscated are controlled by the property stroom.receiptPolicy.obfuscatedFields.
For example, in the default configuration, Feed is an obfuscated field.
Thus a term like Feed != FEED_XYZ would have its value obfuscated when fetched by Stroom Proxy.
Stroom Proxy is able to similarly obfuscated meta data values for obfuscated fields in the same way to allow it to test the rule expression.
Warning
Due to the way obfuscation works, you are limited by the expression conditions that can be used, e.g.contains, >, < etc. are not allowed, but == and != are.
Stroom will tell you if you are using an unsupported condition for the field.
This prevents the Stroom Proxy administrator from being able to see the values used in the rules as they are not in plain text.
Each value is salted with its own unique salt then hashed.
The hash algorithm can be configured using stroom.receiptPolicy.obfuscationHashAlgorithm.
Note
Obfuscation is not encryption. The fetched data includes the salt values and given enough compute/time it would be possible to brute force the reversal of the hashing. Strong hashing algorithms such as BCrypt or Argon2 can mitigate against this but not remove the risk. If the rule values are too sensitive then you will have to let the Stroom Proxy accept the data and have Stroom do the full rule based checking.3.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.Stroom
Breaking changes relating to Stroom.
Import of Legacy Content
Stroom v7.11 is no longer able to import content that has been exported from a v5/v6 Stroom. Any such content will have to be imported into Stroom v7.10 or lower then exported for import into Stroom v7.11.
Elastic Configuration
The property stroom.elastic.retention.scrollSize has been removed.
See Upgrade Notes.
Stroom-Proxy
Breaking changes relating to Stroom Proxy.
Feed Status Check Configuration
Various properties have been removed from the proxyConfig.feedStatus configuration branch.
See Upgrade Notes.
Content Sync Configuration
The whole contentSync branch has been removed as it is no longer in use.
See Upgrade Notes.
Stroom & Stroom-Proxy
Breaking changes that are common to both Stroom and Stroom Proxy.
Receive Configuration
The property receiptPolicyUuid has been removed.
See Upgrade Notes.
3.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom/Stroom-Proxy instance.Upgrade Path
You can upgrade to v7.11.x from any v7.x release that is older than the version being upgraded to.
If you want to upgrade to v7.11.x from v5.x or v6.x we recommend you do the following:
- Upgrade v5.x to the latest patch release of v6.0.
- Upgrade v6.x to the latest patch release of v7.0.
- Upgrade v7.x to the latest patch release of v7.11.
Warning
v7.11 cannot migrate content in legacy formats, i.e. content created in v5/v6. You must therefore upgrade to v7.0.x first to migrate this content, before upgrading to v7.11.x.Java Version
Stroom v7.10 requires Java 25.
Warning
This is different to the java version required for Stroom v7.9 (Java 21).Ensure the Stroom and Stroom-Proxy hosts are running the latest patch release of Java v25.
Configuration File Changes
Common Configuration Changes
These changes are common to both Stroom and Stroom Proxy.
New receive Branch Properties
proxyConfig:
receive:
# The action to take if there is a problem with the data receipt rules, e.g.
# Stroom Proxy has been unable to contact Stroom to fetch the rules.
fallbackReceiveAction: "RECEIVE"
# If defined then states the maximum size of a request (uncompressed for gzip requests).
# Will return a 413 Content Too Long response code for any requests exceeding this
# value. If undefined then there is no limit to the size of the request.
# Defined as an IEC byte value, e.g. 10GiB, 10M, 23TB, 1024, etc.
maxRequestSize: null
# The data receipt checking mode, one of:
# * FEED_STATUS - Use the legacy Feed Status Check method
# * RECEIPT_POLICY - Use the new Data Receipt Rules
# * RECEIVE_ALL - Receive ALL data with no checks
# * DROP_ALL - Drop ALL data with no checks
# * REJECT_ALL - Reject ALL data with no checks
receiptCheckMode: "FEED_STATUS"
Removed Property proxyConfig.receive.receiptPolicyUuid
The property receiptPolicyUuid has been removed.
This was a for an unused feature so its removal does not require any migration.
If it is in your config file, simply remove it.
proxyConfig:
receive:
receiptPolicyUuid:
Stroom’s config.yml
New askStroomAi Branch
A new branch of configuration to configure Ask Stroom AI.
appCongfig:
askStroomAi:
chatMemory:
# How long a chat memory entry should exist before being expired
timeToLive:
time: 1
timeUnit: "HOURS"
# Number of tokens to keep in each chat memory store
tokenLimit: 30000
# The DocRef of the OpenAIModel document to use for Ask Stroom AI. e.g.
# modelRef:
# name: "My Model"
# type: "OpenAIModel"
# uuid: "8df699c0-2ce5-48bc-bb1a-e5d26bbd2175"
modelRef:
tableSummary:
# Maximum number of tokens to pass the AI service at a time
maximumBatchSize: 16384
# Maximum number of table result rows to pass to the AI when making requests
maximumTableInputRows: 100
New contentStore Branch
A new branch of configuration to configure one or more Content Stores.
appCongfig:
contentStore:
# A list of URLs to content store definition files
urls:
- "https://raw.githubusercontent.com/gchq/stroom-content/refs/heads/master/source/content-store.yml"
New credentials Branch
A new branch has been added for configuring the storage and caching of credentials for authenticating with other systems.
credentials:
# A standard configuration branch for a database connection.
# Only set this if you want the credentials tables to be located on a different database
# to the rest of Stroom.
db:
connection:
#...
connectionPool:
# ...
# The path to stored cached key stores.
keyStoreCachePath: "${stroom.home}/keystores"
Removed Elastic Property
The property stroom.elastic.retention.scrollSize has been removed.
appCongfig:
elastic:
retention: # <- REMOVED
scrollSize: 10000 # <- REMOVED
db Branch added to gitRepo
A standard database configuration branch has been added to GitRepo.
You should not need to set this unless you want the Git Repo table data to be stored on a different database.
appCongfig:
gitRepo:
db:
connection:
#...
connectionPool:
# ...
New receiptPolicy Branch
A new configuration branch for Data Receipt Rules.
receiptPolicy:
obfuscatedFields:
- "AccountId"
- "AccountName"
# ...
- "X-Forwarded-For"
obfuscationHashAlgorithm: "SHA2_512"
receiptRulesInitialFields:
AccountId: "Text"
Component: "Text"
# ...
user-agent: "Text"
X-Forwarded-For: "Text"
Stroom-Proxy’s config.yml
Removed contentSync
The whole contentSync branch has been removed as it is no longer in use.
proxyConfig:
contentSync: # <- REMOVED
apiKey: null # <- REMOVED
contentSyncEnabled: false # <- REMOVED
syncFrequency: "PT1M" # <- REMOVED
upstreamUrl: null # <- REMOVED
Added downstreamHost
A new downstreamHost branch has been added to configure the default downstream host details and authentication.
In a typical deployment, Stroom Proxy will receive data and forward it on to a downstream Stroom or Stroom Proxy.
There are a number of parts of Stroom Proxy that need to communicate with the downstream host, e.g. feed status checking, forwarding or rule fetching.
This allows for the host’s details and any authentication properties to be set in one place.
Typically you will only need to set the hostname and apiKey properties.
proxyConfig:
downstreamHost:
# The API key to use for authentication (unless OpenID Connect is being used)
apiKey: null
# Only set this if you need to use a non-standard path
apiKeyVerificationUrl: null
enabled: true
# The hostname of the downstream
hostname: null
# How long to cache verified keys for in memory
maxCachedKeyAge: "PT10M"
# How long keys will be persisted for on disk in case the downstream
# can't be connected to
maxPersistedKeyAge: "P30D"
# The delay to use after there is an error connecting to the downstream
noFetchIntervalAfterFailure: "PT30S"
# Only requird if you need a common path prefix in front of the path
# that Stroom / Stroom Proxy will use.
pathPrefix: null
# The hash algorithm used to hash persisted API keys.
persistedKeysHashAlgorithm: "SHA2_512"
# The port to connect to the downstream on
# If not set, will default to 80/443 depending on scheme.
port: null
# The scheme to connect to the downstream on
scheme: "https"
Remove various feedStatus properties
The following three properties have been removed from the feedStatus branch.
proxyConfig:
feedStatus:
apiKey: null # <- REMOVED
defaultStatus: "Receive" # <- REMOVED
enabled: true # <- REMOVED
The migration for these properties is as follows:
apiKey=>proxyConfig.downstreamHost.apiKeydefaultStatus=>proxyConfig.receive.fallbackReceiveActionReceive=>RECEIVEReject=>REJECTDrop=>DROP
enabled=>proxyConfig.receive.receiptCheckModetrue=>FEED_STATUSfalse=> (RECEIPT_POLICY,RECEIVE_ALL,DROP_ALL,REJECT_ALL)
feedStatus.url
The url property for feed status checking no longer needs to be set unless you need to use a non-standard URL.
The URL for feed status checking will now be derived from the properties in downstreamHost and the static path for the feed status resource.
Therefore in most cases, simply remove this property.
Also, previously, the value for this property was just a path. Now, if you set it, it should be a full URL including host and path.
proxyConfig:
feedStatus:
url:
New forwardHttpDestinations property
A new property has been added to enable/disable the liveness checking for HTTP destinations. Liveness checking will periodically check that the destination is live and if not, disable forwarding until the liveness check determines it to be live again. Liveness checking is enabled by default.
proxyConfig:
forwardHttpDestinations:
- .....
livenessCheckEnabled: true
New forwardFileDestinations property
A new property has been added to enable/disable the liveness checking for file destinations. Liveness checking will periodically check that the destination is live and if not, disable forwarding until the liveness check determines it to be live again. Liveness checking is enabled by default.
proxyConfig:
forwardFileDestinations:
- .....
livenessCheckEnabled: true
Changes to forwardHttpDestinations[*].forwardUrl property
This property no longer needs to be set unless you need to forward to a location that is different to that defined by downstreamHost.
The forward URL will now be derived from the properties in downstreamHost and the static path for the datafeed endpoint.
Therefore in most cases, simply remove this property.
Also, if you need to set this property, the value of the forwardUrl property has changed from being just a path to being a full URL including host and path.
proxyConfig:
forwardHttpDestinations:
- .....
forwardUrl:
Added receiptPolicy Branch
This configuration branch has been added to configure the Data Receipt Rules.
proxyConfig:
receiptPolicy:
# Stroom Proxy will use downstreamHost to derive the URL to connect to.
# Only set this if you need to use a non-standard URL.
receiveDataRulesUrl: null
# The frequency that Stroom Proxy will connect to the downstream host to obtain updated
# receipt policy rules.
syncFrequency: "PT1M"
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Pre-Migration Scripts
Warning
It is important that you run this pre-migration check or the database migration may fail.A previous database migration in v7.6 may have resulted in annotation_entry database records with no value in the entry_user_uuid column.
This is likely caused by annotations being linked to users that were no longer in Stroom when the 7.6 migration ran.
If that is the case then the v7.11 migration V07_11_00_001__annotation3.sql will fail.
To establish if you need you have any records in this state, run the following script against the Stroom database. This script can also be downloaded from v07_11_db_pre_migration_checks.sql on GitHub.
-- A set of SQL queries to run before migrating from v6 to v7
-- See https://gchq.github.io/stroom-docs/releases/v07.11/upgrade-notes/
--
-- Run with the mysql --table arg to get formatted output
-- e.g.
-- mysql --force --table -h"localhost" -P"3306" -u"stroomuser" -p"stroompassword1" stroom < v07_11_db_pre_migration_checks.sql > v07_11_db_pre_migration_checks.out 2>&1
-- docker exec -i stroom-all-dbs mysql --force --table -h"localhost" -P"3307" -u"stroomuser" -p"stroompassword1" stroom < v07_11_db_pre_migration_checks.sql > v07_11_db_pre_migration_checks.out 2>&1
\! echo 'Find annotation entries with no assigned user. No action required if this returns nothing.';
SELECT a.id, a.title, ae.id AS entry_id
FROM annotation a
INNER JOIN annotation_entry ae ON a.id = ae.fk_annotation_id
WHERE ae.entry_user_uuid IS NULL
OR ae.entry_user_uuid = '';
\! echo 'Listing all enabled Stroom users for reference';
SELECT uuid, name, display_name, full_name
FROM stroom_user su
WHERE is_group = false
AND enabled = true
ORDER by name;
\! echo 'Finished';
If the first SELECT statement returns any rows you will need to take remedial action.
In order to fix the missing data, you need the
UUID
UUID
A Universally Unique Identifier for uniquely identifying something. UUIDs are used as the identifier in Doc Refs. An example of a UUID is 4ffeb895-53c9-40d6-bf33-3ef025401ad3.Click to see more details... of a user that can be associated with the annotation entries.
You will need to establish the
UUID
UUID
A Universally Unique Identifier for uniquely identifying something. UUIDs are used as the identifier in Doc Refs. An example of a UUID is 4ffeb895-53c9-40d6-bf33-3ef025401ad3.Click to see more details... of a suitable user, for example a user that is an administrator.
The above script will also list all enabled users in your Stroom instance.
Select the uuid of an appropriate user and run the following
SQL
SQL
Structured Query Language (SQL). The language used in the MySQL database to query and manipulate the data.Click to see more details... statement, replacing <insert user UUID here> with the chosen UUID value.
UPDATE annotation_entry
SET entry_user_uuid = '<insert user UUID here>'
WHERE entry_user_uuid IS NULL
OR entry_user_uuid = '';
Once complete, re-run the v07_11_db_pre_migration_checks.sql script to verify that the column is now fully populated.
Then proceed with the 7.11 migration.
Migration Scripts
For information purposes only, the following are the database migrations that will be run when upgrading to 7.11.0 from the previous minor version.
Note, the legacy module will run first (if present) then the other module will run in no particular order.
Module stroom-annotation
Script V07_11_00_001__annotation3.sql
Path: stroom-annotation/stroom-annotation-impl-db/src/main/resources/stroom/annotation/impl/db/migration/V07_11_00_001__annotation3.sql
-- ------------------------------------------------------------------------
-- Copyright 2023 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP PROCEDURE IF EXISTS V07_11_00_001_annotation;
DELIMITER $$
CREATE PROCEDURE V07_11_00_001_annotation ()
BEGIN
DECLARE object_count integer;
--
-- Add entry parent id
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation_entry'
AND column_name = 'parent_id';
IF object_count = 0 THEN
ALTER TABLE `annotation_entry` ADD COLUMN `parent_id` bigint DEFAULT NULL;
END IF;
--
-- Add entry update time
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation_entry'
AND column_name = 'update_time_ms';
IF object_count = 0 THEN
ALTER TABLE `annotation_entry` ADD COLUMN `update_time_ms` bigint(20) NOT NULL;
-- Copy all entry times to update times.
SET @sql_str = CONCAT(
'UPDATE annotation_entry a ',
'SET a.update_time_ms = a.entry_time_ms');
PREPARE stmt FROM @sql_str;
EXECUTE stmt;
END IF;
--
-- Add entry update user
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation_entry'
AND column_name = 'update_user_uuid';
IF object_count = 0 THEN
ALTER TABLE `annotation_entry` ADD COLUMN `update_user_uuid` varchar(255) NOT NULL;
-- Copy all entry users to update users.
SET @sql_str = CONCAT(
'UPDATE annotation_entry a ',
'SET a.update_user_uuid = a.entry_user_uuid');
PREPARE stmt FROM @sql_str;
EXECUTE stmt;
END IF;
END $$
DELIMITER ;
CALL V07_11_00_001_annotation;
DROP PROCEDURE IF EXISTS V07_11_00_001_annotation;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Module stroom-credentials
Script V07_11_00_001__credential.sql
Path: stroom-credentials/stroom-credentials-impl-db/src/main/resources/stroom/credentials/impl/db/migration/V07_11_00_001__credential.sql
-- ------------------------------------------------------------------------
-- Copyright 2025 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
--
-- Create the credential tables
--
CREATE TABLE IF NOT EXISTS credential (
uuid varchar(255) NOT NULL,
create_time_ms bigint(20) NOT NULL,
create_user varchar(255) NOT NULL,
update_time_ms bigint(20) NOT NULL,
update_user varchar(255) NOT NULL,
name varchar(255) NOT NULL,
crendential_type varchar(255) NOT NULL,
key_store_type varchar(255) DEFAULT NULL,
expiry_time_ms bigint DEFAULT NULL,
secret_json json NOT NULL,
key_store longblob DEFAULT NULL,
PRIMARY KEY (uuid),
UNIQUE KEY name (name)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Module stroom-index
Script V07_11_00_001__index_field.sql
Path: stroom-index/stroom-index-impl-db/src/main/resources/stroom/index/impl/db/migration/V07_11_00_001__index_field.sql
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
ALTER TABLE index_field ADD COLUMN `dense_vector` json DEFAULT NULL;
SET SQL_NOTES=@OLD_SQL_NOTES;
Module stroom-processor
Script V07_11_00_001__processor_filter.sql
Path: stroom-processor/stroom-processor-impl-db/src/main/resources/stroom/processor/impl/db/migration/V07_11_00_001__processor_filter.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- --------------------------------------------------
DELIMITER $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS processor_run_sql_v1 $$
-- DO NOT change this without reading the header!
CREATE PROCEDURE processor_run_sql_v1 (
p_sql_stmt varchar(1000)
)
BEGIN
SET @sqlstmt = p_sql_stmt;
SELECT CONCAT('Running sql: ', @sqlstmt);
PREPARE stmt FROM @sqlstmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS processor_add_column_v1$$
-- DO NOT change this without reading the header!
CREATE PROCEDURE processor_add_column_v1 (
p_table_name varchar(64),
p_column_name varchar(64),
p_column_type_info varchar(64) -- e.g. 'varchar(255) default NULL'
)
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = p_table_name
AND column_name = p_column_name;
IF object_count = 0 THEN
CALL processor_run_sql_v1(CONCAT(
'alter table ', database(), '.', p_table_name,
' add column ', p_column_name, ' ', p_column_type_info));
ELSE
SELECT CONCAT(
'Column ',
p_column_name,
' already exists on table ',
database(),
'.',
p_table_name);
END IF;
END $$
-- idempotent
CALL processor_add_column_v1(
'processor_filter',
'export',
'TINYINT(1) NOT NULL DEFAULT 0')$$
-- vim: set shiftwidth=4 tabstop=4 expandtab:
3.5 - Change Log
New Features and Changes
-
Feature #5314 : Add
rowCount,fileType(EXCEL|CSV|TSV),fileNameto the templating context when generating email reports. -
Feature #5313 : Allow users to prevent empty reports from being sent on a per report basis.
-
Feature : Add enabled/disabled styling to table rows in the Report screens.
-
Feature : Add column header tool tips to tables in the Report screens.
-
Feature : Change the Report > Notifications Max column to be right aligned.
-
Feature : Add red/green styling to the Report > Notifications Status column (Complete/Error).
-
Feature #5282 : Processor task creation now supports feed dependencies to delay processing until reference data is available.
-
Feature #5256 : Add option to omit documentation from rule detection.
-
Feature #5309 : Add long support to pathway values.
-
Feature #5303 : Make AI HTTP connection configurable.
-
Feature #5303 : Make AI HTTP SSL certificate stores configurable.
-
Feature #5303 : Add KNN dense vector support to Lucene indexes.
-
Feature #5303 : Pass only visible columns to the Ask Stroom AI service.
-
Feature #4123 : New pipeline stepping mode.
-
Feature #5290 : Plan B trace store now requires data to conform to Plan B trace schema.
-
Feature : Make the Quick Filter Help button hide the help popup if it is visible.
-
Feature : Add the same Quick Filter help popup as used on the explorer QF to the QFs on Dashboard table columns, Query help and Expression Term editors.
-
Feature #5263 : Add copy for selected rows.
-
Remove default value for
feedStatus.urlin the proxy config yaml as downstream host should now be used instead. -
Feature #5192 : Support Elasticsearch kNN search on dense_vector fields.
-
Feature #5124 : Change cluster lock
tryLockto use the database record locks rather than the inter-node lock handler. -
Feature #656 : Allow table filters to use dictionaries.
-
Feature #672 : Dashboards will only auto refresh when selected.
-
Feature #2029 : Add OS memory stats to the node status stats.
-
Feature #3799 : Search for tags in Find In Content.
-
Feature #3335 : Preserve escape chars not preceding delimiters.
-
Feature #1429 : Protect against large file ingests.
-
Feature #4121 : Add rename option for pipeline elements.
-
Feature #2374 : Add pipeline element descriptions.
-
Feature #4099 : Add InRange function.
-
Feature #2374 : Add description is now editable for pipeline elements.
-
Feature #268 : Add not contains and not exists filters to pipeline stepping.
-
Feature #844 : Add functions for hostname and hostaddress.
-
Feature #4579 : Add table name/id to conditional formatting exceptions.
-
Feature #4124 : Show severity of search error messages.
-
Feature #4369 : Add new rerun scheduled execution icon.
-
Feature #3207 : Add maxStringFieldLength table setting.
-
Feature #1249 : Dashboard links can open in the same tab.
-
Feature #1304 : Copy dashboard components between dashboards.
-
Feature #2145 : New add-meta xslt function.
-
Feature #370 : Perform schema validation on save.
-
Feature #397 : Copy user permissions.
-
Feature #5088 : Add table column filter dashboard component.
-
Feature #2571 : Show Tasks for processor filter.
-
Feature #4177 : Add stream id links.
-
Feature #2279 : Drag and drop tabs.
-
Feature #2584 : Close all tabs to right/left.
-
Feature #5013 : Add row data to annotations.
-
Feature #3049 : Check for full/inactive/closed index volumes.
-
Feature #4070 : Show column information on hover tip.
-
Feature #3815 : Add selected tab colour property.
-
Feature #4790 : Add copy option for property names.
-
Feature #4121 : Add rename option for pipeline elements.
-
Feature #2823 : Add
autoImportservlet to simplify importing content. -
Feature #5013 : Add data to existing annotations.
-
Feature #5013 : Add links to other annotations and allow comments to make references to events and other annotations.
-
Feature #2374 : Add pipeline element descriptions.
-
Feature #2374 : Add description is now editable for pipeline elements.
-
Feature #4048 : Add query csv API.
-
Feature: Change the proxy config properties
forwardUrl,livenessCheckUrl,apiKeyVerificationUrlandfeedStatusUrlto be empty by default and to allow them to be populated with either just a path or a full URL.downstreamHostconfig will be used to provide the host details if these properties are empty or only contain a path. Added the propertylivenessCheckEnabledtoforwardHttpDestinationsto control whether the forward destination liveness is checked (defaults to true). -
Feature #5028 : Add build info metrics
buildVersion,buildDateandupTime. -
Add admin port servlets for Prometheus to scrape metrics from stroom and proxy. Servlet is available as
http://host:<admin port>/(stroom|proxy)Admin/prometheusMetrics. -
Feature #4735 : Add expand/collapse to result tables.
-
Feature #5013 : Allow annotation status update without requery.
-
Feature #259 : Maximise dashboard panes.
-
Feature #3874 : Add copy context menu to tables.
-
Feature : Add the Receive Data Rules screen to the Administration menu which requires the
Manage Data Receipt Rulesapp permission. Add the following new config properties to thereceivebranch:obfuscatedFields,obfuscationHashAlgorithm,receiptCheckModeandreceiptRulesInitialFields. Remove the propertyreceiptPolicyUuid. Add the proxy config propertycontentSync.receiveDataRulesUrl. -
Feature: The proxy config property
feedStatus.enabledhas been replaced byreceive.receiptCheckModewhich takes valuesFEED_STATUS,RECEIPT_POLICYorNONE. -
Feature: In the proxy config, the named Jersey clients CONTENT_SYNC and FEED_STATUS have been removed and replaced with DOWNSTREAM.
Bug Fixes
-
Bug #5391 : Fix folder DocRef NPE.
-
Bug #5392 : Fix PlanB segfault.
-
Bug #5300 : Fix path
millisparameter. -
Bug : Fix Reports not respecting the start date during execution. It was executing from the last tracker time rather than from the start date, if the start date is later.
-
Bug #5384 : Improvements to annotations database code.
-
Bug #5360 : Fix NPE when annotation data retention fires change events.
-
Bug #5361 : Fix invalid SQL error when annotation data retention runs.
-
Bug : Fix ‘Data source already in use’ errors when using annotations.
-
Bug : Add missing cluster lock protection for annotation data retention job.
-
Bug #5359 : Fix ‘Data source already in use’ errors in the Data Delete job.
-
Bug #5185 : Fix dashboard maximise NPE.
-
Bug #5370 : Hide rule notification doc checkbox on reports as it is not applicable.
-
Bug #5234 : Fix spaces in
createAnnotation()function link text. -
Bug #5355 : Fix HttpClient being closed by cache while in use.
-
Bug #5303 : Add debug to index dense vector retrieval.
-
Bug #5344 : Fix credential manager UI.
-
Bug #5342 : Fix issue querying Plan B shards where some stores have been deleted.
-
Bug #5351 : Make SSH key and known host configuration clearer.
-
Bug #5353 : Fix keystore config issue.
-
Bug #5339 : Fix NPE thrown when adding vises to dashboards.
-
Bug #5337 : Fix analytic doc serialisation.
-
Bug #4124 : Fix NodeResultSerialiser and add node name to errors.
-
Bug #5317 : Pathways now load current state to not endlessly output mutations.
-
Bug : Fix build issue causing Stroom to not boot.
-
Bug #5304 : Fix error when unzipping the stroom-app-all jar file. This problem was also leading to AV scan alerts.
-
Bug : Fix Files list on Stream Info pane so that you can copy each file path individually.
-
Bug #5297 : Fix missing execute permissions and incorrect file dates in stroom and stroom-proxy distribution ZIP files.
-
Bug #5259 : Fix PlanB Val.toString() NPE.
-
Bug #5291 : Fix explorer item sort order.
-
Bug #5152 : Fix position of the Clear icon on the Quick Filter.
-
Bug #5293 : Fix pipeline element type and name display.
-
Bug #5254 : Fix document NPE.
-
Bug #5218 : When
autoContentCreationis enabled, don’t attempt to find a content template if theFeedheader has been provided and the feed exists. -
Bug #5244 : Fix proxy throwing an error when attempting to do a feed status check.
-
Bug #5149 : Fix context menus not appearing on dashboard tables.
-
Bug #4614 : Fix StroomQL highlight.
-
Bug #5064 : Fix ref data store discovery.
-
Bug #5022 : Fix weird spinner behaviour.
-
Bug : Fix NPE when proxy tries to fetch the receipt rules from downstream.
Code Refactor
- Refactor : Remove static imports except in test classes.
Dependency Changes
-
Dependency : Uplift base docker images to eclipse-temurin:25.0.1_8-jdk-alpine-3.23.
-
Dependency : Uplift dependency com.hubspot.jinjava:jinjava from 2.7.2 to 2.8.2.
-
Dependency : Uplift dependency swagger-* from 2.2.38 to 2.2.41.
-
Dependency : Uplift com.sun.xml.bind:jaxb-impl from 4.0.5 to 4.0.6.
-
Dependency : Uplift lanchain4j dependencies from 1.8.0-beta15 to 1.10.0-beta18 and 1.8.0 to 1.10.0.
-
Dependency : Uplift Gradle to v9.2.1.
-
Dependency : Uplift docker image JDK to
eclipse-temurin:25_36-jdk-alpine-3.22. -
Dependency #5257 : Upgrade Lucene to 10.3.1.
-
Dependency : Uplift dependency java-jwt 4.4.0 => 4.5.0.
-
Dependency : Uplift org.apache.commons:commons-csv from 1.10.0 to 1.14.1.
-
Dependency : Uplift dependency org.apache.commons:commons-pool2 from 2.12.0 to 2.12.1.
-
Dependency : Bumps org.quartz-scheduler:quartz from 2.5.0-rc1 to 2.5.1.
-
Dependency : Bumps org.eclipse.transformer:org.eclipse.transformer.cli from 0.5.0 to 1.0.0.
-
Dependency : Bumps jooq from 3.20.5 to 3.20.8.
-
Dependency : Bumps com.mysql:mysql-connector-j from 9.2.0 to 9.4.0.
-
Dependency : Bumps flyway from 11.9.1 to 11.14.0.
4 - Version 7.10
4.1 - New Features
Dashboard & StroomQL Functions
ceilingTime(..) & floorTime(...) & roundTime(...)
Three new functions similar to the existing ceilingXXX and floorXXX functions, except that an arbitrary duration can be used.
For example, floorTime($time, 'PT5m') will floor the time to the latest time that is divisible by 5 minutes.
case(...)
A case function has been added for performing simple if...else if....else if.....end type logic.
The function takes the arguments:
case(input, test1, result1, testN, resultN, otherwise)
This is equivalent to
if (input == test1) {
return result1
} else if (input == testN) {
return resultN
} else {
return otherwise
}
See case for details.
formatIECByteSize(...)
A new function for converting an integer amount of bytes into an appropriate byte size unit, e.g. 1024 bytes becomes 1K.
International Electrotechnical Commission (IEC) units with a base of 1024 rather than 1000 are used.
The function has three forms:
formatIECByteSize(bytes)
formatIECByteSize(bytes, omitTrailingZeros)
formatIECByteSize(bytes, omitTrailingZeros, significantFigures)
formatMetricByteSize(...)
A new function for converting an integer amount of bytes into an appropriate byte size unit, e.g. 1000 bytes becomes 1K.
Metric units with a base of 1000 rather than 1024 are used.
The function has three forms:
formatMetricByteSize(bytes)
formatMetricByteSize(bytes, omitTrailingZeros)
formatMetricByteSize(bytes, omitTrailingZeros, significantFigures)
decode(...)
The existing decode(...) function has been changed so that you can use any capture groups in the regular expression patterns in the result arguments.
For example:
decode('TestString123','Test(.....)(123)','$1-$2','Nothing')
Which would output String-123.
data(...)
The existing data(...) function has been changed so that you can display the stream info and metadata instead of the stream data by setting the viewType argument to a value of info.
For example:
data('View Cooked', ${StreamId}, 1, ${eventId}, null(), null(), null(), null(), 'info')
isWeekend(..)
Returns whether a date and time is part of the weekend or not.
For example:
isWeekend('2026-02-04T12:45:11.000Z') returns false
isWeekend('2026-02-01T12:45:11.000Z') returns true
Dashboard Embedded Queries
When creating an Embedded Query Dashboard pane, it is now possible to embed a copy of an existing query rather than embedding a reference to one. This decouples the Dashboard from the original Query so the original Query can be changed without impacting the Dashboard.
The embedded Query can be edited via the menu on the Dashboard pane.
Stroom XSLT Functions
parse-dateTime(...)
A parse-dateTime function has been added with the following overloads:
parse-dateTime(ISO8601 string)
parse-dateTime(string, pattern)
parse-dateTime(string, pattern, timezone)
This function will either parse a date/time string in ISO 8601 ISO 8601 This is an international standard for representing dates, times and durations. By default Stroom displays date/times in ISO 8601.Click to see more details... standard date/time format or in a custom date/time format using the supplied pattern and optional time zone.
For details of the pattern syntax see Custom Date Formats.
All forms of the function return an xs:dateTime value for use by standard XSLT/XPath functions that can consume an xs:dateTime value.
format-dateTime(...)
A format-dateTime function has been added with the following overloads:
format-dateTime(DateTimeValue)
format-dateTime(DateTimeValue, pattern)
format-dateTime(DateTimeValue, pattern, timezone)
All three variants take an xs:dateTime value as the first argument.
If only one argument is supplied, the function will output the date/time as a standard
ISO 8601
ISO 8601
This is an international standard for representing dates, times and durations. By default Stroom displays date/times in ISO 8601.Click to see more details... format xs:string.
If two or more arguments are supplied then it will output the date/time formatted using the specified pattern and optionally using the specified timezone.
If no timezone is supplied, the date/time is assumed to be in
Coordinated Universal Time (UTC)
Coordinated Universal Time (UTC)
Coordinated Universal Time (UTC), also known as Zulu time, is the international standard by which the world regulates clocks and time. It is essentially a successor to Greenwich Mean Time (GMT). UTC has the time zone offset of +00:00 and does not change for daylight saving. All international time zones are relative to UTC.Click to see more details....
Meta Functions
The following functions have been added for obtaining meta-data relating to the stream being processed or specified streams.
manifest()- Returns manifest attributes for current streammanifest-for-id(streamId)- Returns manifest attributes for specified streammeta-stream()- Returns meta stream for current streammeta-stream-for-id(streamId, partNo)- Returns meta stream for specified stream and part noparent-id()- Gets parent ID for current streamparent-for-id(streamId)- Get parent Stream ID for specified stream
Content Templates
When creating a content template of type INHERIT_PIPELINE it is now possible to tick a box so that any dependencies of the pipeline being inherited from (e.g. Data Splitter TextConverter documents or XsltFilter XSLT documents) will be copied as siblings of the generated Pipeline .
This allows the Data Splitter or XSLT to be refined/populated for the new content.
Index Shards Searchable
The IndexShards
Searchable
Searchable
A Searchable is the term given the special searchable data sources that appear at the root of the explorer tree picker when selecting a data source. These data sources are special internal data sources that are not user managed content, unlike an Index. They provide the means to search various aspects of Stroom’s internals, such as the Meta Store or Processor Tasks.Click to see more details... has been changed to add the fields Shard Id and Index Version to the list of available fields.
Shard Id- This is the ID of the shard within the index.Index Version- This is the Lucene version that this index was created with. Currently Stroom supports two different versions of the Lucene search index.
Plan B Changes
Plan B has evolved in 7.10 as a state store capable of storing the following types of state data:
- State - For a given key provide an unchanging state value.
- Temporal State - For a given key provide a state value valid at a specific point in time (similar to reference data).
- Ranged State - For a given numeric key within a key range provide an unchanging state value.
- Temporal Ranged State - For a given numeric key within a key range provide a state value valid at a specific point in time (similar to reference data for ranges).
- Session - Record session start and end times, e.g. maintain sessions for each application used by a specific user.
- Metrics - Record values at points in time, e.g. CPU use %.
- Histograms - Record counts over time, e.g. number of records per minute, hour etc.
Although still somewhat experimental, Plan B has undergone significant change in 7.10 following feedback from the previous experimental release. The data structure has changed significantly to reduce data store sizes. All previous Plan B LMDB instances must be deleted before this new version can be used.
In addition to data structure changes the following features are now available:
- Additional Plan B store types for histograms and metrics.
- Advanced Plan B storage schema settings for specific use cases to improve storage efficiency and performance.
- Better data retention options allowing for retention based on insert time.
- Remote query settings for
get()andlookup()requests to avoid the need for local snapshots. - Plan B shards can now be queried as a Searchable Searchable A Searchable is the term given the special searchable data sources that appear at the root of the explorer tree picker when selecting a data source. These data sources are special internal data sources that are not user managed content, unlike an Index. They provide the means to search various aspects of Stroom’s internals, such as the Meta Store or Processor Tasks.Click to see more details... data source to discover stored data and information.
- Writes can now be synchronised if needed to ensure data presence before query. This option impacts data processing performance.
Improved Dashboard Context
Dashboards now maintain a global context that is available to all dashboard components. The context keeps track of the selection state of each component plus dashboard parameters and time range setting. Context changes can be handled by certain components such as queries and tables by adding selection handlers. Handlers allow components to respond to context changes, e.g. by filtering a table based on a selection in another table.
Annotation Changes
Annotations have been improved in 7.10 and more improvements will be available in 7.11.
For 7.10 the following changes have been made:
- The annotation edit presenter has been improved so that the layout is clearer.
- Annotations now have fine-grained permissions for visibility and edit.
- Creating annotations can now be performed on multiple events just by selecting the events and clicking the annotate button.
- Users can define custom annotation states.
- Custom labels and collections can defined and added to annotations.
- All states and labels have visibility permissions.
- An annotations screen is now available for easier annotation browsing.
- Annotations can now have retention periods.
Open ID Connect Authentication
Various minor changes to the way Open ID Connect authentication is performed.
Audience Validation
Replace the property stroom.security.authentication.openid.validateAudience with stroom.security.authentication.openid.allowedAudiences (defaults to empty) and stroom.security.authentication.openid.audienceClaimRequired (defaults to false).
If the IDP is known to provide the aud claim (often populated with the clientId) then set allowedAudiences to contain that value and set audienceClaimRequired to true.
User Full Name
Add the config prop stroom.security.authentication.openId.fullNameClaimTemplate to allow the user’s full name to be formed from a template containing a mixture of static text and claim variables, e.g. ${firstName} ${lastName}.
Unknown variables are replaced with an empty string. Default is ${name}.
This provides full control over the source of the user’s full name in stroom and allows it to be formed from multiple claims within the authentication token.
AWS Integration
Change template syntax of openid.publicKeyUriPattern property from positional variables ({}) to named variables (${awsRegion}).
Default value has changed to https://public-keys.auth.elb.${awsRegion}.amazonaws.com/${keyId}.
If this property has been explicitly set in the config.yml or Properties screen, its value will need to be changed to use named variables instead.
Certificate DN Format
Add new property .receive.x509CertificateDnFormat to stroom and proxy to allow extraction of CNs from DNs in legacy OPEN_SSL format.
The new property defaults to LDAP, which means no change to behaviour if left as is.
Stroom-Proxy ZIP File Ingest
To make it easier to deal with ZIP files that Stroom-Proxy has failed to forward, Stroom-Proxy now has a ZIP file ingest mechanism.
This mechanism can also be used as an additional means of passing data into Stroom-Proxy (instead of /datafeed).
This is controlled by the following new configuration branch (default values shown):
proxyConfig:
dirScanner:
# The directories to scan for ZIP files. Scanned in this order.
dirs:
- "zip_file_ingest"
# If false, no directory scanning is performed.
enabled: true
# The directory to move unknown/failed files to.
failureDir: "zip_file_ingest_failed"
# The frequency that the directories are scanned.
scanFrequency: "PT1M"
A typical case scenario is that some data has failed to send to Stroom and the retry age has been reached so the ZIP has been moved to the forward failure directory:
Contents of data/50_forwarding/downstream/
./03_failure/20251014/BAD_FEED/0/001/proxy.zip
./03_failure/20251014/BAD_FEED/0/001/proxy.meta
./03_failure/20251014/BAD_FEED/0/001/error.log
If you wish to re-send this ZIP you can do the following:
This will move the 001 directory into zip_file_ingest/, renaming it to a unique
UUID
UUID
A Universally Unique Identifier for uniquely identifying something. UUIDs are used as the identifier in Doc Refs. An example of a UUID is 4ffeb895-53c9-40d6-bf33-3ef025401ad3.Click to see more details... to ensure it doesn’t clash with any existing files/directories.
The name of this directory in the ingest directory has no bearing on processing, other than the order in which directories are scanned.
On the next scan, Stroom-Proxy will discover the proxy.zip file.
It will check for the presence of any of the optional associated files (i.e. proxy.meta and error.log).
The entries in the .meta file will be consumed.
The error.log file will be deleted following successful ingest.
Stroom-Proxy will scan into all sub-directories within the ingest directory, regardless of depth.
The .meta sidecar file is optional, but if provided will be used to provide meta values equivalent to HTTP headers when sending to /datafeed.
For a .meta file to be consumed, it must have the same base-name as the ZIP file, e.g. data.zip and data.meta, and be in the same directory as the ZIP file.
Warning
Stroom-Proxy may be scanning at the same time as you are moving files in to the zip_file_ingest directory.
Therefore, it is important that if you are supplying sidecar files that you move a parent directory rather than the files themselves (as is shown in the above mv example).
This will ensure that the move happens atomically, so all files will be visible to the scanner.
4.2 - Preview Features (experimental)
There are no new preview features in v7.10.
4.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.Stroom
No Stroom specific breaking changes in v7.10.
Stroom-Proxy
No Stroom-Proxy specific breaking changes in v7.10.
Stroom & Stroom-Proxy
Open ID Connect Configuration
The property stroom.security.authentication.openid.validateAudience has been removed.
See Upgrade Notes for details.
AWS Open ID Connect Configuration
If you use AWS for OIDC authentication and you have configured the property stroom.security.authentication.openId.publicKeyUriPattern then you will need to change its value.
See Upgrade Notes for details.
4.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom/Stroom-Proxy instance.Upgrade Path
You can upgrade to v7.10.x from any v7.x release that is older than the version being upgraded to.
If you want to upgrade to v7.10.x from v5.x or v6.x we recommend you do the following:
- Upgrade v5.x to the latest patch release of v6.0.
- Upgrade v6.x to the latest patch release of v7.0.
- Upgrade v7.x to the latest patch release of v7.10.
Warning
v7.10 cannot migrate content in legacy formats, i.e. content created in v5/v6. You must therefore upgrade to v7.0.x first to migrate this content, before upgrading to v7.10.x.Java Version
Stroom v7.10 requires Java 21. This is the same java version as Stroom v7.9. Ensure the Stroom and Stroom-Proxy hosts are running the latest patch release of Java v21.
Configuration File Changes
Stroom’s config.yml
Git Repo
A new branch has been added to the config for configuring the directory used to store the local git repositories.
appConfig:
gitRepo:
localDir: "git_repo"
X509 Certificate Extraction
A new property x509CertificateDnFormat has been added to define the format of the certificate Distinguished Name (DN).
Valid values are LDAP which is , delimited or OPEN_SSL which is / delimited.
The default is LDAP.
appConfig:
receive:
x509CertificateDnFormat: "LDAP"
Open ID Connect Authentication
The property stroom.security.authentication.openid.validateAudience has been replaced by two new properties for controlling validation of the aud claim.
The allowedAudiences property allows you to supply a list of valid values for the aud claim.
If this list is not empty then if the aud claim is present, Stroom will ensure that it matches one of these values.
If audienceClaimRequired is set to true then Stroom will fail authentication if the aud claim is not present.
The new fullNameClaimTemplate lets you define a template for extracting the user’s full name from the claims in a token.
For example, the template could be ${firstname} ${lastName} if those two claims are available.
If the named claim is not present then the placeholder will be replaced by an empty string.
The template syntax for publicKeyUriPattern has changed from positional place holders (e.g. https://public-keys.auth.elb.{}.amazonaws.com/{}) to named place holders (e.g. https://public-keys.auth.elb.${awsRegion}.amazonaws.com/${keyId}).
This make it more flexible.
appConfig:
security:
authentication:
openId:
allowedAudiences: []
audienceClaimRequired: false
fullNameClaimTemplate: "${name}"
publicKeyUriPattern: "https://public-keys.auth.elb.${awsRegion}.amazonaws.com/${keyId}"
Stroom-Proxy’s config.yml
HTTP Forward Destinations
The property forwardHeadersAdditionalAllowSet has been added to the forwardHttpDestinations branch.
It is a set of case-insensitive HTTP header keys.
When forwarding data to a downstream Stroom/Stroom-Proxy, Stroom-Proxy will set the following headers using value from the Meta associated with the data accountId, accountName, classification, component, contextEncoding, contextFormat, encoding, environment, feed, format, guid, schema, schemaVersion, system, type.
If any additional HTTP headers need to be set then they should be added to this list.
proxyConfig:
forwardHttpDestinations:
- forwardHeadersAdditionalAllowSet: []
X509 Certificate Extraction
The changes described above in Stroom - X509 Certificate Extraction also apply to stroom-proxy.
Open ID Connect Authentication
The changes described above in Stroom - Open ID Connect Authentication also apply to stroom-proxy.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Migration Scripts
For information purposes only, the following are the database migrations that will be run when upgrading to 7.10.0 from the previous minor version.
Note, the legacy module will run first (if present) then the other module will run in no particular order.
Module stroom-index
Script V07_10_00_001__index_field.sql
Path: stroom-index/stroom-index-impl-db/src/main/resources/stroom/index/impl/db/migration/V07_10_00_001__index_field.sql
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
ALTER TABLE index_field CHANGE COLUMN name name varchar(512) NOT NULL;
SET SQL_NOTES=@OLD_SQL_NOTES;
Module stroom-processor
Script V07_10_00_999__processor_filter_data.java
Path: stroom-processor/stroom-processor-impl-db/src/main/java/stroom/processor/impl/db/migration/V07_10_00_999__processor_filter_data.java
It is not possible to display the content here. The file can be viewed on : GitHub
Module stroom-security
Script V07_10_00_005__trim_user_identities.sql
Path: stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_10_00_005__trim_user_identities.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- --------------------------------------------------
-- Trim existing user identity values so they are consistent with the app
-- that now trims these values.
-- Idempotent.
update stroom_user
set name = trim(name)
where name is not null
and name != trim(name);
update stroom_user
set display_name = trim(display_name)
where display_name is not null
and display_name != trim(display_name);
update stroom_user
set full_name = trim(full_name)
where full_name is not null
and full_name != trim(full_name);
-- --------------------------------------------------
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set tabstop=4 shiftwidth=4 expandtab:
4.5 - Change Log
Features and Changes
-
Change the resource store to not rely on sessions. Resources are now linked to a user.
-
Add
ReceiptIdto the INFO message on data receipt. -
Issue #5047 : Replace the property
stroom.security.authentication.openid.validateAudiencewithstroom.security.authentication.openid.allowedAudiences(defaults to empty) andstroom.security.authentication.openid.audienceClaimRequired(defaults to false). If the IDP is known to provide theaudclaim (often populated with theclientId) then setallowedAudiencesto contain that value and setaudienceClaimRequiredtotrue. -
Issue #5068 : Add the config prop
stroom.security.authentication.openId.fullNameClaimTemplateto allow the user’s full name to be formed from a template containing a mixture of static text and claim variables, e.g.${firstName} ${lastName}. Unknown variables are replaced with an empty string. Default is${name}. -
Issue #5066 : Change template syntax of
openid.publicKeyUriPatternprop from positional variables ({}) to named variables (${awsRegion}). Default value has changed tohttps://public-keys.auth.elb.${awsRegion}.amazonaws.com/${keyId}. If this prop has been explicitly set, its value will need to be changed to named variables. -
Issue #5030 : Add new property
.receive.x509CertificateDnFormatto stroom and proxy to allow extraction of CNs from DNs in legacyOPEN_SSLformat. The new property defaults toLDAP, which means no change to behaviour if left as is. -
Issue #5007 : Add ceilingTime() and floorTime().
-
Issue #3083 : Allow data() table function to show the Info pane.
-
Issue #4965 : Add dashboard screen to show current selection parameters.
-
Issue #4496 : Add parse-dateTime xslt function.
-
Issue #4496 : Add format-dateTime xslt function.
-
Issue #4969 : Add a checkbox to Content Templates edit screen to make it copy (and re-map) any xslt/textConverter docs in the inherited pipeline.
-
Issue #4726 : Get meta for parent stream.
-
Issue #4900 : Add histogram and metric stores to Plan B.
-
Issue #3861 : Add Shard Id, Index Version to Index Shards searchable.
-
Issue #4112 : Allow use of Capture groups in the decode() function result.
-
Issue #3955 : Add case expression function.
-
Issue #4484 : Change selection handling to use fully qualified keys.
-
Issue #4742 : Allow embedded queries to be copies rather than references.
-
Issue #4894 : Plan B query without snapshots.
-
Issue #4896 : Plan B option to synchronise writes.
-
Issue #4720 : Add Plan B shards data source.
-
Issue #4919 : Add functions to format byte size strings.
-
Issue #4901 : Add advanced schema selection to Plan B to improve performance and reduce storage requirements.
Bug Fixes
-
Issue #5027 : Allow users to choose run as user for processing.
-
Issue #5137 : Fix how proxy adds HTTP headers when sending downstream. It now only adds received meta entries to the headers if they are on an allow list. This list is made up of a hard coded base list
accountId, accountName, classification, component, contextEncoding, contextFormat, encoding, environment, feed, format, guid, schema, schemaVersion, system, typeand is supplemented by the new config propertyforwardHeadersAdditionalAllowSetin theforwardHttpDestinationsitems. -
Issue #5135 : Fix proxy multi part gzip handling.
-
Uplift JDK to 21.0.8_9 in docker images and sdkmanrc.
-
Issue #5130 : Fix raw size meta bug.
-
Issue #5132 : Fix missing session when AWS ALB does the code flow.
-
Fix the OpenID code flow to stop the session being lost after redirection back to the initiating URL.
-
Issue #5101 : Fix select-all filtering when doing a reprocess of everything in a folder. It no longer tries to re-process deleted items streams.
-
Issue #5086 : Improve stream error handling.
-
Issue #5114 : Improve handling of loss of connection to IDP.
-
Change the way security filter decides whether to authenticate or not, e.g. how it determines what is a static resource that does not need authentication.
-
Issue #5115 : Use correct header during proxy forward requests.
-
Issue #5121 : Proxy aggregation now keeps only common headers in aggregated data.
-
Fix exception handling of DistributedTaskFetcher so it will restart after failure.
-
Issue #5127 : Maintain case for proxy meta attributes when logging.
-
Issue #5091 : Stop reference data loads failing if there are no entries in the stream.
-
Issue #5095 : Lock the cluster to perform pipeline migration to prevent other nodes clashing.
-
Issue #5099 : Fix Plan B session key serialisation.
-
Issue #5090 : Fix Plan B getVal() serialisation.
-
Issue #5106 : Fix ref loads with XML values where the
<value>element name is not in lower case. -
Issue #5042 : Allow the import of processor filters when the existing processor filter is in a logically deleted state. Add validation to the import confirm dialog to ensure the parent doc is selected when a processor filter is selected.
-
Change DocRef Info Cache to evict entries on document creation to stop stroom saying that a document doesn’t exist after import.
-
Issue #5077 : Fix bug in user full name templating where it is always re-using the first value, i.e. setting every user to have the full name of the first user to log in.
-
Issue #5073 : Trim the unique identity, display name and full name values for a user to ensure no leading/trailing spaces are stored. Includes DB migration
V07_10_00_005__trim_user_identities.sqlthat trims existing values in thename,display_nameandfull_namecolumns of thestroom_usertable. -
Issue #5046 : Stop feeds being auto-created when there is no content template match.
-
Issue #5062 : Fix permissions issue loading scheduled executors.
-
Allow clientSecret to be null/empty for mTLS auth.
-
Issue #5017 : Fix stuck spinner copying embedded query.
-
Issue #4974 : Fix Plan B condense job.
-
Issue #4977 : Limit user visibility in annotations.
-
Issue #4976 : Exclude deleted annotations.
-
Issue #5002 : Fix Plan B env staying open after error.
-
Issue #5003 : Fix query date time formatting.
-
Issue #4974 : Improve logging.
-
Issue #4974 : NPE debug.
-
Issue #4983 : Upgrade Flyway to work with newer version of MySQL.
-
Issue #3122 : Make date/time rounding functions time zone sensitive.
-
Issue #4984 : Add debug for Plan B tagged keys.
-
Issue #4991 : Add Plan B schema validation to ensure stores remain compatible especially when merging parts.
-
Issue #4854 : Maintain scrollbar position on datagrid.
-
Issue #4957 : Default vis settings are not added to Query pane visualisations.
-
Issue #4456 : Fix selection handling across multiple components by uniquely namespacing selections.
-
Issue #4886 : Fix ctrl+enter query execution for rules and reports.
-
Issue #4884 : Suggest only queryable fields in StroomQL where clause.
-
Issue #4945 : Increase index field name length.
5 - Version 7.9
5.1 - New Features
5.2 - Preview Features (experimental)
Data Feed Keys
Data Feed Keys are a new authentication mechanism for data receipt into both Stroom-Proxy and Stroom. They allow for a set of hashed short life keys to be placed in a directory accessible to Stroom-Proxy/Stroom for receipt requests to be authenticated against.
The following is an example of a Data Feed Key file:
{
"dataFeedKeys" : [ {
"expiryDateEpochMs" : 1744279266584,
"hash" : "4KP8qRFigfKHAMQgWVHCvgXtf293wsETMwWbaUJcgC2JSqP6qF1YHacyUe8C7CrAAa",
"hashAlgorithmId" : "000",
"streamMetaData" : {
"AccountId" : "1000",
"MetaKey2" : "MetaKey2Val-1000",
"MetaKey1" : "MetaKey1Val-1000"
}
}, {
"expiryDateEpochMs" : 1744279266584,
"hash" : "8U7roYFWcj3Ht8cGbAavemQPm2P93xEC9QnvdUCuth4EKmbvEjVM2NWje1bPkKWx7s",
"hashAlgorithmId" : "000",
"streamMetaData" : {
"AccountId" : "1001",
"MetaKey2" : "MetaKey2Val-1001",
"MetaKey1" : "MetaKey1Val-1001"
}
}
}
A file can contain many hashed keys.
One or more files of this format are placed in the directory defined by the Stroom-Proxy/Stroom config property .receive.dataFeedKeysDir.
This allows for generating Data Feed Keys with a life of say 26hrs, adding a new file every day and deleting files older than 2 days.
The file(s) will be read on boot and all hashed keys will be stored in memory for receipt authentication. Files added to this directory while Stroom-Proxy/Stroom is running will be read and added to the in-memory store of hashed keys. Files deleted from this directory will result in all entries associated with the file path being removed from the in-memory store of hashed keys.
The accountId is typically an identifier for a client team that may have one or more systems that require one or more Feeds in Stroom.
This JSON key, which identifies the ownership of the Data Feed Key, is configured via the property .receive.dataFeedKeyOwnerMetaKey.
Data Feed Keys have an expiry date after which they will no longer work.
An accountID can have many active Data Feed Keys.
Multiple files can be placed in the directory and all valid keys will be loaded.
The hashAlgorithmId is the identifier for the hash algorithm used to hash the key.
The system creating the hashed data feed keys must use the same hash algorithm and parameters when hashing the key as Stroom will use when it hashes the key used in data receipt to validate them.
streamMetaData provides a means to add meta attributes to data received with a Data Feed Key.
The attributes in streamMetaData will overwrite any matching attribute keys in the received data.
Currently the only hash algorithm available for use is Argon2 with an ID of 000 and the following parameters:
- Hash length: 48
- Iterations: 2
- Memory KB: 65536
A Data Feed Key takes the following form:
sdk_<3 char hash algorithm ID>_<128 char random Base58 string>
The regular expression pattern for a Data Feed Key is
^sdk_[0-9]{3}_[A-HJ-NP-Za-km-z1-9]{128}$
Data Feed Keys are used in the same way as API Keys or OAuth2 tokens, i.e. using the Header Authorization: Bearer <data feed key>.
Content Auto-Generation
In an effort to streamline the process of getting client systems to send data to Stroom we have added auto-generation of content and removed the need to supply a feed name. The aim is that client systems can provide a number of mandatory headers with their data that will then be used to auto-generate a feed name, create the feed and create content from a template to process that feed’s data.
Note
This feature is optional and controlled with configuration. If not enabled, the Feed header will be mandatory as before.The default Stroom configuration for controlling Data Feed Keys, auto content creation and feed name generation is:
appConfig:
autoContentCreation:
additionalGroupTemplate: "grp-${accountid}-sandbox"
createAsSubjectId: "Administrators"
createAsType: "GROUP"
destinationExplorerPathTemplate: "/Feeds/${accountid}"
enabled: false
groupTemplate: "grp-${accountid}"
templateMatchFields:
- "accountid"
- "accountname"
- "component"
- "feed"
- "format"
- "schema"
- "schemaversion"
receive: # applicable to both appConfig: and proxyConfig:
allowedCertificateProviders: []
authenticatedDataFeedKeyCache:
#...
authenticationRequired: true
dataFeedKeyOwnerMetaKey: "AccountId"
dataFeedKeysDir: "data_feed_keys"
enabledAuthenticationTypes: # Also DATA_FEED_KEY and TOKEN
- "CERTIFICATE"
feedNameGenerationEnabled: false
feedNameGenerationMandatoryHeaders:
- "AccountId"
- "Component"
- "Format"
- "Schema"
feedNameTemplate: "${accountid}-${component}-${format}-${schema}"
metaTypes:
# ...
Feed Name Generation
When the property .receive.feedNameGenerationEnabled is set to true, the Feed header is no longer required.
When data is supplied without the Feed header, the meta keys specified in .receive.feedNameGenerationMandatoryHeaders become mandatory.
The property .receive.feedNameTemplate is used to control the format of the generated Feed name.
The template uses values from the headers, so should be configured in tandem with .receive.feedNameGenerationMandatoryHeaders.
If the template parameter is not in the headers, then it will be replaced with nothing.
If enabled, Feed name generation happens on data receipt in both Stroom-Proxy and Stroom.
Feed and Group Creation
The .autoContentCreation.enabled property controls whether auto-generation of content will take place on data receipt.
Content auto-generation happens as part of the feed status check, so will either be triggered when Stroom-Proxy requests a feed status check from Stroom or Stroom receives data directly.
If the generated Feed name does not exist then it will be created in the explorer path as defined by the template in .receive.destinationExplorerPathTemplate.
If the Feed name does exist then no further content creation will happen.
One or two user groups will be created and be granted permissions on the created content.
This is to provide user groups for users of the client system to be able to access the data.
The name of these groups is controlled by groupTemplate and additionalGroupTemplate respectively.
The former group only has VIEW permission, while the latter has EDIT permission on the created content.
The latter group is intended for clients to be able to manage the translation of their data while it is going through a take-on-work style process.
If the /datafeed request was authenticated (e.g. using a token, certificate, API key or Data Feed Key) then the identifier of the subject will be set in the UploadUserId header.
It will also ensure that a user exists in Stroom for this identity and that the user is added to the two groups created above.
Content Templates
In Stroom a new Content Templates screen has been added, accessible from the menu.
This screen allows a user with the Manage Content Templates application permission to create a number of content templates.
Each template has an expression that will be used to match on the headers when auto-generation of content has been triggered.
The template expressions are evaluated in order from the top.
If a template’s expression matches, content will be created according to the template. A template currently has two modes:
INHERIT_PIPELINE- A new pipeline will be created that inherits from the existing pipeline specified in the template. The new pipeline will be created in the folder defined by.receive.destinationExplorerPathTemplate.PROCESSOR_FILTER- A new processor filter will be added to the existing pipeline specified in the template.
5.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.Stroom
Feed Status Check
If any proxy instances call into Stroom to make a feed status check using an API key, then the owner of those API keys will now need to be granted the Check Receipt Status application permission.
Stroom-Proxy
maxOpenFiles
The config property proxyConfig.eventStore.maxOpenFiles has been replaced with proxyConfig.eventStore.openFilesCache.
The default value for this property branch is:
proxyConfig:
eventStore:
openFilesCache:
expireAfterAccess: null
expireAfterWrite: null
maximumSize: 100
refreshAfterWrite: null
statisticsMode: "DROPWIZARD_METRICS"
5.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom instance.Java Version
Stroom v7.9 requires Java 21. This is the same java version as Stroom v7.8. Ensure the Stroom and Stroom-Proxy hosts are running the latest patch release of Java v21.
Configuration File Changes
Stroom’s config.yml
Cache Config
A new property statisticsMode has been added to the standard cache config structure as used by all caches.
This controls whether and how cache statistics should be record.
Possible values are:
NONE- Do not capture any statistics on cache usage. This means no statistics will be available for this cache in the Stroom UI. Capturing statistics has a minor performance penalty.INTERNAL- Uses the internal mechanism for capturing statistics. This is only suitable for Stroom as these can be viewed through the UI.DROPWIZARD_METRICS- Uses Dropwizard Metrics for capturing statistics. This allows the cache stats to be accessed via tools such as Graphite/Collectd in addition to the Stroom UI. This adds a very slight performance overhead overINTERNAL. This is suitable for both Stroom and Stroom-Proxy.
Annotations
The following standard cache configuration blocks have been added for annotations, along with retention configuration.
appConfig:
annotation:
annotationFeedCache:
expireAfterAccess: "PT10M"
expireAfterWrite: null
maximumSize: 1000
refreshAfterWrite: null
statisticsMode: "INTERNAL"
annotationTagCache:
expireAfterAccess: "PT10M"
expireAfterWrite: null
maximumSize: 1000
refreshAfterWrite: null
statisticsMode: "INTERNAL"
defaultRetentionPeriod: "5y"
physicalDeleteAge: "P7D"
Content Auto-Generation
A new branch autoContentCreation has been added for content auto-generation, see
appConfig:
autoContentCreation:
additionalGroupTemplate: "grp-${accountid}-sandbox"
createAsSubjectId: "Administrators"
createAsType: "GROUP"
destinationExplorerPathTemplate: "/Feeds/${accountid}"
enabled: false
groupTemplate: "grp-${accountid}"
templateMatchFields:
- "accountid"
- "accountname"
- "component"
- "feed"
- "format"
- "schema"
- "schemaversion"
Data Formats
A new property has been added to control the list of data format names that can be assigned to a feed. The property must include at least the values below.
appConfig:
data:
meta:
dataFormats:
- "FIXED_WIDTH_NO_HEADER"
- "INI"
- "CSV"
- "JSON"
- "TEXT"
- "XML_FRAGMENT"
- "YAML"
- "PSV_NO_HEADER"
- "PSV"
- "CSV_NO_HEADER"
- "XML"
- "TSV"
- "SYSLOG"
- "TSV_NO_HEADER"
- "FIXED_WIDTH"
- "TOML"
Data Receipt
The following properties have been added.
appConfig:
receive:
allowedCertificateProviders: []
authenticatedDataFeedKeyCache:
expireAfterAccess: null
expireAfterWrite: "PT5M"
maximumSize: 1000
refreshAfterWrite: null
statisticsMode: "DROPWIZARD_METRICS"
authenticationRequired: true
dataFeedKeyOwnerMetaKey: "AccountId"
dataFeedKeysDir: "data_feed_keys"
enabledAuthenticationTypes:
- "CERTIFICATE"
- "TOKEN"
- "DATA_FEED_KEY"
feedNameGenerationEnabled: false
feedNameGenerationMandatoryHeaders:
- "AccountId"
- "Component"
- "Format"
- "Schema"
feedNameTemplate: "${accountid}-${component}-${format}-${schema}"
x509CertificateDnHeader: "X-SSL-CLIENT-S-DN"
x509CertificateHeader: "X-SSL-CERT"
The following properties have been removed.
appConfig:
receive:
tokenAuthenticationEnabled: false
certificateAuthenticationEnabled: true
Content Security Policy
The default value for the contentSecurityPolicy property has changed from this:
appConfig:
security:
webContent:
contentSecurityPolicy: "default-src 'self'; script-src 'self' 'unsafe-eval'\
\ 'unsafe-inline'; img-src 'self' data:; style-src 'self' 'unsafe-inline';\
\ connect-src 'self' wss:; frame-ancestors 'self';"
To this:
appConfig:
security:
webContent:
contentSecurityPolicy: "default-src 'self'; script-src 'self' 'unsafe-eval'\
\ 'unsafe-inline'; img-src 'self' data:; style-src 'self' 'unsafe-inline';\
\ frame-ancestors 'self';"
Stroom-Proxy’s config.yml
Cache Config
A new property statisticsMode has been added to the standard cache config structure as used by all caches.
This controls whether and how cache statistics should be record.
Possible values are:
NONE- Do not capture any statistics on cache usage. This means no statistics will be available for this cache in the Stroom UI. Capturing statistics has a minor performance penalty.DROPWIZARD_METRICS- Uses Dropwizard Metrics for capturing statistics. This allows the cache stats to be accessed via tools such as Graphite/Collectd in addition to the Stroom UI. This adds a very slight performance overhead overINTERNAL. This is suitable for both Stroom and Stroom-Proxy.
Aggregation
The default aggregation frequency has changed from PT1M to PT10M.
proxyConfig:
aggregator:
aggregationFrequency: "PT10M"
The property maxOpenFiles has been replaced with a standard cache configuration branch.
proxyConfig:
aggregator:
openFilesCache:
expireAfterAccess: null
expireAfterWrite: null
maximumSize: 100
refreshAfterWrite: null
statisticsMode: "DROPWIZARD_METRICS"
Data Receipt
Proxy uses the same data receipt config structure as Stroom, so see above for details of the changes.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Migration Scripts
For information purposes only, the following are the database migrations that will be run when upgrading to 7.9.0 from the previous minor version.
Note, the legacy module will run first (if present) then the other module will run in no particular order.
Module stroom-annotation
Script V07_09_00_001__annotation2.sql
Path: stroom-annotation/stroom-annotation-impl-db/src/main/resources/stroom/annotation/impl/db/migration/V07_09_00_001__annotation2.sql
-- ------------------------------------------------------------------------
-- Copyright 2023 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
CREATE TABLE IF NOT EXISTS annotation_tag (
id int(11) NOT NULL AUTO_INCREMENT,
uuid varchar(255) NOT NULL,
type_id tinyint NOT NULL,
name varchar(255) NOT NULL,
style_id tinyint DEFAULT NULL,
deleted tinyint NOT NULL DEFAULT '0',
PRIMARY KEY (id),
UNIQUE KEY `annotation_tag_type_id_name_idx` (`type_id`, `name`),
UNIQUE KEY `annotation_tag_uuid_idx` (`uuid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS annotation_tag_link (
id bigint(20) NOT NULL AUTO_INCREMENT,
fk_annotation_id bigint(20) NOT NULL,
fk_annotation_tag_id int(11) NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY fk_annotation_id_fk_annotation_tag_id (fk_annotation_id, fk_annotation_tag_id),
CONSTRAINT annotation_tag_link_fk_annotation_id FOREIGN KEY (fk_annotation_id) REFERENCES annotation (id),
CONSTRAINT annotation_tag_link_fk_annotation_tag_id FOREIGN KEY (fk_annotation_tag_id) REFERENCES annotation_tag (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS annotation_link (
id bigint(20) NOT NULL AUTO_INCREMENT,
fk_annotation_src_id bigint(20) NOT NULL,
fk_annotation_dst_id bigint(20) NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY fk_annotation_src_id_fk_annotation_dst_id (fk_annotation_src_id, fk_annotation_dst_id),
CONSTRAINT annotation_link_fk_annotation_src_id FOREIGN KEY (fk_annotation_src_id) REFERENCES annotation (id),
CONSTRAINT annotation_link_fk_annotation_dst_id FOREIGN KEY (fk_annotation_dst_id) REFERENCES annotation (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS annotation_subscription (
id bigint(20) NOT NULL AUTO_INCREMENT,
fk_annotation_id bigint(20) NOT NULL,
user_uuid varchar(255) NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY fk_annotation_id_user_uuid (fk_annotation_id, user_uuid),
CONSTRAINT annotation_subscription_fk_annotation_id FOREIGN KEY (fk_annotation_id) REFERENCES annotation (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS `annotation_feed` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `annotation_feed_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
DROP PROCEDURE IF EXISTS V07_09_00_001_annotation;
DELIMITER $$
CREATE PROCEDURE V07_09_00_001_annotation ()
BEGIN
DECLARE object_count integer;
--
-- Add logical delete
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation'
AND column_name = 'deleted';
IF object_count = 0 THEN
ALTER TABLE `annotation` ADD COLUMN `deleted` tinyint NOT NULL DEFAULT '0';
END IF;
--
-- Add description
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation'
AND column_name = 'description';
IF object_count = 0 THEN
ALTER TABLE `annotation`
ADD COLUMN `description` longtext;
END IF;
--
-- Add data retention time
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation'
AND column_name = 'retention_time';
IF object_count = 0 THEN
ALTER TABLE `annotation` ADD COLUMN `retention_time` bigint(20) DEFAULT NULL;
END IF;
--
-- Add data retention unit
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation'
AND column_name = 'retention_unit';
IF object_count = 0 THEN
ALTER TABLE `annotation` ADD COLUMN `retention_unit` tinyint DEFAULT NULL;
END IF;
--
-- Add data retention until
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation'
AND column_name = 'retain_until_ms';
IF object_count = 0 THEN
ALTER TABLE `annotation`
ADD COLUMN `retain_until_ms` bigint DEFAULT NULL;
END IF;
--
-- Add parent id
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation'
AND column_name = 'parent_id';
IF object_count = 0 THEN
ALTER TABLE `annotation`
ADD COLUMN `parent_id` bigint(20) DEFAULT NULL;
END IF;
--
-- Add entry type id
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation_entry'
AND column_name = 'type_id';
IF object_count = 0 THEN
ALTER TABLE annotation_entry ADD COLUMN type_id tinyint NOT NULL;
UPDATE annotation_entry SET type_id = 0 WHERE type = "Title";
UPDATE annotation_entry SET type_id = 1 WHERE type = "Subject";
UPDATE annotation_entry SET type_id = 2 WHERE type = "Status";
UPDATE annotation_entry SET type_id = 3 WHERE type = "Assigned";
UPDATE annotation_entry SET type_id = 4 WHERE type = "Comment";
UPDATE annotation_entry SET type_id = 5 WHERE type = "Link";
UPDATE annotation_entry SET type_id = 6 WHERE type = "Unlink";
ALTER TABLE annotation_entry DROP COLUMN type;
END IF;
--
-- Add entry logical delete
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation_entry'
AND column_name = 'deleted';
IF object_count = 0 THEN
ALTER TABLE `annotation_entry` ADD COLUMN `deleted` tinyint NOT NULL DEFAULT '0';
END IF;
--
-- Remove status
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation'
AND column_name = 'status';
IF object_count > 0 THEN
INSERT INTO annotation_tag (uuid, type_id, name, style_id, deleted)
SELECT uuid(), 0, status, null, 0
FROM annotation
WHERE status NOT IN (SELECT name FROM annotation_tag WHERE type_id = 0)
GROUP BY status;
INSERT INTO annotation_tag_link (fk_annotation_id, fk_annotation_tag_id)
SELECT a.id, at.id
FROM annotation a
JOIN annotation_tag at ON (a.status = at.name AND at.type_id = 0)
WHERE a.id NOT IN (SELECT fk_annotation_id FROM annotation_tag_link);
ALTER TABLE `annotation` DROP COLUMN `status`;
END IF;
--
-- Remove comment
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation'
AND column_name = 'comment';
IF object_count > 0 THEN
ALTER TABLE `annotation` DROP COLUMN `comment`;
END IF;
--
-- Remove history
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation'
AND column_name = 'history';
IF object_count > 0 THEN
ALTER TABLE `annotation` DROP COLUMN `history`;
END IF;
--
-- Add feed
--
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation_data_link'
AND column_name = 'feed_id';
IF object_count = 0 THEN
ALTER TABLE `annotation_data_link` ADD COLUMN `feed_id` int DEFAULT NULL;
END IF;
END $$
DELIMITER ;
CALL V07_09_00_001_annotation;
DROP PROCEDURE IF EXISTS V07_09_00_001_annotation;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
5.5 - Change Log
-
Fix primitive value conversion of query field types.
-
Issue #4940 : Fix duplicate store error log.
-
Issue #4941 : Fix annotation data retention.
-
Issue #4968 : Improve Plan B file receipt.
-
Issue #4956 : Add error handling to duplicate check deletion.
-
Issue #4967 : Fix SQL deadlock.
-
Fix compile issues.
-
Issue #4875 : Fix select *.
-
Issue #3928 : Add merge filter for deeply nested data.
-
Issue #4211 : Prevent stream status in processing filters.
-
Issue #4927 : Fix TOKEN data feed auth when DATA_FEED_KEY is enabled.
-
Issue #4862 : Add select * to StroomQL.
-
Annotations 2.0.
-
Uplift BCrypt lib to 0.4.3.
-
Add BCrypt as a hashing algorithm to data feed keys. Change Data feed key auth to require the header as configured by
dataFeedKeyOwnerMetaKey. ChangehashAlgorithmIdtohashAlgorithmin the data feed keys json file. -
Issue #4109 : Add
receiveconfig propertiesx509CertificateHeader,x509CertificateDnHeaderandallowedCertificateProvidersto control the use of certificates and DNs placed in the request headers by load balancers or reverse proxies that are doing the TLS termination. Header keys were previously hard coded.allowedCertificateProvidersis an allow list of FQDN/IPs that are allowed to use the cert/DN headers. -
Add Dropwizard Metrics to proxy.
-
Change proxy to use the same caching as stroom.
-
Remove unused proxy config property
maxAggregateAge.aggregationFrequencycontrols the aggregation age/frequency. -
Stroom-Proxy instances that are making remote feed status requests using an API key or token, will now need to hold the application permission
Check Receipt Statusin Stroom. This prevents anybody with an API key from checking feed statuses. -
Issue #4312 : Add Data Feed Keys to proxy and stroom to allow their use in data receipt authentication. Replace
proxyConfig.receive.(certificateAuthenticationEnabled|tokenAuthenticationEnabled)withproxyConfig.receive.enabledAuthenticationTypesthat takes values:DATA_FEED_KEY|TOKEN|CERTIFICATE(whereTOKENmeans an oauth token or an API key). The feed status check endpoint/api/feedStatus/v1has been deprecated. Proxies with a version >=v7.9 should now use/api/feedStatus/v2. -
Replace proxy config prop
proxyConfig.eventStore.maxOpenFileswithproxyConfig.eventStore.openFilesCache. -
Add optional auto-generation of the
Feedattribute using propertyproxyConfig.receive.feedNameGenerationEnabled. This is used alongside propertiesproxyConfig.receive.feedNameTemplate(which defines a template for the auto-generated feed name using meta keys and their values) andfeedNameGenerationMandatoryHeaderswhich defines the mandatory meta headers that must be present for a auto-generation of the feed name to be possible. -
Add a new Content Templates screen to stroom (requires
Manage Content Templatesapplication permission). This screen is used to define rules for matching incoming data where the feed does not exist and creating content to process data for that feed. -
Feed status check calls made by a proxy into stroom now require the application permission
Check Receipt Status. This is to stop anyone with an API key from discovering the feeds available in stroom. Any existing API keys used for feed status checks on proxy will need to haveCheck Receipt Statusgranted to the owner of the key. -
Issue #4839 : Change record count filter to allow counting of records at a custom depth to match split filter.
-
Issue #4828 : Fix recursive cache invalidation for index load.
-
Issue #4827 : Fix NPE when opening the Nodes screen.
-
Issue #4733 : Fix report shutdown error.
-
Issue #4778 : Improve menu text rendering.
-
Issue #4552 : Update dynamic index fields via the UI.
-
Issue #3921 : Make QuickFilterPredicateFactory produce an expression tree.
-
Issue #3820 : Add OR conditions to quick filter.
-
Issue #3551 : Fix character escape in quick filter.
-
Issue #4553 : Fix word boundary matching.
-
Issue #4776 : Fix column value
>,>=,<,<=, filtering. -
Issue #4772 : Uplift GWT to version 2.12.1.
-
Issue #4773 : Improve cookie config.
-
Issue #4692 : Add table column filtering by unique value selection.
6 - Version 7.8
6.1 - New Features
New Stroom-Proxy implementation
Stroom-Proxy has been re-written to fundamentally change the way it works internally. This is to improve performance over previous Stroom-Proxy implementations and to make it more robust.
TODO
Reporting
A reporting feature has been added in 7.8. It allows users to schedule queries that can be run at specific points in time to output tabular data in CSV or Excel etc. Any data source that can be queried in stroom can be the source of a report. Reports can be emailed to individuals or written as a stream for onward processing.
Apache HTTP Client
Previous versions of Stroom and Stroom-Proxy used a variety of HTTP clients for making HTTP requests, e.g. from the HTTPAppender . These have been standardised to all use the Apache HTTP client which means a consistent set of configuration can be used.
Receipt ID
A new meta attribute (ReceiptId) has been added to Stroom and Stroom-Proxy to provide a unique identifier for each request received.
The format of this attribute has been made to make it more useful to administrators, while still being unique across the environment that the Stroom and Stroom-Proxy instances are deployed in.
The format is as follows:
<timestamp>_<seq no>_<(P|S)>_<proxyId or stroom nodeName>
<timestamp>- The receipt timestamp in milliseconds since the Unix Epoch Unix Epoch The Unix epoch is 00:00:00 UTC on 1st January 1970. Some timestamps in Stroom are represented as the number of milliseconds since the Unix epoch, e.g.1738331628276, and may be referred to as epoch ms or epoch milliseconds.Click to see more details..., zero padded.<seq no>- This is zero padded four digit sequential number (starting at0000) that is used to distinguish between multiple receipt events happening during the same millisecond.<P|S>- Indicates whether the item was received by Stroom (S) or Stroom-Proxy (P).<proxyId or stroom nodeName>- For Stroom-Proxy this will be theproxyIdthat is either set in configuration to uniquely identify a proxy instance or is one of the FQDN/IP. For Stroom this is the node name of the Stroom instance.
An example Receipt ID is 0000001738332835967_0000_P_node1
The new format is useful for tracing the flow of data through a chain of proxies as it will be included in receive and send logs as well as being written to the meta attributes.
In addition to ReceiptId we also have ReceiptIdPath which will have a ReceiptId appended to it on each receipt (comma delimited).
To ensure uniqueness of these IDs across the estate, ProxyIDs should be unique within the environment that data will flow. The same is true for Stroom node names.
6.2 - Preview Features (experimental)
There are no preview features in v7.8.
6.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.Stroom
Service Discovery
See Configuration File Changes (Service Discovery).
Stroom-Proxy
The new implementation of Stroom-Proxy is not compatible with previous versions. It uses a different structure for its local repository. Therefore you CANNOT deploy Stroom-Proxy v7.8 on top of a previous Stroom-Proxy version as it will be unable to process existing stored data that has not yet been forwarded.
You have two options:
-
Run the old and new in parallel until the old one has processed all its data, then shutdown and uninstall the old one.
-
Prevent data going to the old Stroom-Proxy and allow it to process all its data. Shut it down and remove the installation. Install the new v7.8 Stroom-Proxy. Allow data to flow in again.
6.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom instance.Java Version
Stroom v7.8 requires Java 21. This is the same java version as Stroom v7.7. Ensure the Stroom and Stroom-Proxy hosts are running the latest patch release of Java v21.
Configuration File Changes
Stroom’s config.yml
Service Discovery
If your config.yml file contains the serviceDiscovery branch, you need to remove it as the associated service discovery code has been removed from Stroom.
If you do not remove it, Stroom will not boot.
appConfig:
serviceDiscovery: # Remove this branch
Plan B State Store
The following block of config has been added for the experimental Plan B State Store.
appConfig:
planb:
minTimeToKeepEnvOpen: "PT1M"
minTimeToKeepSnapshots: "PT10M"
nodeList: []
path: "${stroom.home}/planb"
snapshotRetryFetchInterval: "PT1M"
stateDocCache:
expireAfterAccess: null
expireAfterWrite: "PT10M"
maximumSize: 100
refreshAfterWrite: null
Reporting
The following block of config has been added for the new reporting feature.
appConfig:
ui:
reportUiDefaultConfig:
defaultBodyTemplate: "<!DOCTYPE html>\n<html lang=\"en\">\n<meta charset=\"\
UTF-8\" />\n<title>Report '{{ reportName | escape }}'</title>\n<body>\n <p><em>Report:\
\ {{ reportName | escape }}</em> executed for {{ effectiveExecutionTime |\
\ escape }} on {{ executionTime | escape }}</p>\n <p><em>Description:</em>\
\ {{ description | escape }}</p>\n</body>\n"
defaultSubjectTemplate: "Report '{{ reportName | escape }}'"
OpenID HTTP Client
Added the property httpClient for configuring the HTTP client used to fetch the
IDP's
Identity Provider (IDP)
An Identity Provider is a system or service that can authenticate a user and assert their identity. Identity providers can support single sign on (SSO), which allows the user to sign in once to the Identity Provider so they are then authenticated to all systems using that IDP.Click to see more details... configuration.
security:
authentication:
openId:
httpClient: null
Stroom-Proxy’s config.yml
The configuration for proxy has changed significantly since the last stable release of Stroom-Proxy (7.0.x) so it is advised to look at the default Stroom-Proxy configuration that comes with the distribution.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Migration Scripts
There are no database migrations in v7.8.
6.5 - Change Log
-
Issue #4682 : Improve Plan B filter error handling.
-
Change
receiptIdformat to<epoch ms>_<seq no>_<(P|S)>_<proxyId or stroom nodeName>.P|Srepresents stroom or Proxy. -
Change stroom to also set the
receiptIdmeta attribute on receipt or upload. -
Change proxy logging to still log datafeed events even if the
metaKeysconfig prop is empty. -
Issue #4695 : Change proxy to re-create the proxy ID in proxy-id.txt if the value in there does not match the required pattern.
-
Fix the sleep time in UniqueIdGenerator (from 50ms to 0.1ms).
-
Fix tests that were breaking the build.
-
Change the format of proxy receiptIds. They now look like
0000001736533752496_0000_TestProxywith the first part being the epoch millis for when it was generated and the last part is the proxy ID. -
Change default
identityProviderTypetoINTERNAL_IDPin stroom prod config. -
Issue #4661 : Use Apache HttpClient.
-
Issue #4378 : Add reporting.
-
Issue #2201 : New proxy implementation.
7 - Version 7.7
7.1 - New Features
-
Issue #4686 : StroomQL now uses
stroom.ui.defaultMaxResultsif noLIMITis set. -
Issue #4672 : Add right click menu to copyable items.
-
Issue #4708 : Add copy links to stream info pane.
-
Issue #4652 : Add user links to server tasks and search results lists.
-
Issue #4672 : Add context menus to table cells to copy values.
-
Issue #4655 : Allow selection of no conditional style.
-
Issue #4660 : Show pipelines and rules on processor and task panes.
-
Issue #4605 : Allow embedded queries to be re-run independently.
-
Issue #4642 : Show current dashboard selections to help create selection filters.
-
Issue #4645 : Add feature to disable notifications.
-
Issue #4596 : Add case-sensitive value filter conditions.
-
Issue #4596 : Drive visualisations using table quick filters and selection handlers.
-
Issue #4596 : Merge include/exclude and column value filter dialogs.
-
Issue #4596 : Change conditional formatting to allow custom light and dark colours.
-
Issue #4596 : Turn off conditional formatting with user preferences.
-
Issue #4596 : Add table value filter dialog option.
-
Issue #4523 : Embed queries in dashboards.
-
Issue #4504 : Add column value filters.
-
Issue #4547 : Add selection handlers to dashboard tables to quick filter based on component selection.
-
Issue #4071 : Add preset theme compatible styles for conditional formatting.
7.2 - Preview Features (experimental)
There are no preview features in v7.7.
7.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.There are no breaking changes in v7.7.
7.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom instance.Java Version
Stroom v7.7 requires Java 21. This is the same java version as Stroom v7.6. Ensure the Stroom and Stroom-Proxy hosts are running the latest patch release of Java v21.
Configuration File Changes
Stroom’s config.yml
No changes have been made configuration file.
Stroom-Proxy’s config.yml
No changes have been made configuration file.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Migration Scripts
There are no database migrations in v7.7.
7.5 - Change Log
-
Issue #4690 : Fix meta data source fields.
-
Issue #4691 : Fix meta data source fields.
-
Issue #4701 : Fix selection filter null component.
-
Issue #4698 : Fix default S3 Appender options.
-
Issue #4686 : StroomQL now uses
stroom.ui.defaultMaxResultsif noLIMITis set. -
Issue #4696 : Fix paging of large numbers of data sources.
-
Issue #4672 : Add right click menu to copyable items.
-
Issue #4719 : Fix duplicate pipeline dependencies per user due to multiple processor filters.
-
Issue #4728 : No longer treat deleted pipeline filters as dependencies.
-
Issue #4707 : Fix doc ref info service.
-
Issue #4713 : Fix datasource in use issue for API key DAO.
-
Issue #4714 : Fix display of disabled
RunAsusers. -
Issue #4708 : Add copy links to stream info pane.
-
Issue #4687 : Fix dependencies NPE.
-
Issue #4717 : Fix processor filter expression fields.
-
Issue #4652 : Add user links to server tasks and search results lists.
-
Issue #4669 : Make user dependency list document column resizable.
-
Issue #4685 : Fix doc permission layout.
-
Issue #4705 : Fix conditional format fall through.
-
Issue #4672 : Add context menus to table cells to copy values.
-
Issue #4632 : Fix conditional formatting rule id clash.
-
Issue #4655 : Allow selection of no conditional style.
-
Issue #4632 : Fix conditional formatting rule id clash.
-
Issue #4657 : Fix middle pane stream delete.
-
Issue #4660 : Show pipelines and rules on processor and task panes.
-
Issue #4632 : Fix conditional formatting styles.
-
Issue #4634 : Make icons on highlighted rows white.
-
Issue #4605 : Allow embedded queried to be re-run independently.
-
Issue #4631 : Fix simple expression wildcards.
-
Issue #4641 : Reset selections when dashboard table data changes.
-
Issue #4642 : Show current dashboard selections to help create selection filters.
-
Issue #4637 : Fix StroomQL filter in dictionary.
-
Issue #4645 : Add feature to disable notifications.
-
Issue #4596 : Add case-sensitive value filter conditions.
-
Issue #4596 : Drive visualisations using table quick filters and selection handlers.
-
Issue #4596 : Merge include/exclude and column value filter dialogs.
-
Issue #4596 : Change conditional formatting to allow custom light and dark colours.
-
Issue #4596 : Turn off conditional formatting with user preferences.
-
Issue #4601 : Add null handling and better error logging to Excel download.
-
Issue #4597 : Fix NPE when opening the Document Permissions Report screen for a user.
-
Change the code that counts expression terms and gets all fields/values from an expression tree to no longer ignore NOT operators.
-
Issue #4596 : Fix demo bugs.
-
Issue #4596 : Add table value filter dialog option.
-
Change the permission filtering to use a LinkedHashSet for children of and descendants of terms.
-
Issue #4523 : Embed queries in dashboards.
-
Issue #4504 : Add column value filters.
-
Issue #4546 : Remove redundant dashboard tab options.
-
Issue #4547 : Add selection handlers to dashboard tables to quick filter based on component selection.
-
Issue #4071 : Add preset theme compatible styles for conditional formatting.
-
Issue #4157 : Fix copy of conditional formatting rules.
8 - Version 7.6
8.1 - New Features
Document and Application Permissions
The document and permissions model has undergone significant changes. Both the user interface and underlying data model has changed.
The legacy screens for managing users, groups and their permissions were often very confusing to use. The new screens attempt to make it much more intuitive.
Terminology
- Explicit / Direct - This means a permission is specifically granted to the User/Group in question.
- Inherited / Effective - This means a permission is granted to the Group that a User/Group is a member of or is granted to an ancestor Group.
Groups of Groups
Previously in Stroom it was not possible for a Group to be a member of a Group. This has been changed so now a Group’s membership can include both Users and Groups. This allows a richer permissions structure to be created.
For example you can have a Basic Users group that has limited application permissions and a Super Users group that is a member of Basic Users so it inherits all the basic permissions and adds its own set of explicit permissions.
Users Screen
A Users screen has been added to list all
Stroom Users
User
Refers to a Stroom User that is linked to either an Account in Stroom’s internal Identity Provider or a user account in an external Identity Provider. A Stroom User is only concerned with authorisation (i.e. application/document permissions and group memberships), and not authentication.Click to see more details... (as distinct from
Accounts
Account
Refers to a user account in Stroom’s internal Identity Provider.Click to see more details....
This screen is only available to users that hold the Manage Users application permission.
It is accessible from:
Or the key bind g , g .
It lists all users and allows the user to jump to various other screens relating to that user.

It is also possible to jump to User screen for a specific user by clicking the hover icon.
Groups Screen
A Groups screen has been added for managing User Groups Group (users) A named group of users to which application and document permissions can be assigned. Users can belong to multiple groups. A Group can belong to multiple groups. Groups allow permissions to be assigned to the group such that members of that group inherit those permissions.Click to see more details... and their memberships. It is accessible from:
Or the key bind g , g .
This screen is split into two or three panes depending on whether you have selected a User or Group in the top pane. The top pane lists all users and groups in stroom, with the icon indicating the type. In this pane you can add/edit Groups.
If you have selected a User then you will see only two panes. The bottom pane will display all the Groups that the user is a direct member of, i.e. one that they have been explicitly added to. This pane can be used to add the selected User to another Group or to remove them from a Group that they are already a member of.
If you have selected a Group in the top pane then you will see three panes.
The bottom left pane will show Groups that the selected Group is a direct member of. This pane can be used to add the selected Group to another Group or to remove them from a Group that they are already a member of.
The bottom right pane will show all direct members of the selected Group. It can be used to add/remove members, be they Users or Groups.
Application Permissions Screen
This screen has been added to manage the application level permissions that are granted to Users/Groups. It replaces the previous modal dialog screen. It is accessible from:
Or the key bind g , a .
This screen is split into three panes.
-
Top pane - Lists the Users and Groups, depending on the selection in the Permission Visibility drop-down. The Permission Visibility has the following values:
Show Explicit- Shows only those Users/Groups that have at least one application permission explicitly granted to them.Show Effective- Shows only those Users/Groups that have at least one application permission explicitly granted to them or to a group that they are a member of (directly or indirectly).Show All- Shows all Users/Groups. The Permissions column lists all the permissions granted to the User/Group, explicitly or otherwise. Permissions that are not explicitly granted are greyed out.
-
Middle pane - Lists ALL application permissions whether granted or not along with a checkbox next to each one to indicate/control the granted state. This is a three state check box:
- Empty - The permission is not granted to the User/Group.
- Half Ticked - The permission has been granted to a Group that the selected User/Group is a member or (directly or otherwise).
- Ticked - The permission has been explicitly granted to the selected User/Group. This pane allows the user to modify the explicit application permissions for the selected user. If a permission is inherited from the membership of a Group, the user may make grant the permission explicitly, but they cannot remove the inherited grant except by modifying the explicit grants of the ancestor group.
-
Bottom pane - Provides the detail for the currently selected permission in the middle pane. If the currently selected User/Group holds the permission indirectly, it will detail which of the ancestor groups have been granted that permission explicitly.
Document Permissions
Permission Names
The permission names have changed as follows:
Use=>Use- Can use a document without being able to view it, e.g. using an Index as part of a search process, but not being able to view the Index.Read=>View- Can see the document in the explorer tree and open it to view its contents.Update=>Edit- Can open and edit documents.Delete=>Delete- Can delete documents.Owner=>Owner- Can change the permissions of the document, e.g. granting access to other Users/Groups. A document can have more than one owner.Ownerwill automatically be granted to a user when they create a document.
Note
Each permission in the list above inherits the permissions of the one above it in the list.A document now has only one permission granted per user (excluding the create permissions).
Previously a User/Group could be granted multiple, e.g. Use and Read.
Now a User/Group can have only one permission or no permission at all, so in the previous example they would now hold View (formally Read).
Document Permissions Screen
A new screen has been added for managing document permissions. It is accessible from:
This screen lists all the documents that the current user has View permission on.
The button can be used to filter the list of documents for making batch changes to the permissions.
The button allows you to make batch changes to the filtered list of Users/Groups.
The Batch Change Permissions screen provides a number of different idempotent operations (i.e. can be repeated with no change in effect) that can be performed.
For example having filtered the list, you could do a Set permission change to grant View permission to user jbloggs.
jbloggs will now have View permission on all documents in that filtered list, regardless of whether they previously had a lower or higher permission.
The options for making batch changes are as follows:
- Set permission - Set a specific User/Group permission.
- Add permission to create - Add permission to create documents in the selected folders.
- Remove permission to create - Remove permission to create documents in the selected folders.
- Add permission to create any document - Add permission to create documents in the selected folders.
- Remove permission to create any document - Remove permission to create documents in the selected folders.
- Add all permissions - Add all permissions from the specified document to the selection.
- Set all permissions - Set all permissions in the selection to be exactly the same as the specified document.
- Remove all permissions for all users [DANGEROUS] - Removes all permissions for all Users/Groups.
When you click Stroom will present a confirmation dialog telling you how many documents will be affected by the change, giving you the opportunity to cancel.
Warning
Batch changes cannot be undone.Document Permissions Sub-Tab
The previous Document Permissions modal dialog has been replaced with a sub-tab on the document screen. It can be accessed by:
- Directly opening the document and selecting the Permissions sub-tab.
- Clicking Permissions in the explorer tree context menu.
- Double clicking the Document in the Document Permissions Screen.
This screen works in a very similar way to the Application Permissions screen.
-
Top pane - Lists the Users and Groups, depending on the selection in the Permission Visibility drop-down.
The Permission Visibility has the following values:
Show Explicit- Shows only those Users/Groups that have at least one document permission explicitly granted to them.Show Effective- Shows only those Users/Groups that have at least one document permission explicitly granted to them or to a group that they are a member of (directly or indirectly).Show All- Shows all Users/Groups regardless of whether any permission is held or not.
The Explicit Permission column shows the permission explicitly granted to the corresponding User/Group.
The Effective Permission column shows the permission effectively granted to the corresponding User/Group, either via explicit grant or inherited from an ancestor Group. The effective permission is what counts when Stroom makes decisions about what a User/Group can do or see.
-
Bottom pane - Shows the permission details for the selected row in the top pane. It will show which ancestor Groups have been explicitly granted any inherited permissions.
Folder Permissions Sub-Tab
Folders are a special kind of document so their Permission sub-tab is slightly different to that on the Document screen.
It can be accessed by:
- Directly opening the Folder and selecting the Permissions sub-tab.
- Clicking Permissions in the explorer tree context menu.
- Double clicking the Folder in the Document Permissions Screen.

The columns are the same as for the Permissions sub-tab of the Document screen except for the addition of:
The Explicit Create Document Types column shows the document create permissions explicitly granted to the corresponding User/Group. It shows each document type as an icon. The hover tooltip will show the type name.
The Effective Create Document Types column shows the document create permissions effectively granted to the corresponding User/Group, either via explicit grant or inherited from an ancestor Group.
User/Group Profile Screen
A new screen has been added to essentially show a user profile for a User/Group. The idea is that it will show everything you might need to know about a User/Group. It is likely that more information relating to a User/Group will be added to this screen in future versions.
A user can view their own profile regardless of permissions, but to view another User or a Group the current User must hold the Manage Users application permission.
The screen is accessible from a number of places:
- The Stroom menu
- From a hover link on the various User/Group related tables.
- From the Actions context menu on the various User/Group related tables.
The following sub-tabs are available:
- Info - Basic information such as their identifiers, name and enabled state.
- User Groups - Lists the Groups that this User/Group is a member of with the ability to join/leave Groups (subject to having Manage Users permission).
- Application Permissions - Lists all application permissions with a check box indicating the grant state.
Very similar to the main Application Permissions screen, without the User/Group list pane.
- Empty - The permission is not granted to the User/Group. The whole row is also greyed out.
- Half Ticked - The permission has been granted to a Group that the selected User/Group is a member or (directly or otherwise).
- Ticked - The permission has been explicitly granted to the selected User/Group.

- Document Permissions - Lists all the documents that the user has visibility with the explicit and inherited permission on each.
The Permission Visibility drop-down has the following values:
Show Explicit- Shows only those documents where the User/Group has a document permission explicitly granted to them.Show Effective- Shows only those documents where the User/Group has a document permission explicitly granted or inherited from an ancestor Group.Show All- Shows all documents that the logged in User can see, regardless of whether any permission is held or not.
- Dependencies - This lists various dependencies on the User/Group, e.g. a Pipeline that is configured to Run As this user.
It is useful in cases where a User is leaving the organisation and administrator needs to see what Stroom content depends on that user.
Currently the following things can appear in the Dependencies sub-tab:
- Pipelines that Run As the User/Group.
- Analytic Rules that Run As the User/Group.
- API Keys - This lists the API Keys held by the User/Group with the ability to create/delete API Keys. Manage API Keys application permission is required to see this sub-tab and to see the logged in User’s own API Keys. Manage Users application permission is required to see this sub-tab for another User/Group.
User/Group Enable State
It is now possible to change the enabled state of a Stroom User. This is as distinct from changing the enabled state of an Account.
This is mostly useful for cases where Stroom is configured to use an external Identity Provider Identity Provider (IDP) An Identity Provider is a system or service that can authenticate a user and assert their identity. Identity providers can support single sign on (SSO), which allows the user to sign in once to the Identity Provider so they are then authenticated to all systems using that IDP.Click to see more details... and an administrator wants to create the Stroom User associated with an IDP user but does not want to allow them to log in yet.
A disabled user will be unable to log in and anything running as the User (e.g. a Pipeline processor filter) will fail.
User Deletion
User/Group deletion has been improved. Deletion of a User/Group will remove them from any Groups and delete any API Keys that they hold. Any documents that are solely owned by them will then be only accessible by an administrator.
It is not possible to delete a User/Group where dependencies exist on that User/Group, e.g. a Pipeline processor filter. The Dependencies sub-tab of the User Profile screen can be used to track down these dependencies prior to deletion.
Pipeline Run As User
The permissions that a Pipeline runs with are now controlled by setting a Run As User/Group on the processor filter. It is advised to use a Group for this as it mitigates against having to change processor filters when a User leaves the organisation.
Viewing Document Dependencies
Previously, the Dependencies and Dependants items in the explorer tree context menu were only available if the logged in User had Owner permission on the selected Document.
Now the User only needs View permission to see the dependences/dependants.
User Account Creation
When a Stroom User Account is created it will now create the corresponding Stroom User record. Previously this was a two step process. This is only applicable when using the internal Identity Provider Identity Provider (IDP) An Identity Provider is a system or service that can authenticate a user and assert their identity. Identity providers can support single sign on (SSO), which allows the user to sign in once to the Identity Provider so they are then authenticated to all systems using that IDP.Click to see more details....
Analytic Email Notifications
Now when a failure occurs sending an email notification for an Analytic Rule , the error will be written to the configured error Feed .
8.2 - Preview Features (experimental)
There are no preview features in v7.6.
8.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.There are no breaking changes in v7.6.
8.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom instance.Java Version
Stroom v7.6 requires Java 21. This is the same java version as Stroom v7.5. Ensure the Stroom and Stroom-Proxy hosts are running the latest patch release of Java v21.
Configuration File Changes
Stroom’s config.yml
The following changes have been made to the configuration file.
Added Property Trees
The following cache configuration property trees have been added.
appPermissionIdCache.*docTypeIdCache.*userAppPermissionsCache.*userInfoByUuidCache.*
Removed Property Trees
The following cache configuration property trees have been removed.
userAppPermissionsCache.*userByDisplayNameCache.*
Stroom-Proxy’s config.yml
No changes have been made configuration file.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Warning
If you are upgrading from a previous v7.6 beta release you will need to run the following SQL.
This release migrates all the existing document and application permission grants into new tables (prefixed by permission_).
The legacy tables doc_permission and app_permission have been left untouched to allow migrated permissions to be compared against the previous state.
In some future version of Stroom these tables will be removed.
Migration Scripts
For information purposes only, the following are the database migrations that will be run when upgrading to 7.6.0 from the previous minor version.
Note, the legacy module will run first (if present) then the other module will run in no particular order.
Module stroom-activity
Script V07_06_00_200__activity_pre_migration_checks.java
Path: stroom-activity/stroom-activity-impl-db/src/main/java/stroom/activity/impl/db/migration/V07_06_00_200__activity_pre_migration_checks.java
It is not possible to display the content here. The file can be viewed on : GitHub
Script V07_06_00_205__activity_user_uuid.sql
Path: stroom-activity/stroom-activity-impl-db/src/main/resources/stroom/activity/impl/db/migration/V07_06_00_205__activity_user_uuid.sql
-- ------------------------------------------------------------------------
-- Copyright 2023 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP PROCEDURE IF EXISTS V07_06_00_205__activity_user_uuid;
DELIMITER $$
CREATE PROCEDURE V07_06_00_205__activity_user_uuid ()
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'activity'
AND column_name = 'user_uuid';
IF object_count = 0 THEN
ALTER TABLE activity ADD COLUMN user_uuid varchar(255) NOT NULL;
SELECT COUNT(1)
INTO object_count
FROM information_schema.tables
WHERE table_schema = database()
AND table_name = 'stroom_user';
IF object_count = 1 THEN
SET @sql_str = CONCAT(
'UPDATE activity a, stroom_user s ',
'SET a.user_uuid = s.uuid ',
'WHERE a.user_id = s.name');
PREPARE stmt FROM @sql_str;
EXECUTE stmt;
END IF;
ALTER TABLE activity DROP COLUMN user_id;
END IF;
END $$
DELIMITER ;
CALL V07_06_00_205__activity_user_uuid;
DROP PROCEDURE IF EXISTS V07_06_00_205__activity_user_uuid;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Module stroom-analytics
Script V07_06_00_405__execution_schedule_run_as_user_uuid.sql
Path: stroom-analytics/stroom-analytics-impl-db/src/main/resources/stroom/analytics/impl/db/migration/V07_06_00_405__execution_schedule_run_as_user_uuid.sql
-- ------------------------------------------------------------------------
-- Copyright 2023 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP PROCEDURE IF EXISTS V07_06_00_405__execution_schedule_run_as_user_uuid;
DELIMITER $$
CREATE PROCEDURE V07_06_00_405__execution_schedule_run_as_user_uuid ()
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'execution_schedule'
AND column_name = 'run_as_user_uuid';
IF object_count = 0 THEN
ALTER TABLE execution_schedule ADD COLUMN run_as_user_uuid varchar(255) DEFAULT NULL;
-- The now legacy doc_permission table may be removed at some later point
-- in which case we don't have to do anything
SELECT COUNT(1)
INTO object_count
FROM information_schema.tables
WHERE table_schema = database()
AND table_name = 'doc_permission';
IF object_count = 1 THEN
SET @sql_str = CONCAT(
'UPDATE execution_schedule es ',
'INNER JOIN ( ',
' SELECT DISTINCT ',
' dp.doc_uuid, ',
' FIRST_VALUE(dp.user_uuid) ',
' OVER (PARTITION BY dp.doc_uuid ORDER BY dp.id DESC) latest_owner_uuid ',
' FROM doc_permission dp ',
' WHERE dp.permission = "Owner" ',
') as dpv on dpv.doc_uuid = es.doc_uuid ',
'SET es.run_as_user_uuid = dpv.latest_owner_uuid;');
PREPARE stmt FROM @sql_str;
EXECUTE stmt;
END IF;
END IF;
END $$
DELIMITER ;
CALL V07_06_00_405__execution_schedule_run_as_user_uuid;
DROP PROCEDURE IF EXISTS V07_06_00_405__execution_schedule_run_as_user_uuid;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Module stroom-annotation
Script V07_06_00_100__annotation_pre_migration_checks.java
Path: stroom-annotation/stroom-annotation-impl-db/src/main/java/stroom/annotation/impl/db/migration/V07_06_00_100__annotation_pre_migration_checks.java
It is not possible to display the content here. The file can be viewed on : GitHub
Script V07_06_00_105__annotation_uuid.sql
Path: stroom-annotation/stroom-annotation-impl-db/src/main/resources/stroom/annotation/impl/db/migration/V07_06_00_105__annotation_uuid.sql
-- ------------------------------------------------------------------------
-- Copyright 2023 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP PROCEDURE IF EXISTS V07_06_00_105_annotation;
DELIMITER $$
CREATE PROCEDURE V07_06_00_105_annotation ()
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation'
AND column_name = 'uuid';
IF object_count = 0 THEN
ALTER TABLE `annotation`
ADD COLUMN `uuid` varchar(255) NOT NULL;
UPDATE `annotation` set `uuid` = MID(UUID(),1,36);
CREATE UNIQUE INDEX `annotation_uuid` ON `annotation` (`uuid`);
END IF;
END $$
DELIMITER ;
CALL V07_06_00_105_annotation;
DROP PROCEDURE IF EXISTS V07_06_00_105_annotation;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Script V07_06_00_110__annotation_entry.sql
Path: stroom-annotation/stroom-annotation-impl-db/src/main/resources/stroom/annotation/impl/db/migration/V07_06_00_110__annotation_entry.sql
-- ------------------------------------------------------------------------
-- Copyright 2023 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP PROCEDURE IF EXISTS V07_06_00_110__annotation_entry;
DELIMITER $$
CREATE PROCEDURE V07_06_00_110__annotation_entry ()
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'annotation_entry'
AND column_name = 'entry_user_uuid';
IF object_count = 0 THEN
ALTER TABLE annotation_entry ADD COLUMN entry_user_uuid varchar(255) DEFAULT NULL;
ALTER TABLE annotation_entry ADD COLUMN entry_time_ms bigint NOT NULL;
SELECT COUNT(1)
INTO object_count
FROM information_schema.tables
WHERE table_schema = database()
AND table_name = 'stroom_user';
IF object_count = 1 THEN
-- Change create user names to entry user uuids.
SET @sql_str = CONCAT(
'UPDATE annotation_entry a, stroom_user s ',
'SET a.entry_user_uuid = s.uuid ',
'WHERE a.create_user = s.name');
PREPARE stmt FROM @sql_str;
EXECUTE stmt;
-- Move all create times to entry times.
SET @sql_str = CONCAT(
'UPDATE annotation_entry a ',
'SET a.entry_time_ms = a.create_time_ms');
PREPARE stmt FROM @sql_str;
EXECUTE stmt;
-- Change all assignment entries to reference user UUID instead of name.
SET @sql_str = CONCAT(
'UPDATE annotation_entry a, stroom_user s ',
'SET a.data = s.uuid ',
'WHERE a.type = "Assigned" AND a.data = s.name');
PREPARE stmt FROM @sql_str;
EXECUTE stmt;
END IF;
ALTER TABLE annotation_entry DROP COLUMN version;
ALTER TABLE annotation_entry DROP COLUMN create_time_ms;
ALTER TABLE annotation_entry DROP COLUMN create_user;
ALTER TABLE annotation_entry DROP COLUMN update_time_ms;
ALTER TABLE annotation_entry DROP COLUMN update_user;
END IF;
END $$
DELIMITER ;
CALL V07_06_00_110__annotation_entry;
DROP PROCEDURE IF EXISTS V07_06_00_110__annotation_entry;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Module stroom-processor
Script V07_06_00_300__processor_filter_pre_migration_checks.java
Path: stroom-processor/stroom-processor-impl-db/src/main/java/stroom/processor/impl/db/migration/V07_06_00_300__processor_filter_pre_migration_checks.java
It is not possible to display the content here. The file can be viewed on : GitHub
Script V07_06_00_305__processor_filter_run_as_user_uuid.sql
Path: stroom-processor/stroom-processor-impl-db/src/main/resources/stroom/processor/impl/db/migration/V07_06_00_305__processor_filter_run_as_user_uuid.sql
-- ------------------------------------------------------------------------
-- Copyright 2023 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP PROCEDURE IF EXISTS V07_06_00_305__processor_filter_run_as_user_uuid;
DELIMITER $$
CREATE PROCEDURE V07_06_00_305__processor_filter_run_as_user_uuid ()
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'processor_filter'
AND column_name = 'run_as_user_uuid';
IF object_count = 0 THEN
ALTER TABLE processor_filter ADD COLUMN run_as_user_uuid varchar(255) DEFAULT NULL;
SELECT COUNT(1)
INTO object_count
FROM information_schema.tables
WHERE table_schema = database()
AND table_name = 'doc_permission';
IF object_count = 1 THEN
SET @sql_str = CONCAT(
'UPDATE processor_filter pf ',
'INNER JOIN ( ',
' SELECT DISTINCT ',
' dp.doc_uuid, ',
' FIRST_VALUE(dp.user_uuid) '
' OVER (PARTITION BY dp.doc_uuid ORDER BY dp.id DESC) latest_owner_uuid ',
' FROM doc_permission dp ',
' WHERE dp.permission = "Owner" ',
') as dpv on dpv.doc_uuid = pf.uuid ',
'SET pf.run_as_user_uuid = dpv.latest_owner_uuid; ');
PREPARE stmt FROM @sql_str;
EXECUTE stmt;
END IF;
END IF;
END $$
DELIMITER ;
CALL V07_06_00_305__processor_filter_run_as_user_uuid;
DROP PROCEDURE IF EXISTS V07_06_00_305__processor_filter_run_as_user_uuid;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Module stroom-security
Script V07_06_00_800__app_permission.sql
Path: stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_06_00_800__app_permission.sql
-- ------------------------------------------------------------------------
-- Copyright 2024 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP TABLE IF EXISTS `permission_app`;
DROP TABLE IF EXISTS `permission_app_id`;
--
-- Create the application permission id table
--
CREATE TABLE IF NOT EXISTS `permission_app_id` (
`id` tinyint UNSIGNED NOT NULL AUTO_INCREMENT,
`permission` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `permission_app_id_permission_idx` (`permission`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
--
-- Add app permission names into the app permission id table.
--
INSERT INTO `permission_app_id` (`permission`)
SELECT DISTINCT(permission)
FROM app_permission;
--
-- Create the new application permission table.
--
CREATE TABLE IF NOT EXISTS `permission_app` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_uuid` varchar(255) NOT NULL,
`permission_id` tinyint UNSIGNED NOT NULL,
PRIMARY KEY (`id`),
KEY `permission_app_user_uuid` (`user_uuid`),
UNIQUE KEY `permission_app_user_uuid_permission_id_idx` (`user_uuid`,`permission_id`),
CONSTRAINT `permission_app_user_uuid` FOREIGN KEY (`user_uuid`) REFERENCES `stroom_user` (`uuid`),
CONSTRAINT `permission_app_permission_id` FOREIGN KEY (`permission_id`) REFERENCES `permission_app_id` (`id`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
--
-- Copy permission values to the new table.
--
INSERT INTO permission_app (user_uuid, permission_id)
SELECT ap.user_uuid, pai.id
FROM app_permission ap
JOIN permission_app_id pai
ON (pai.permission = ap.permission);
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Script V07_06_00_900__doc_permission.sql
Path: stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_06_00_900__doc_permission.sql
-- ------------------------------------------------------------------------
-- Copyright 2024 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP TABLE IF EXISTS `permission_doc`;
DROP TABLE IF EXISTS `permission_doc_id`;
DROP TABLE IF EXISTS `permission_doc_create`;
DROP TABLE IF EXISTS `permission_doc_type_id`;
--
-- Create the permission id table
--
CREATE TABLE IF NOT EXISTS `permission_doc_id` (
`id` tinyint UNSIGNED NOT NULL,
`permission` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `permission_doc_id_permission_idx` (`permission`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
--
-- Add permission names into the id table.
--
INSERT INTO `permission_doc_id` (`id`, `permission`)
VALUES
(10, "Use"),
(20, "Read"),
(30, "Update"),
(40, "Delete"),
(50, "Owner");
--
-- Create the new permission table.
--
CREATE TABLE IF NOT EXISTS `permission_doc` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_uuid` varchar(255) NOT NULL,
`doc_uuid` varchar(255) NOT NULL,
`permission_id` tinyint UNSIGNED NOT NULL,
PRIMARY KEY (`id`),
KEY `permission_doc_user_uuid` (`user_uuid`),
KEY `permission_doc_doc_uuid` (`doc_uuid`),
UNIQUE KEY `permission_doc_user_uuid_doc_uuid_idx` (`user_uuid`,`doc_uuid`),
CONSTRAINT `permission_doc_user_uuid` FOREIGN KEY (`user_uuid`) REFERENCES `stroom_user` (`uuid`),
CONSTRAINT `permission_doc_permission_id` FOREIGN KEY (`permission_id`) REFERENCES `permission_doc_id` (`id`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
--
-- Copy permission values to the new table.
--
INSERT INTO permission_doc (user_uuid, doc_uuid, permission_id)
SELECT dp.user_uuid, dp.doc_uuid, MAX(pdi.id)
FROM doc_permission dp
JOIN permission_doc_id pdi
ON (pdi.permission = dp.permission)
WHERE dp.permission IN ("Owner", "Delete", "Update", "Read", "Use")
GROUP BY dp.user_uuid, dp.doc_uuid;
--
-- Modify the permission names.
--
UPDATE `permission_doc_id`
SET `permission` = "View"
WHERE `permission` = "Read";
UPDATE `permission_doc_id`
SET `permission` = "Edit"
WHERE `permission` = "Update";
--
-- Create the document type id table
--
CREATE TABLE IF NOT EXISTS `permission_doc_type_id` (
`id` tinyint UNSIGNED NOT NULL AUTO_INCREMENT,
`type` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `permission_doc_type_id_type_idx` (`type`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
--
-- Add document type names into the doc type id table.
--
INSERT INTO `permission_doc_type_id` (`type`)
SELECT DISTINCT(SUBSTRING(permission, 10))
FROM doc_permission
WHERE permission LIKE "Create - %";
--
-- Create the new document create permission table.
--
CREATE TABLE IF NOT EXISTS `permission_doc_create` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_uuid` varchar(255) NOT NULL,
`doc_uuid` varchar(255) NOT NULL,
`doc_type_id` tinyint UNSIGNED NOT NULL,
PRIMARY KEY (`id`),
KEY `permission_doc_create_user_uuid` (`user_uuid`),
KEY `permission_doc_create_doc_uuid` (`doc_uuid`),
KEY `permission_doc_create_doc_type_id` (`doc_type_id`),
UNIQUE KEY `permission_doc_create_user_uuid_doc_uuid_doc_type_id_idx` (`user_uuid`,`doc_uuid`, `doc_type_id`),
CONSTRAINT `permission_doc_create_user_uuid` FOREIGN KEY (`user_uuid`) REFERENCES `stroom_user` (`uuid`),
CONSTRAINT `permission_doc_create_doc_type_id` FOREIGN KEY (`doc_type_id`) REFERENCES `permission_doc_type_id` (`id`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
--
-- Copy document create permission values to the new table.
--
INSERT INTO permission_doc_create (user_uuid, doc_uuid, doc_type_id)
SELECT dp.user_uuid, dp.doc_uuid, pdti.id
FROM doc_permission dp
JOIN permission_doc_type_id pdti
ON (pdti.type = SUBSTRING(dp.permission, 10))
WHERE dp.permission LIKE "Create - %";
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Script V07_06_00_905__user_display_name.sql
Path: stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_06_00_905__user_display_name.sql
-- ------------------------------------------------------------------------
-- Copyright 2024 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- Idempotent
-- Ensure we always have a display_name value
UPDATE `stroom_user`
SET `display_name` = `name`
WHERE `display_name` IS NULL
OR LENGTH(`display_name`) = 0;
-- Idempotent
-- Now make the col non null so can rely on a value being there
ALTER TABLE `stroom_user` MODIFY `display_name` VARCHAR(255) NOT NULL;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Script V07_06_00_910__user_add_deleted_col.sql
Path: stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_06_00_910__user_add_deleted_col.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- --------------------------------------------------
-- An archive of the last known values of name, display_name, full_name and is_group for a given
-- uuid. No constraint on name to allow for stroom_user records being deleted and re-used with
-- a different uuid.
CREATE TABLE IF NOT EXISTS `stroom_user_archive` (
`id` int NOT NULL AUTO_INCREMENT,
`uuid` varchar(255) NOT NULL,
`name` varchar(255) NOT NULL,
`display_name` varchar(255) NOT NULL,
`full_name` varchar(255) DEFAULT NULL,
`is_group` tinyint NOT NULL DEFAULT 0,
PRIMARY KEY (`id`),
UNIQUE KEY `stroom_user_archive_uuid_idx` (`uuid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- Idempotent
-- Populate the new table based on what we currently have in the stroom_user table
INSERT INTO stroom_user_archive (
uuid,
name,
display_name,
full_name,
is_group)
SELECT
su.uuid,
su.name,
su.display_name,
su.full_name,
su.is_group
FROM stroom_user su
ON DUPLICATE KEY UPDATE
uuid = su.uuid,
name = su.name,
display_name = su.display_name,
full_name = su.full_name,
is_group = su.is_group;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set tabstop=4 shiftwidth=4 expandtab:
Script V07_06_00_915__drop_foreign_keys_to_stroom_user.sql
Path: stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_06_00_915__drop_foreign_keys_to_stroom_user.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- --------------------------------------------------
DELIMITER $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS security_run_sql_v1 $$
-- DO NOT change this without reading the header!
CREATE PROCEDURE security_run_sql_v1 (
p_sql_stmt varchar(1000)
)
BEGIN
SET @sqlstmt = p_sql_stmt;
SELECT CONCAT('Running sql: ', @sqlstmt);
PREPARE stmt FROM @sqlstmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS security_drop_constraint_v1 $$
-- e.g. security_drop_constraint_v1('MY_TABLE', 'MY_FK', 'FOREIGN KEY');
-- security_drop_constraint_v1('MY_TABLE', 'MY_UNIQ_IDX', 'INDEX');
-- security_drop_constraint_v1('MY_TABLE', 'PRIMARY', 'INDEX');
-- DO NOT change this without reading the header!
CREATE PROCEDURE security_drop_constraint_v1 (
p_table_name varchar(64),
p_constraint_name varchar(64),
p_constraint_type varchar(64) -- e.g. FOREIGN KEY | UNIQUE
)
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.table_constraints
WHERE table_schema = database()
AND table_name = p_table_name
AND constraint_name = p_constraint_name;
IF object_count = 0 THEN
SELECT CONCAT(
'Constraint ',
p_constraint_name,
' does not exist on table ',
database(),
'.',
p_table_name);
ELSE
CALL security_run_sql_v1(CONCAT(
'alter table ', database(), '.', p_table_name,
' drop ', p_constraint_type, ' ', p_constraint_name));
END IF;
END $$
DELIMITER ;
-- --------------------------------------------------
CALL security_drop_constraint_v1(
'app_permission',
'app_permission_user_uuid',
'FOREIGN KEY');
CALL security_drop_constraint_v1(
'doc_permission',
'doc_permission_fk_user_uuid',
'FOREIGN KEY');
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS security_run_sql_v1;
DROP PROCEDURE IF EXISTS security_drop_constraint_v1;
-- --------------------------------------------------
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set tabstop=4 shiftwidth=4 expandtab:
8.5 - Change Log
-
Issue #4671 : Remove foreign key constraints from the legacy
(app|doc)_permissiontables tostroom_userto fix user deletion. -
Issue #4670 : Fix display of disabled users in multiple permission related screens.
-
Issue #4659 : Fix refresh selection changes after adding/removing users to/from groups.
-
Issue #4594 : Various changes to the permissions screens. Added a new User screen to show all a user’s permissions, api keys, and dependencies. Added links between the various permission and user screens. Improved the tables of some of the permissions screens.
-
Fix
java.lang.NoClassDeffoundError: jakarta/el/ELManagererror when booting proxy. -
Fix error when creating a document as a user without
AdministratororManager Users. -
Issue #4588 : Fix the API allowing documents to be moved with only VIEW permission. The UI requires EDIT permission. The API is now in line with that.
-
Fix the
Copy Asmenu item for ancestor folders that the user does not have VIEW permission on. For these cases, theCopy Assub menu now only displays theCopy as nameentry. -
Change the explorer context menu to include the entries for
DependenciesandDependantsif the user has at least VIEW permission. Previously required OWNER. -
Issue #4586 : Fix error when changing filter on Document Permissions Report.
-
Make account creation also create a stroom user. Make an update to an account also update the stroom user if the full name has changed.
-
Fix bug in DB migration
V07_06_00_100__annotation_pre_migration_checks. -
If you are upgrading from a previous v7.6 beta release you will need to run the following SQL.
update analytics_schema_history set checksum = '-86554219' where version = '07.06.00.405';andupdate processor_schema_history set checksum = '-175036745' where version = '07.06.00.305';. -
Issue #4550 : Fix datasource already in use issue.
-
Uplift docker image JDK to
eclipse-temurin:21.0.5_11-jdk-alpine. -
Issue #4580 : Auto add a permission user when an account is created.
-
Issue #4582 : Show all users by default and not just ones with explicit permissions.
-
Issue #4345 : Write analytic email notification failures to the analytic error feed.
-
Issue #4379 : Improve Stroom permission model.
For a detailed list of all the changes in v7.6 see: v7.6 CHANGELOG
9 - Version 7.5
9.1 - New Features
This section contains the significant new features or changes in Stroom. For a full list of changes see Change Log.
User Interface
Jobs Screen
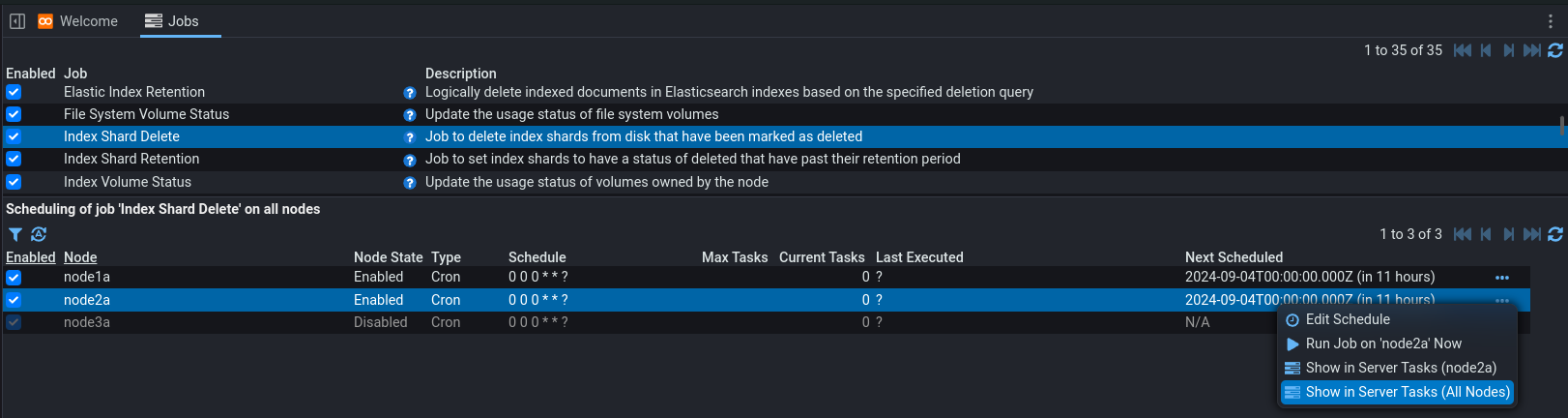
-
Rows are now greyed out if one of the following is true:
-
The parent job is disabled.
-
The job is disabled on a specific node.
-
The node itself is disabled.
-
-
The column Next Scheduled has been added to the detail pane to show the time that the job will next run.
-
The details pane now has an Actions menu () where it is possible to do the follow actions to a job on a specific node.
-
Edit the schedule for job on the selected node.
-
Run the job on the selected node now. This will run the job within 10s or so once clicked. Monitor the Last Executed column to see when it has run.
-
Show in Server Tasks (selected node). This will open the Server Tasks screen with the quick filter set to the selected job and node.
-
Show in Server Tasks (all nodes). This will open the Server Tasks screen with the quick filter set to the selected job.
It is now possible to link directly to the Nodes screen by clicking the Open hover button next to the node name.
-
Nodes Screen
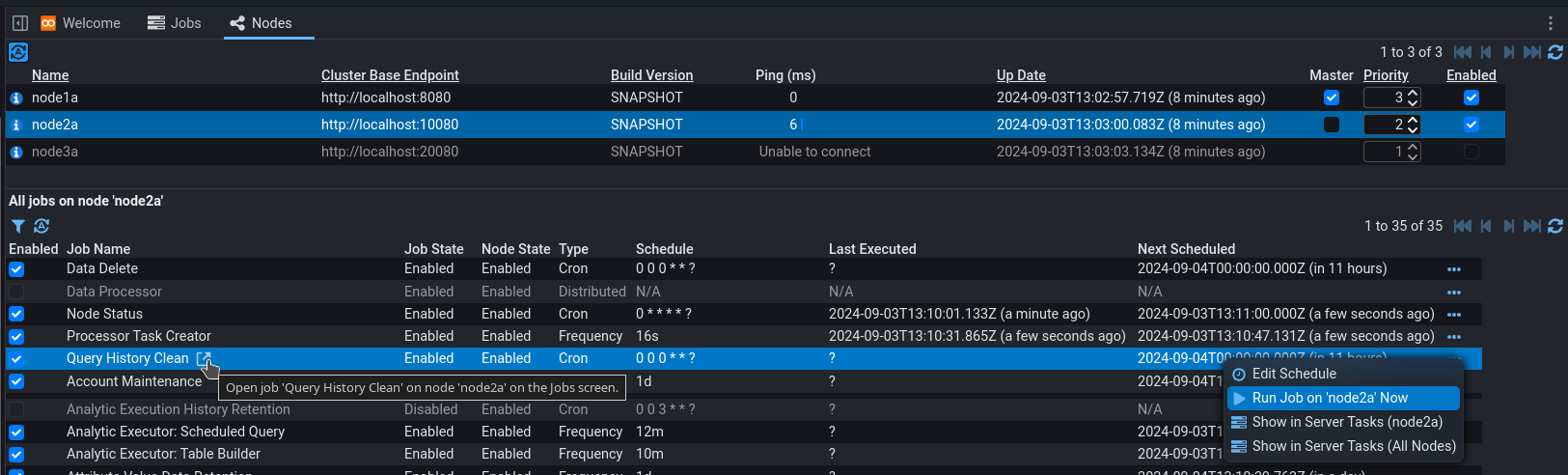
-
A jobs detail pane has been added to show the jobs on that node. This shows all jobs and allows jobs to be enabled/disabled on a node. It also shows the state of the parent job and the node. The button can be used to show only the enabled jobs on that node.
An auto-refresh button has also been added to keep refreshing the jobs detail pane so the Last Executed and Next Scheduled columns are updated.
It is also possible to link directly to the Jobs screen by clicking the Open hover button next to the job name.
-
Nodes rows are now greyed out if the node is disabled.
-
Job rows are not greyed out if one of the following is true:
- The node is disabled.
- The parent job is disabled.
- The job is disabled on a specific node.
-
The column Build Version has been added to show the version of Stroom that the node is running. This is to highlight any nodes running the wrong version.
-
The column Up Date has been added to the Nodes screen to show the time that Stroom was last booted on that node.
-
The Ping column screen has been changed so an enabled node with no ping stands out while a disabled node does not.
New Look and Feel
The Login, Change Password and Manage Accounts screens have been changed to bring their look and feel in line with the rest of the application. The screens may look a little different but are functionally the same.

Dictionaries
The Dictionary screen has been changed to make it easier to manage the import of other Dictionaries.
The Import sub-tab has been changed to include a detail pane that shows the effective word list for each imported Dictionary. This will show all words in the imported dictionary along with any from Dictionaries that it imports from.
A Effective Words sub-tab has been added to show the effective list of words in the Dictionary, i.e. combining all words from the dictionary, its imports and any dictionaries imported by those imports.
Authentication Error Screen
If there is an authentication error during user login, e.g. the account is disabled or locked, the user will now be redirected to a configurable error screen rather than back to the login screen.
The content of the lower part of the dialog is configurable via the property stroom.ui.authErrorMessage.
This property accepts HTML content.
This allows the message to contain details of how to contact the appropriate Stroom admin team.
Queries
Editor Code Completion
The code completion in the Query editor has been changed to make the code completion suggestions context aware.
For example if you have just typed in dictionary and then hit
Ctrl ^
+
Space ␣
it will suggest the names of Dictionary documents that are visible to the user.
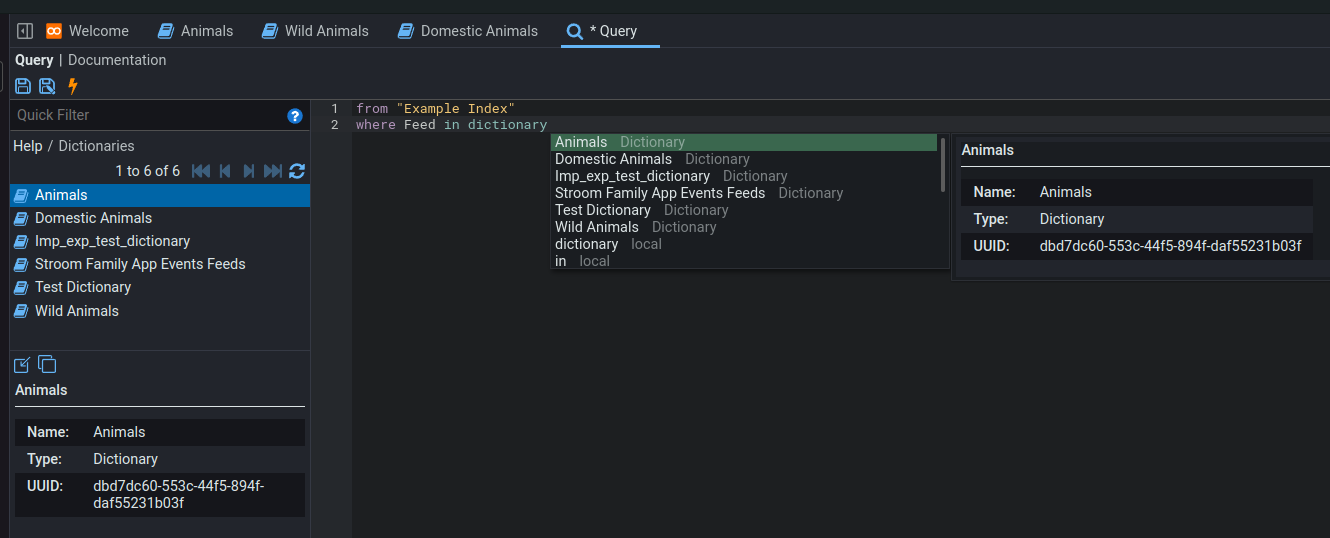
Dictionaries and Visualisations have also been added to the list of Query Help items (in the left hand pane) and to the available code completions.
Table Download
You can now download the results of a Query using the icon.
Functions in select
Functions, e.g. count() can now be used within the select clause of a StroomQL query.
Dashboards
Sorting
Now when you change an existing table sort on a dashboard it does not require the query to be executed again. The table data will change to reflect the new sort settings. This is particularly useful on complex queries or those operating on large amounts of data.
Dictionary List Input
When using a List Input pane on a Dashboard that is configured with a Dictionary , the drop-down now shows the source of each Dictionary word.
Other UI Changes
-
The explorer tree now shows the name of the item in the hover tooltip. This is useful if the name extends beyond the limit of the explorer tree pane.
-
Issue #4339 : Allow user selection of analytic duplicate columns.
-
Issue #3989 : Improve pause behaviour in dashboards and general presentation of
busystate throughout UI. -
The way dialogs can be moved or resized has been improved so that they can be resized on any edge or corner. The area for clicking and dragging to move a dialog has been increased to include all of the title section.
Permissions
-
Document deletion will now also delete all associated document permissions granted to user/groups. This previously did not happen on document delete so orphaned document permissions would build up in the database.
The DB migration
V07_04_00_005__Orphaned_Doc_Permswhich will delete all document permissions (in tabledoc_permission) for docs that are not a folder, not the System doc, are not a valid doc (i.e. in thedoctable) and are not a pipeline filter. Deleted document permission records will first be copied to a backup tabledoc_permission_backup_V07_04_00_005. -
Document Copy and Move has been changed to check that the user has Owner permission (or admin) on the document being copied/moved if the permissions mode is None, Destination or Combined. This is because those modes will change the permissions which is something only an Owner/admin can do.
Note
Significant changes to document permissions are coming in v7.6.Content Search
The Find in Content screen added in v7.3 has been changed to add Lucene indexing to speed up content searches. The Lucene index will be created when a user first uses the content search. The user may see an error message on first use telling them to wait for the index to be built.
The index is located in <stroom.path.temp>/doc-index, which unless explicitly configured will likely be /tmp/doc-index.
Volumes
-
The tables on the Data Volumes and Index Volumes screens have been changed to low-light
CLOSED/INACTIVEvolumes. -
Tooltips have been added to the Path and Last Updated columns.
-
The Use% column has been changed to a percentage bar.
-
Red/green colouring has been added to the to the Full column values to make it clearer which volumes are full.
Dependency Documents
Missing Dependencies
Various screens include document pickers to select a dependency document, e.g. selecting an extraction Pipeline in the Dashboard table settings. The document picker will now show a icon to indicate the previously selected document is not longer visible to the user or has been deleted.
Tagged Documents
Various screens require the selection of an extraction, or reference loader Pipeline, i.e.:
- View - Extraction pipeline
- Index - Default extraction pipeline
- Dashboard - Extraction Pipeline
- Pipeline - Reference loader pipeline
To distinguish processing pipelines from extraction or reference loading pipelines, the Pipeline documents can be tagged with pre-configured tags such as extraction and reference-loader.
This means the Pipeline picker screen can be pre-filtered on the appropriate tag to make finding the right document easier.
It is recommended to tag all such pipelines using these tags to make document selection easier for other users.
This system defined tagging is configured using the following properties
stroom.explorer.suggestedTagsstroom.ui.query.dashboardPipelineSelectorIncludedTagsstroom.ui.query.indexPipelineSelectorIncludedTagsstroom.ui.query.viewPipelineSelectorIncludedTagsstroom.ui.referencePipelineSelectorIncludedTags
API Keys
The API keys screen has changed to allow selection of the hashing algorithm used to store a hash of the API key.
Processing
S3 Appender
A new S3 pipeline element S3Appender has been added to enable the streaming of data to an S3 bucket.
The S3 Appender requires the creation of an S3 Config document to provide the credentials and role details for connecting to the S3 bucket. The content of the S3 Config document is JSON and the JSON Schema describing its structure can be found here .
Stepping
The stepper has been changed to allow termination of the step. This is useful when stepping large streams or when using filtered steps.
The fact that the step is in progress is indicated by a label above the pipeline elements.
Other Changes
- Issue
#4444
: Change the
hash()expression function to allow thealgorithmandsaltarguments to be the result of functions rather than just static values, e.g.hash(${field1}, concat('SHA-', ${algoLen}), ${salt}).
9.2 - Preview Features (experimental)
State Store
TODO
Work in progress- Issue #2126 : Add experimental state store.
9.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.There are no breaking changes in v7.5.
9.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom instance.Java Version
Stroom v7.5 requires Java 21. This is the same java version as Stroom v7.4. Ensure the Stroom and Stroom-Proxy hosts are running the latest patch release of Java v21.
Configuration File Changes
The following changes requiring action have been made to the stroom.yml configuration file.
Removed Properties
stroom.ui.theme.backgroundColour
This property has been removed. You will need to remove it (if present) from your configuration files else Stroom will not boot.
New Properties
stroom.contentIndex
This property has been added. It enables the indexing of stroom content for fast content searching.
state.*
This block of properties has been added to control the new state store functionality.
appConfig:
state:
scyllaDbDocCache:
expireAfterAccess: null
expireAfterWrite: "PT10M"
maximumSize: 100
refreshAfterWrite: null
sessionCache:
expireAfterAccess: "PT1H"
expireAfterWrite: null
maximumSize: 10
refreshAfterWrite: null
stateDocCache:
expireAfterAccess: null
expireAfterWrite: "PT10M"
maximumSize: 100
refreshAfterWrite: null
Changed Property Values
stroom.ui.helpSubPathJobs
The value of this property has changed from /user-guide/jobs/ to /reference-section/jobs/.
stroom.ui.helpUrl
The value of this property has changed from https://gchq.github.io/stroom-docs/7.4/docs to https://gchq.github.io/stroom-docs/7.5/docs.
Servlets
Stroom presents various servlets. The paths to these servlets have changed but the existing paths remain.
Warning
While the old paths still work, they will be removed in a future version of Stroom so you are advised to change any scripts or similar that point to these servlets./stroom/noauth/datafeed=>/datafeed/stroom/noauth/debug=>/debug/stroom/noauth/echo=>/echo/stroom/noauth/status=>/status/stroom/noauth/swagger-ui=>/swagger-ui/stroom/sessionList=>/sessionList
Note
These servlet paths are those presented by the stroom application itself. Stroom may be fronted by nginx in which case that may already be doing path mapping to abstract the end client from Stroom’s servlet paths.The /sessionList (and /stroom/sessionList) servlet has been changed to require manage users permission.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Warning
If you are upgrading a v7.5 Stroom instance that has a version less than or equal to v7.5-beta.9 to a version higher than v7.5-beta.9 then you must run the following SQL on the database to correct the renaming of a migration script. If you don’t, Stroom will not boot as it will detect a mismatch in the DB migration scripts.
Migration Scripts
For information purposes only, the following are the database migrations that will be run when upgrading to 7.5.0 from the previous minor version.
Note, the legacy module will run first (if present) then the other module will run in no particular order.
Module stroom-app
Script V07_05_00_005__Orphaned_Doc_Perms.java
Path: stroom-app/src/main/java/stroom/app/db/migration/V07_05_00_005__Orphaned_Doc_Perms.java
It is not possible to display the content here. The file can be viewed on : GitHub
Module stroom-docstore
Script V07_05_00_005__Add_index_on_doc.sql
Path: stroom-docstore/stroom-docstore-impl-db/src/main/resources/stroom/docstore/impl/db/migration/V07_05_00_005__Add_index_on_doc.sql
-- ------------------------------------------------------------------------
-- Copyright 2022 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- stop note level warnings about objects (not)? existing
SET @old_sql_notes=@@sql_notes, sql_notes=0;
-- --------------------------------------------------
DELIMITER $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS docstore_run_sql $$
-- DO NOT change this without reading the header!
CREATE PROCEDURE docstore_run_sql (
p_sql_stmt varchar(1000)
)
BEGIN
SET @sqlstmt = p_sql_stmt;
SELECT CONCAT('Running sql: ', @sqlstmt);
PREPARE stmt FROM @sqlstmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS docstore_create_non_unique_index$$
-- DO NOT change this without reading the header!
CREATE PROCEDURE docstore_create_non_unique_index (
p_table_name varchar(64),
p_index_name varchar(64),
p_index_columns varchar(64)
)
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.statistics
WHERE table_schema = database()
AND table_name = p_table_name
AND index_name = p_index_name;
IF object_count = 0 THEN
CALL docstore_run_sql(CONCAT(
'create index ', p_index_name,
' on ', database(), '.', p_table_name,
' (', p_index_columns, ')'));
ELSE
SELECT CONCAT(
'Index ',
p_index_name,
' already exists on table ',
database(),
'.',
p_table_name);
END IF;
END $$
-- --------------------------------------------------
DELIMITER ;
-- --------------------------------------------------
-- Improve lookup by name and to remove need to hit the table when we
-- list all docs by type.
CALL docstore_create_non_unique_index(
"doc",
"doc_type_name_uuid_idx",
"type, name, uuid");
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS docstore_create_non_unique_index;
DROP PROCEDURE IF EXISTS docstore_run_sql;
-- --------------------------------------------------
-- Reset to the original value
SET SQL_NOTES=@OLD_SQL_NOTES;
Module stroom-node
Script V07_05_00_005__add_build_ver_last_boot.sql
Path: stroom-node/stroom-node-impl-db/src/main/resources/stroom/node/impl/db/migration/V07_05_00_005__add_build_ver_last_boot.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- --------------------------------------------------
DELIMITER $$
DROP PROCEDURE IF EXISTS node_run_sql_v1 $$
-- DO NOT change this without reading the header!
CREATE PROCEDURE node_run_sql_v1 (
p_sql_stmt varchar(1000)
)
BEGIN
SET @sqlstmt = p_sql_stmt;
SELECT CONCAT('Running sql: ', @sqlstmt);
PREPARE stmt FROM @sqlstmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS node_add_column_v1$$
CREATE PROCEDURE node_add_column_v1 (
p_table_name varchar(64),
p_column_name varchar(64),
p_column_type_info varchar(64) -- e.g. 'varchar(255) default NULL'
)
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = p_table_name
AND column_name = p_column_name;
IF object_count = 0 THEN
CALL node_run_sql_v1(CONCAT(
'alter table ', database(), '.', p_table_name,
' add column ', p_column_name, ' ', p_column_type_info));
ELSE
SELECT CONCAT(
'Column ',
p_column_name,
' already exists on table ',
database(),
'.',
p_table_name);
END IF;
END $$
-- --------------------------------------------------
DELIMITER ;
CALL node_add_column_v1(
'node',
'build_version',
'varchar(255) DEFAULT NULL');
CALL node_add_column_v1(
'node',
'last_boot_ms',
'bigint DEFAULT NULL');
DROP PROCEDURE IF EXISTS node_add_column_v1;
DROP PROCEDURE IF EXISTS node_run_sql_v1;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set tabstop=4 shiftwidth=4 expandtab:
Module stroom-security
Script V07_05_00_005__api_key_relax_uniqeness.sql
Path: stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_05_00_005__api_key_relax_uniqeness.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- --------------------------------------------------
DELIMITER $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS security_run_sql $$
-- DO NOT change this without reading the header!
CREATE PROCEDURE security_run_sql (
p_sql_stmt varchar(1000)
)
BEGIN
SET @sqlstmt = p_sql_stmt;
SELECT CONCAT('Running sql: ', @sqlstmt);
PREPARE stmt FROM @sqlstmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS security_create_non_unique_index$$
-- DO NOT change this without reading the header!
CREATE PROCEDURE security_create_non_unique_index (
p_table_name varchar(64),
p_index_name varchar(64),
p_index_columns varchar(64)
)
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.statistics
WHERE table_schema = database()
AND table_name = p_table_name
AND index_name = p_index_name;
IF object_count = 0 THEN
CALL security_run_sql(CONCAT(
'create index ', p_index_name,
' on ', database(), '.', p_table_name,
' (', p_index_columns, ')'));
ELSE
SELECT CONCAT(
'Index ',
p_index_name,
' already exists on table ',
database(),
'.',
p_table_name);
END IF;
END $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS security_drop_index $$
-- e.g. security_drop_index('MY_TABLE', 'MY_IDX');
CREATE PROCEDURE security_drop_index (
p_table_name varchar(64),
p_index_name varchar(64)
)
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.statistics
WHERE table_schema = database()
AND table_name = p_table_name
AND index_name = p_index_name;
IF object_count = 0 THEN
SELECT CONCAT(
'Index ',
p_index_name,
' does not exist on table ',
database(),
'.',
p_table_name);
ELSE
CALL security_run_sql(CONCAT(
'alter table ', database(), '.', p_table_name,
' drop index ', p_index_name));
END IF;
END $$
-- --------------------------------------------------
DELIMITER ;
-- --------------------------------------------------
-- We need to make this column case sensitive (_as_cs) else we limit the range of keys we can generate
-- as the keys have mixed case.
-- Note the api_key_prefix col contains lower case data so can stay as _ai_ci
ALTER TABLE api_key MODIFY
api_key_hash VARCHAR(255)
CHARACTER SET utf8mb4
COLLATE utf8mb4_0900_as_cs
NOT NULL;
-- Drop the old unique index so we can re-create it as non-unique
CALL security_drop_index(
"api_key",
"api_key_prefix_idx");
-- We have to look up records by prefix. This will usually return 1 row
-- but may return >1. We test the hash of all returned rows.
CALL security_create_non_unique_index(
"api_key",
"api_key_prefix_idx",
"api_key_prefix");
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS security_create_non_unique_index;
DROP PROCEDURE IF EXISTS security_drop_index;
DROP PROCEDURE IF EXISTS security_run_sql;
-- --------------------------------------------------
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Script V07_05_00_010__api_key_add_algo_column.sql
Path: stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_05_00_010__api_key_add_algo_column.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- --------------------------------------------------
DELIMITER $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS security_run_sql $$
-- DO NOT change this without reading the header!
CREATE PROCEDURE security_run_sql (
p_sql_stmt varchar(1000)
)
BEGIN
SET @sqlstmt = p_sql_stmt;
SELECT CONCAT('Running sql: ', @sqlstmt);
PREPARE stmt FROM @sqlstmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS security_add_column$$
CREATE PROCEDURE security_add_column (
p_table_name varchar(64),
p_column_name varchar(64),
p_column_type_info varchar(64) -- e.g. 'varchar(255) default NULL'
)
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = p_table_name
AND column_name = p_column_name;
IF object_count = 0 THEN
CALL security_run_sql(CONCAT(
'alter table ', database(), '.', p_table_name,
' add column ', p_column_name, ' ', p_column_type_info));
ELSE
SELECT CONCAT(
'Column ',
p_column_name,
' already exists on table ',
database(),
'.',
p_table_name);
END IF;
END $$
-- --------------------------------------------------
DELIMITER ;
-- --------------------------------------------------
-- idempotent
CALL security_add_column(
"api_key",
"hash_algorithm",
'tinyint NOT NULL default 0');
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS security_add_column;
DROP PROCEDURE IF EXISTS security_run_sql;
-- --------------------------------------------------
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
9.5 - Change Log
The follow changes are in 7.5 but not in 7.4:
-
Issue #4501 : Fix Query editor syntax highlighting.
-
Add query help and editor completions for Dictionary Docs for use with
in dictionary. -
Issue #4487 : Fix nasty error when running a stats query with no columns.
-
Issue #4498 : Make the explorer tree Expand/Collapse All buttons respect the current Quick Filter input text.
-
Issue #4518 : Change the Stream Upload dialog to default the stream type to that of the feed.
-
Issue #4470 : On import of Feed or Index docs, replace unknown volume groups with the respective configured default volume group (or null if not configured).
-
Issue #4460 : Change the way we display functions with lots of arguments in query help and code completion popup.
-
Issue #4526 : Change Dictionary to not de-duplicate words as this is breaking JSON when used for holding SSL config in JSON form.
-
Issue #4528 : Make the Reindex Content job respond to stroom shutdown.
-
Issue #4532 : Fix Run Job Now so that it works when the job or jobNode is disabled.
-
Issue #4444 : Change the
hash()expression function to allow thealgorithmandsaltarguments to be the result of functions, e.g.hash(${field1}, concat('SHA-', ${algoLen}), ${salt}). -
Issue #4534 : Fix NPE in include/exclude filter.
-
Issue #4527 : Change the non-regex search syntax of Find in Content to not use Lucene field based syntax so that
:works correctly. Also change the regex search to use Lucene and improve the styling of the screen. -
Issue #4536 : Fix NPE.
-
Issue #4539 : Improve search query logging.
-
Improve the process of (re-)indexing content. It is now triggered by a user doing a content search. Users will get an error message if the index is still being initialised. The
stroom.contentIndex.enabledproperty has been removed. -
Issue #4513 : Add primary key to
doc_permission_backup_V07_05_00_005table for MySQL Cluster support. -
Issue #4514 : Fix HTTP 307 with calling
/api/authproxy/v1/noauth/fetchClientCredsToken. -
Issue #4475 : Change
mask()function toperiod()and addusingto apply a function to window. -
Issue #4341 : Allow download from query table.
-
Issue #4507 : Fix index shard permission issue.
-
Issue #4510 : Fix right click in editor pane.
-
Issue #4511 : Fix StreamId, EventId selection in query tables.
-
Issue #4485 : Improve dialog move/resize behaviour.
-
Issue #4492 : Make Lucene behave like SQL for OR(NOT()) queries.
-
Issue #4494 : Allow functions in StroomQL select, e.g.
count(). -
Issue #4202 : Fix default destination not being selected when you do Save As.
-
Issue #4475 : Add
mask()function and deprecatecountPrevious(). -
Issue #4491 : Fix tab closure when deleting items in the explorer tree.
-
Issue #4502 : Fix inability to step an un-processed stream.
-
Issue #4503 : Make the enabled state of the delete/restore buttons on the stream browser depend on the user’s permissions. Now they will only be enabled if the user has the require permission (i.e. DELETE/UPDATE) on at least one of the selected items.
-
Issue #4486 : Fix the
format-dateXSLT function for date strings with the day of week in, e.g.stroom:format-date('Wed Aug 14 2024', 'E MMM dd yyyy'). -
Issue #4458 : Fix explorer node tags not being copied. Also fix copy/move not selecting the parent folder of the source as the default destination folder.
-
Issue #4454 : Show the source dictionary name for each word in the Dashboard List Input selection box. Add sorting and de-duplication of words.
-
Issue #4455 : Add Goto Document links to the Imports sub-tab of the Dictionary screen. Also add new Effective Words tab to list all the words in the dictionary that include those from its imports (and their imports).
-
Issue #4468 : Improve handling of key sequences and detection of key events from ACE editor.
-
Issue #4472 : Change the User Preferences dialog to cope with redundant stroom/editor theme names.
-
Issue #4479 : Add ability to assume role for S3.
-
Issue #4202 : Fix problems with Dashboard Extraction Pipeline picker incorrectly changing the selected pipeline.
-
Change the DocRef picker so that it shows a warning icon if the selected DocRef no longer exists or the user doesn’t have permission to view it.
-
Change the Extraction Pipeline picker on the Index Settings screen to pre-filter on
tag:extraction. This is configured using the propertystroom.ui.query.indexPipelineSelectorIncludedTags. -
Issue #4146 : Fix audit events for deleting/restoring streams.
-
Change the alert dialog message styling to have a max-height of 600px so long messages get a scrollbar.
-
Issue #4468 : Fix selection box keyboard selection behavior when no quick filter is visible.
-
Issue #4471 : Fix NPE with stepping filter.
-
Issue #4451 : Add S3 pipeline appender.
-
Issue #4401 : Improve content search.
-
Issue #4417 : Show stepping progress and allow termination.
-
Issue #4436 : Change the way API Keys are verified. Stroom now finds all valid api keys matching the api key prefix and compares the hash of the api key against the hash from each of the matching records. Support has also been added for using different hash algorithms.
-
Issue #4448 : Fix query refresh tooltip when not refreshing.
-
Issue #4457 : Fix ctrl+enter shortcut for query start.
-
Issue #4441 : Improve sorted column matching.
-
Issue #4449 : Reload Scheduled Query Analytics between executions.
-
Issue #4420 : Make app title dynamic.
-
Issue #4453 : Dictionaries will ignore imports if a user has no permission to read them.
-
Issue #4404 : Change the Query editor completions to be context aware, e.g. it only lists Datasources after a
from. -
Issue #4450 : Fix editor completion in Query editor so that it doesn’t limit completions to 100. Added the property
stroom.ui.maxEditorCompletionEntriesto control the maximum number of completions items that are shown. In the event that the property is exceeded, Stroom will pre-filter the completions based on the user’s input. -
Add Visualisations to the Query help and editor completions. Visualisation completion inserts a snippet containing all the data fields in the Visualisation, e.g.
TextValue(field = Field, gridSeries = Grid Series). -
Issue #4424 : Fix alignment of Current Tasks heading on the Jobs screen.
-
Issue #4422 : Don’t show Edit Schedule in actions menu on Jobs screen for Distributed jobs.
-
Issue #4418 : Fix missing css for
/stroom/sessionList. -
Issue #4435 : Fix for progress spinner getting stuck on.
-
Issue #4426 : Add INFO message when an index shard is created.
-
Issue #4425 : Fix Usage Date heading alignment on Edit Volume Group screen for both data/index volumes.
-
Uplift docker image JDK to
eclipse-temurin:21.0.4_7-jdk-alpine. -
Issue #4416 : Allow dashboard table sorting to be changed post query.
-
Issue #4421 : Change session state XML structure.
-
Issue #4419 : Automatically unpause dashboard result components when a new search begins.
-
Rename migration from
V07_04_00_005__Orphaned_Doc_PermstoV07_05_00_005__Orphaned_Doc_Perms. -
Issue #4383 : Add an authentication error screen to be shown when a user tries to login and there is an authentication problem or the user’s account has been locked/disabled. Previously the user was re-directed to the sign-in screen even if cert auth was enabled. Added the new property
stroom.ui.authErrorMessageto allow setting generic HTML content to show the user when an authentication error occurs. -
Issue #4400 : Fix missing styling on
sessionListservlet. -
Fix broken description pane in the stroomQL code completion.
-
Change API endpoint
/Authentication/v1/noauth/resetfrom GET to POST and from a path parameter to a POST body. -
Fix various issues relating to unauthenticated servlets. Add new servlet paths e.g.
/stroom/XXXbecomes/XXXand/stroom/XXX. The latter will be removed in some future release. Notable new servlet paths are/dashboard,/status,/swagger-ui,/echo,/debug,/datafeed,/sessionList. -
Change
sessionListservlet to require manage users permission. -
Issue #4360 : Fix quick time settings popup.
-
Improve styling of Jobs screen so disabled jobs/nodes are greyed out.
-
Add Next Scheduled column to the detail pane of the Job screen.
-
Add Build Version and Up Date columns to the Nodes screen. Also change the styling of the Ping column so an enabled node with no ping stands out while a disabled node does not. Also change the row styling for disabled nodes.
-
Add a Run now icon to the jobs screen to execute a job on a node immediately.
-
Change the FS Volume and Index Volume tables to low-light CLOSED/INACTIVE volumes. Add tooltips to the path and last updated columns. Change the Use% column to a percentage bar. Add red/green colouring to the Full column values.
-
Issue #4327 : Add a Jobs pane to the Nodes screen to view jobs by node. Add linking between job nodes on the Nodes screen and the Jobs screen.
-
Issue #4339 : Allow user selection of analytic duplicate columns.
-
Issue #2126 : Add experimental state store.
-
Issue #4334 : Popup explorer text on mouse hover.
-
Issue #4278 : Make document deletion also delete the permission records for that document. Also run migration
V07_04_00_005__Orphaned_Doc_Permswhich will delete all document permissions (in tabledoc_permission) for docs that are not a folder, not the System doc, are not a valid doc (i.e. in thedoctable) and are not a pipeline filter. Deleted document permission records will first be copied to a backup tabledoc_permission_backup_V07_04_00_005. -
Change document Copy and Move to check that the user has Owner permission (or admin) on the document being copied/moved if the permissions mode is None, Destination or Combined. This is because those modes will change the permissions which is something only an Owner/admin can do.
-
Issue #3989 : Improve pause behaviour in dashboards and general presentation of
busystate throughout UI. -
Issue #2111 : Add index assistance to find content feature.
For a detailed list of all the changes in v7.5 see: v7.5 CHANGELOG
10 - Version 7.4
10.1 - New Features
Scheduler
The scheduler in Stroom that is used to schedule all the background jobs and Analytic Rules has been changed. The existing Cron Cron Cron is a command line utility found on most linux/unix systems that is used for scheduling background tasks. Cron expressions (or variants of them) are widely used in other schedulers.Click to see more details.../frequency scheduler was quite simplistic and only supported a limited set of features of a cron schedule.
The cron format has changed from a three value cron expression (e.g. * * * to run every minute) to six value one.
Existing three value cron expressions will be migrated to the new syntax when deploying Stroom v7.4.
For full details of the new scheduler see Scheduler
General User Interface Changes
Keyboard Shortcuts
Various new keyboard shortcuts for performing actions in Stroom. See Keyboard Shortcuts for details.
- Add the keyboard shortcut Ctrl ^ + Enter ↵ to the code pane of the stepper to perform a step refresh .
- Add the keyboard shortcut Ctrl ^ + Enter ↵ to the Dashboards to execute all queries.
- Add multiple Goto type shortcuts to jump directly to a screen. See Direct Access to Screens for details.
Documentation
The Documentation entity will now default to edit mode if there is no documentation, e.g. on a newly created Documentation entity.
Copy As
A Copy As group has been added to the explorer tree context menu. This replaces, but includes the Copy Link to Clipboard menu item.
- Copy Name to Clipboard - Copies the name of the entity to the clipboard.
- Copy UUID to Clipboard - Copies the
UUID
UUID
A Universally Unique Identifier for uniquely identifying something. UUIDs are used as the identifier in Doc Refs. An example of a UUID is
4ffeb895-53c9-40d6-bf33-3ef025401ad3.Click to see more details... of the entity to the clipboard. - Copy link to Clipboard - Copies a URL to the clipboard that will link directly to the selected entity.
API Specification Link
Previous versions of Stroom have included an interactive user interface for navigating Stroom’s
API
API
Application Programming Interface. An interface that one system can present so other systems can use it to communicate. Stroom has a number of APIs, e.g. its many REST APIs and its /datafeed interface for data receipt.Click to see more details... specification.
A link to this has been added to the Help menu.
Dashboard Conditional Formatting
- Make the Enabled and Hide Row checkboxes clickable in the table without having open the rule edit dialog.
- Dim disabled rules in the table.
- Add colour swatches for the background and text colours.
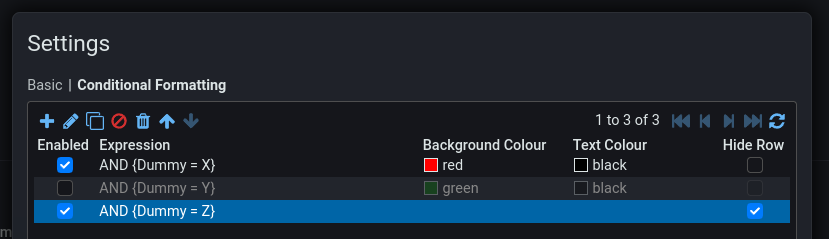
Help Icons on Dialogs
Functionality has been added to included help icons on dialogs. Clicking the icon will display a popup containing help text relating to the thing the icon is next to.
Currently help icons have only been added to a few dialogs, but more will follow.
Stepping Location
The way you change the step location in the stepper has changed. Previously you could click and then directly edit each of the three numbers. Now the location label is a clickable link that opens an edit dialog.
10.2 - Preview Features (experimental)
Analytic Rules
Analytic Rules were introduced in Stroom v7.2 as a preview feature. They remain an experimental preview feature but have undergone more changes/improvements.
Analytic rules are a means of writing a query to find matching data.
Processing Types
Analytic rules have three different processing types:
Streaming
A streaming rule uses a processor filter to find streams that match the filter and runs the query against the stream.
Scheduled Query
A scheduled query will run the rule’s query against a time window of data on a scheduled basis. The time window can be absolute or relative to when the scheduled query fires.
Table Builder
TODO
CompleteMultiple Notifications
Rules now support having multiple notification types/destinations, for example sending an email as well a Stream Stream A Stream is the unit of data that Stroom works with and will typically contain many Events.Click to see more details.... Currently Email and Stream are the only notification types supported.
Email Templating
The email notifications have been improved to allow templating of the email subject and body. The template enables static text/HTML to be mixed with values taken from the detection.
The templating uses a template syntax called jinja and specifically the JinJava library. The templating syntax includes support for variables, filters, condition blocks, loops, etc. Full details of the syntax see Templating and for details of the templating context available in email subject/body templates see Rule Detections Context.
Example Template
The following is an example of a detection template producing a HTML email body that includes conditions and loops:
<!DOCTYPE html>
<html lang="en">
<meta charset="UTF-8" />
<title>Detector '{{ detectorName | escape }}' Alert</title>
<body>
<p>Detector <em>{{ detectorName | escape }}</em> {{ detectorVersion | escape }} fired at {{ detectTime | escape }}</p>
{%- if (values | length) > 0 -%}
<p>Detail: {{ headline | escape }}</p>
<ul>
{% for key, val in values | dictsort -%}
<li><strong>{{ key | escape }}</strong>: {{ val | escape }}</li>
{% endfor %}
</ul>
{% endif -%}
{%- if (linkedEvents | length) > 0 -%}
<p>Linked Events:</p>
<ul>
{% for linkedEvent in linkedEvents -%}
<li>Environment: {{ linkedEvent.stroom | escape }}, Stream ID: {{ linkedEvent.streamId | escape }}, Event ID: {{ linkedEvent.eventId | escape }}</li>
{% endfor %}
</ul>
{% endif %}
</body>
Improved Date Picker
Scheduled queries make use of a new data picker dialog which makes the process of setting a date/time value much easier for the user. This new date picker will be rolled out to other screens in Stroom in some later release.
10.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.Analytic Rules
Any Analytic Rules created in versions 7.2 or 7.3 will need to be deleted and re-created in v7.4. Analytic Rules has been an experimental feature therefore there is no migration in place for rules from previous versions of Stroom.
10.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom instance.Java Version
Stroom v7.4 requires Java 21. This is the same java version as Stroom v7.3. Ensure the Stroom and Stroom-Proxy hosts are running the latest patch release of Java v21.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Migration Filename Change
If you are deploying onto a v7.4-beta.1 instance you will need to modify the database table used to log migration history.
If the job_schema_history table contains version 07.03.00.001 then you will need to run the following SQL against the database to prevent Stroom from failing the migration on boot.
Migration Scripts
For information purposes only, the following are the database migrations that will be run when upgrading to 7.4.0 from the previous minor version.
Note, the legacy module will run first (if present) then the other module will run in no particular order.
Module stroom-analytics
Script V07_04_00_001__execution_schedule.sql
Path: stroom-analytics/stroom-analytics-impl-db/src/main/resources/stroom/analytics/impl/db/migration/V07_04_00_001__execution_schedule.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- --------------------------------------------------
--
-- Create the table
--
CREATE TABLE IF NOT EXISTS execution_schedule (
id int NOT NULL AUTO_INCREMENT,
name varchar(255) NOT NULL,
enabled tinyint NOT NULL DEFAULT '0',
node_name varchar(255) NOT NULL,
schedule_type varchar(255) NOT NULL,
expression varchar(255) NOT NULL,
contiguous tinyint NOT NULL DEFAULT '0',
start_time_ms bigint DEFAULT NULL,
end_time_ms bigint DEFAULT NULL,
doc_type varchar(255) NOT NULL,
doc_uuid varchar(255) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
CREATE INDEX execution_schedule_doc_idx ON execution_schedule (doc_type, doc_uuid);
CREATE INDEX execution_schedule_enabled_idx ON execution_schedule (doc_type, doc_uuid, enabled, node_name);
CREATE TABLE IF NOT EXISTS execution_history (
id bigint(20) NOT NULL AUTO_INCREMENT,
fk_execution_schedule_id int NOT NULL,
execution_time_ms bigint NOT NULL,
effective_execution_time_ms bigint NOT NULL,
status varchar(255) NOT NULL,
message longtext,
PRIMARY KEY (id),
CONSTRAINT execution_history_execution_schedule_id FOREIGN KEY (fk_execution_schedule_id) REFERENCES execution_schedule (id)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
CREATE TABLE IF NOT EXISTS execution_tracker (
fk_execution_schedule_id int NOT NULL,
actual_execution_time_ms bigint NOT NULL,
last_effective_execution_time_ms bigint DEFAULT NULL,
next_effective_execution_time_ms bigint NOT NULL,
PRIMARY KEY (fk_execution_schedule_id),
CONSTRAINT execution_tracker_execution_schedule_id FOREIGN KEY (fk_execution_schedule_id) REFERENCES execution_schedule (id)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
-- --------------------------------------------------
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=2 tabstop=2 expandtab:
Module stroom-job
Script V07_04_00_005__job_node.sql
Path: stroom-job/stroom-job-impl-db/src/main/resources/stroom/job/impl/db/migration/V07_04_00_005__job_node.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
update job_node set schedule = concat('0 ', schedule, ' * ?') where job_type = 1 and regexp_like(schedule, '^[^ ]+ [^ ]+ [^ ]+$');
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set tabstop=4 shiftwidth=4 expandtab:
10.5 - Change Log
For a detailed list of all the changes in v7.4 see: v7.4 CHANGELOG
11 - Version 7.3
11.1 - New Features
User Interface
-
Add a Copy button to the Processors sub-tab on the Pipeline screen. This will create a duplicate of an existing filter.
-
Add a Line Wrapping toggle button to the Server Tasks screen. This will enable/disable line wrapping on the Name and Info cells.
-
Allow pane resizing in dashboards without needing to be in design mode.
-
Add Copy and Jump to hover buttons to the Stream Browser screen to copy the value of the cell or (if it is a document) jump to that document.
-
Tagging of individual explorer nodes was introduced in v7.2. v7.3 however adds support for adding/removing tags to/from multiple explorer tree nodes via the explorer context menu.

Explorer Tree
-
Additional buttons on the top of the explorer tree pane.
-
Add Expand All and Collapse All buttons to the explorer pane to open or close all items in the tree respectively.
-
Add a Locate Current Item button to the explorer pane to locate the currently open document in the explorer tree.
-
Finding Things
Find
New screen for finding documents by name. Accessed using Shift ⇧ + Alt + f or
Find In Content
Improvements to the Find In Content screen so that it now shows the content of the document and highlights the matched terms. Now accessible using shift,ctrl + f or
Recent Items
New screen for finding recently used documents. Accessed using Ctrl ^ + e or
Editor Snippets
Snippets are a way of quickly adding snippets of pre-defined text into the text editors in Stroom. Snippets have been available in previous versions of Stroom however there have been various additions to the library of snippets available which makes creating/editing content a lot easier.
-
Add snippets for Data Splitter. For the list of available snippets see here.
-
Add snippets for XMLFragmentParser. For the list of available snippets see here.
-
Add new XSLT snippets for
<xsl:element>and<xsl:message>. For the list of available snippets see here. -
Add snippets for StroomQl StroomQl Stroom Query Language is Stroom’s own query language. It has similarities with Structured Query Language (SQL) as used in databases. StroomQL is sometimes referred to as sQL to distinguish it from SQL.Click to see more details.... For the list of available snippets see here.
API Keys
API Keys are a means for client systems to authenticate with Stroom. In v7.2 of Stroom, the ability to use API Keys was removed if you were using an external Identity Provider (IDP) Identity Provider (IDP) An Identity Provider is a system or service that can authenticate a user and assert their identity. Identity providers can support single sign on (SSO), which allows the user to sign in once to the Identity Provider so they are then authenticated to all systems using that IDP.Click to see more details... as client systems could get tokens from the IDP themselves. In v7.3 the ability to use API Keys with an external IDP has returned as we felt it offered client systems a choice and removed the complexity of dealing with the IDP.
The API Keys screen has undergone various improvements:
- Look/feel brought in line with other screens in Stroom.
- Ability to temporarily enable/disable API Keys. A key that is disabled in Stroom cannot be authenticated against.
- Deletion of an API Key prevents any future authentication against that key.
- Named API Keys to indicate purpose, e.g. naming a key with the client system’s name.
- Comments for keys to add additional context/information for a key.
- API Key prefix to aid with identifying an API Key.
- The full API key string is no longer stored in Stroom and cannot be viewed after creation.

Key Creation
The screens for creating a new API Key are as follows:
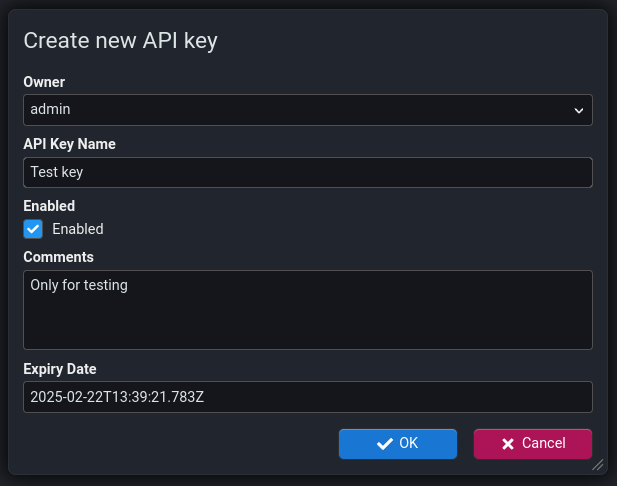
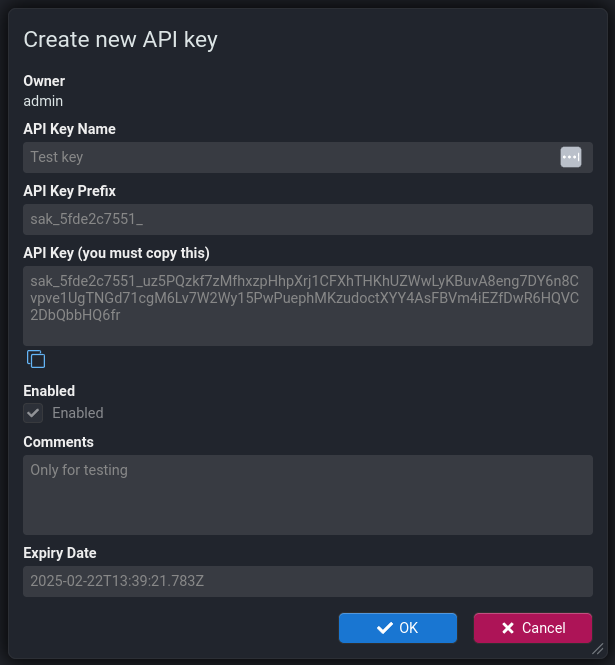
Warning
Note that the actual API Key is ONLY visible on the second dialog. Once that dialog is closed Stroom cannot show you the API Key string as it does not store it. This is for security reasons. You must copy the created key and give it to the recipient at this point.Key Format
We have also made changes to the format of the API Key itself. In v7.2, the API Key was an OAuth token so had data baked into it. In v7.3, the API Key is essentially just a dumb random string, like a very long and secure password. The following is an example of a new API Key:
sak_e1e78f6ee0_6CyT2Mpj2seVJzYtAXsqWwKJzyUqkYqTsammVerbJpvimtn4BpE9M5L2Sx6oeG5prhyzcA7U6fyV5EkwTxoXJPfDWLneQAq16i5P75qdQNbqJ99Wi7xzaDhryMdhVZhs
The structure of the key is as follows:
sak- The key type, Stroom API Key._- separator- Truncated SHA2-256 hash (truncated to 10 chars) of the whole API Key.
_- separator- 128 crypto random chars in the Base58 character set.
This character set ensures no awkward characters that might need escaping and removes some ambiguous characters (
0OIl).
Features of the new format are:
- Fixed length of 143 chars with fixed prefix (
sak_) that make it easier to search for API Keys in config, e.g. to stop API Keys being leaked into online public repositories and the like. - Unique prefix (e.g.
sak_e1e78f6ee0_) to help link an API being used by a client with the API Key record stored in Stroom. This part of the key is stored and displayed in Stroom. - The hash part acts as a checksum for the key to ensure it is correct. The following CyberChef recipe shows how you can validate the hash part of a key.
Analytics
-
Add distributed processing for streaming analytics. This means streaming analytics can now run on all nodes in the cluster rather than just one.
-
Add multiple recipients to rule notification emails. Previously only one recipient could be added.
Search
-
Add support for Lucene 9.8.0 and supporting multiple version of Lucene. Stroom now stores the Lucene version used to create an index shard against the shard so that the correct Lucene version is used when reading/writing from that shard. This will allow Stroom to harness new Lucene features in future while maintaining backwards compatibility with older versions.
-
Add support for
field inandfield in dictionaryto StroomQl StroomQl Stroom Query Language is Stroom’s own query language. It has similarities with Structured Query Language (SQL) as used in databases. StroomQL is sometimes referred to as sQL to distinguish it from SQL.Click to see more details....
Processing
-
Improve the display of processor filter state. The columns
Tracker MsandTracker %have been removed and theStatuscolumn has been improved better reflect the state of the filter tracker. -
Stroom now supports the XSLT standard element
<xsl:message>. This element will be handled as follows:<!-- Log `some message` at severity `FATAL` and terminate processing of that stream part immediately. Note that `terminate="yes"` will trump any severity that is also set. --> <xsl:message terminate="yes">some message</xsl:message> <!-- Log `some message` at severity `ERROR`. --> <xsl:message>some message</xsl:message> <!-- Log `some message` at severity `FATAL`. --> <xsl:message><fatal>some message</fatal></xsl:message> <!-- Log `some message` at severity `ERROR`. --> <xsl:message><error>some message</error></xsl:message> <!-- Log `some message` at severity `WARNING`. --> <xsl:message><warn>some message</warn></xsl:message> <!-- Log `some message` at severity `INFO`. --> <xsl:message><info>some message</info></xsl:message> <!-- Log $msg at severity `ERROR`. --> <xsl:message><xsl:value-of select="$msg"></xsl:message>The namespace of the severity element (e.g.
<info>is ignored. -
Add the following pipeline element properties to allow control of logged warnings for removal/replacement respectively.
- Add property
warnOnRemovalto InvalidCharFilterReader . - Add property
warnOnReplacementto InvalidXMLCharFilterReader .
- Add property
XSLT Functions
- Add XSLT function
stroom:hex-to-string(hex, charsetName). - Add XSLT function
stroom:cidr-to-numeric-ip-rangeXSLT function. - Add XSLT function
stroom:ip-in-cidrfor testing whether an IP address is within the specified CIDR range.
For details of the new functions, see XSLT Functions.
API
- Add the un-authenticated API method
/api/authproxy/v1/noauth/fetchClientCredsTokento effectively proxy for the IDP's Identity Provider (IDP) An Identity Provider is a system or service that can authenticate a user and assert their identity. Identity providers can support single sign on (SSO), which allows the user to sign in once to the Identity Provider so they are then authenticated to all systems using that IDP.Click to see more details... token endpoint to obtain an access token using the client credentials flow. The request contains the client credentials and looks like{ "clientId": "a-client", "clientSecret": "BR9m.....KNQO" }. The response media type istext/plainand contains the access token.
11.2 - Preview Features (experimental)
S3 Storage
Integration with S3 storage has been added to allow Stroom to read/write to/from S3 storage, e.g. S3 on AWS.
A data volume can now be create as either Standard or S3.
If configured as S3 you need to supply the S3 configuration data.
This is an experimental feature at this stage and may be subject to change. The way Stroom reads and writes data has not been optimised for S3 so performance at scale is currently unknown.
11.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.-
The Hessian based feed status RPC service
/remoting/remotefeedservice.rpchas been removed as it is using the legacyjavax.servletdependency that is incompatible withjakarta.servletthat is now in use in stroom. This was used by Stroom-Proxy up to v5. -
The StroomQL keyword combination
vis ashas been replaced withshow.
11.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom instance.Java Version
Stroom v7.3 requires Java v21. Previous versions of Stroom used Java v17 or lower. You will need to upgrade Java on the Stroom and Stroom-Proxy hosts to the latest patch release of Java v21.
API Keys
With the change to the format of API Keys (see here), it is recommended to migrate legacy API Keys over to the new format. There is no hard requirement to do this as legacy keys will continue to work as is, however the new keys are easier to work with and Stroom has more control over the new format keys, making them more secure. You are encouraged to create new keys for client systems and ask them to change the keys over.
Legacy Key Migration
The new API Keys are now stored in a new table api_key.
Legacy keys will be migrated into this table and given a key name and prefix like LEGACY_API_KEY_N, where N is a unique number.
As the whole API was previously visible in v7.2, the API Key string is migrated into the Comments field so remains visible in the UI.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Migration Scripts
For information purposes only, the following are the database migrations that will be run when upgrading to 7.3.0 from the previous minor version.
Note, the legacy module will run first (if present) then the other module will run in no particular order.
Module stroom-data
Script V07_03_00_001__fs_volume_s3.sql
Path: stroom-data/stroom-data-store-impl-fs-db/src/main/resources/stroom/data/store/impl/fs/db/migration/V07_03_00_001__fs_volume_s3.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
CREATE TABLE IF NOT EXISTS fs_volume_group (
id int NOT NULL AUTO_INCREMENT,
version int NOT NULL,
create_time_ms bigint NOT NULL,
create_user varchar(255) NOT NULL,
update_time_ms bigint NOT NULL,
update_user varchar(255) NOT NULL,
name varchar(255) NOT NULL,
-- 'name' needs to be unique because it is used as a reference
UNIQUE (name),
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
DROP PROCEDURE IF EXISTS V07_03_00_001;
DELIMITER $$
CREATE PROCEDURE V07_03_00_001 ()
BEGIN
DECLARE object_count integer;
-- Add volume type
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'fs_volume'
AND column_name = 'volume_type';
IF object_count = 0 THEN
ALTER TABLE `fs_volume` ADD COLUMN `volume_type` int NOT NULL;
ALTER TABLE `fs_volume` ADD COLUMN `data` longblob;
UPDATE `fs_volume` set `volume_type` = 0;
END IF;
-- Add default group
SELECT COUNT(*)
INTO object_count
FROM fs_volume_group
WHERE name = "Default";
IF object_count = 0 THEN
INSERT INTO fs_volume_group (
version,
create_time_ms,
create_user,
update_time_ms,
update_user,
name)
VALUES (
1,
UNIX_TIMESTAMP() * 1000,
"Flyway migration",
UNIX_TIMESTAMP() * 1000,
"Flyway migration",
"Default Volume Group");
END IF;
-- Add volume group
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = 'fs_volume'
AND column_name = 'fk_fs_volume_group_id';
IF object_count = 0 THEN
ALTER TABLE `fs_volume`
ADD COLUMN `fk_fs_volume_group_id` int NOT NULL;
UPDATE `fs_volume` SET `fk_fs_volume_group_id` = (SELECT `id` FROM `fs_volume_group` WHERE `name` = "Default Volume Group");
ALTER TABLE fs_volume
ADD CONSTRAINT fs_volume_group_fk_fs_volume_group_id
FOREIGN KEY (fk_fs_volume_group_id)
REFERENCES fs_volume_group (id);
END IF;
END $$
DELIMITER ;
CALL V07_03_00_001;
DROP PROCEDURE IF EXISTS V07_03_00_001;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Module stroom-index
Script V07_03_00_001__index_field.sql
Path: stroom-index/stroom-index-impl-db/src/main/resources/stroom/index/impl/db/migration/V07_03_00_001__index_field.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP PROCEDURE IF EXISTS drop_field_source;
DELIMITER //
CREATE PROCEDURE drop_field_source ()
BEGIN
IF EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'field_info') THEN
DROP TABLE field_info;
END IF;
IF EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'field_source') THEN
DROP TABLE field_source;
END IF;
IF EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'field_schema_history') THEN
DROP TABLE field_schema_history;
END IF;
END//
DELIMITER ;
CALL drop_field_source();
DROP PROCEDURE drop_field_source;
--
-- Create the field_source table
--
CREATE TABLE IF NOT EXISTS `index_field_source` (
`id` int NOT NULL AUTO_INCREMENT,
`type` varchar(255) NOT NULL,
`uuid` varchar(255) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `index_field_source_type_uuid` (`type`, `uuid`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
--
-- Create the index_field table
--
CREATE TABLE IF NOT EXISTS `index_field` (
`id` bigint NOT NULL AUTO_INCREMENT,
`fk_index_field_source_id` int NOT NULL,
`type` tinyint NOT NULL,
`name` varchar(255) NOT NULL,
`analyzer` varchar(255) NOT NULL,
`indexed` tinyint NOT NULL DEFAULT '0',
`stored` tinyint NOT NULL DEFAULT '0',
`term_positions` tinyint NOT NULL DEFAULT '0',
`case_sensitive` tinyint NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `index_field_source_id_name` (`fk_index_field_source_id`, `name`),
CONSTRAINT `index_field_fk_index_field_source_id` FOREIGN KEY (`fk_index_field_source_id`) REFERENCES `index_field_source` (`id`)
) ENGINE=InnoDB DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set tabstop=4 shiftwidth=4 expandtab:
Script V07_03_00_005__index_field_change_pk.sql
Path: stroom-index/stroom-index-impl-db/src/main/resources/stroom/index/impl/db/migration/V07_03_00_005__index_field_change_pk.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DELIMITER $$
DROP PROCEDURE IF EXISTS modify_field_source$$
-- The surrogate PK results in fields from different indexes all being mixed together
-- in the PK index, which causes deadlocks in batch upserts due to gap locks.
-- Change the PK to be (fk_index_field_source_id, name) which should keep the fields
-- together.
CREATE PROCEDURE modify_field_source ()
BEGIN
-- Remove existing PK
IF EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.columns
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'index_field'
AND COLUMN_NAME = 'id') THEN
ALTER TABLE index_field DROP COLUMN id;
END IF;
-- Add the new PK
IF NOT EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.table_constraints
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'index_field'
AND CONSTRAINT_NAME = 'PRIMARY') THEN
ALTER TABLE index_field ADD PRIMARY KEY (fk_index_field_source_id, name);
END IF;
-- Remove existing index that is now served by PK
IF EXISTS (
SELECT NULL
FROM INFORMATION_SCHEMA.table_constraints
WHERE TABLE_SCHEMA = database()
AND TABLE_NAME = 'index_field'
AND CONSTRAINT_NAME = 'index_field_source_id_name') THEN
ALTER TABLE index_field DROP INDEX index_field_source_id_name;
END IF;
END $$
DELIMITER ;
CALL modify_field_source();
DROP PROCEDURE IF EXISTS modify_field_source;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set tabstop=4 shiftwidth=4 expandtab:
Module stroom-processor
Script V07_03_00_001__processor.sql
Path: stroom-processor/stroom-processor-impl-db/src/main/resources/stroom/processor/impl/db/migration/V07_03_00_001__processor.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
DROP PROCEDURE IF EXISTS modify_processor;
DELIMITER //
CREATE PROCEDURE modify_processor ()
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.table_constraints
WHERE table_schema = database()
AND table_name = 'processor'
AND constraint_name = 'processor_pipeline_uuid';
IF object_count = 1 THEN
ALTER TABLE processor DROP INDEX processor_pipeline_uuid;
END IF;
SELECT COUNT(1)
INTO object_count
FROM information_schema.table_constraints
WHERE table_schema = database()
AND table_name = 'processor'
AND constraint_name = 'processor_task_type_pipeline_uuid';
IF object_count = 0 THEN
CREATE UNIQUE INDEX processor_task_type_pipeline_uuid ON processor (task_type, pipeline_uuid);
END IF;
END//
DELIMITER ;
CALL modify_processor();
DROP PROCEDURE modify_processor;
SET SQL_NOTES=@OLD_SQL_NOTES;
-- vim: set shiftwidth=4 tabstop=4 expandtab:
Script V07_03_00_005__processor_filter.sql
Path: stroom-processor/stroom-processor-impl-db/src/main/resources/stroom/processor/impl/db/migration/V07_03_00_005__processor_filter.sql
-- ------------------------------------------------------------------------
-- Copyright 2020 Crown Copyright
--
-- Licensed under the Apache License, Version 2.0 (the "License");
-- you may not use this file except in compliance with the License.
-- You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
-- ------------------------------------------------------------------------
-- Stop NOTE level warnings about objects (not)? existing
SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0;
-- --------------------------------------------------
DELIMITER $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS processor_run_sql_v1 $$
-- DO NOT change this without reading the header!
CREATE PROCEDURE processor_run_sql_v1 (
p_sql_stmt varchar(1000)
)
BEGIN
SET @sqlstmt = p_sql_stmt;
SELECT CONCAT('Running sql: ', @sqlstmt);
PREPARE stmt FROM @sqlstmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END $$
-- --------------------------------------------------
DROP PROCEDURE IF EXISTS processor_add_column_v1$$
-- DO NOT change this without reading the header!
CREATE PROCEDURE processor_add_column_v1 (
p_table_name varchar(64),
p_column_name varchar(64),
p_column_type_info varchar(64) -- e.g. 'varchar(255) default NULL'
)
BEGIN
DECLARE object_count integer;
SELECT COUNT(1)
INTO object_count
FROM information_schema.columns
WHERE table_schema = database()
AND table_name = p_table_name
AND column_name = p_column_name;
IF object_count = 0 THEN
CALL processor_run_sql_v1(CONCAT(
'alter table ', database(), '.', p_table_name,
' add column ', p_column_name, ' ', p_column_type_info));
ELSE
SELECT CONCAT(
'Column ',
p_column_name,
' already exists on table ',
database(),
'.',
p_table_name);
END IF;
END $$
-- idempotent
CALL processor_add_column_v1(
'processor_filter',
'max_processing_tasks',
'int NOT NULL DEFAULT 0');
-- vim: set shiftwidth=4 tabstop=4 expandtab:
11.5 - Change Log
For a detailed list of all the changes in v7.3 see: v7.3 CHANGELOG
12 - Version 7.2
Stroom v7.1 was not widely adopted so this section may describe features or changes that were part of the v7.1 release.
12.1 - New Features
Look and Feel
New User Interface Design
The user interface has had a bit of a re-design to give it a more modern look and to make it conform to accessibility standards.
User Preferences
Now you can customise Stroom with your own personal preferences. From the main menu , select:
You can also change the following:
-
Layout Density - This controls the layout spacing to fit more or less user interface elements in the available space.
-
Font - Change font used in Stroom.
-
Font Size - Change the font size used in Stroom.
-
Transparency - Enables partial transparency of dialog windows. Entirely cosmetic.
Theme
Choose between the traditional light theme and a new dark theme with light text on a dark background.
Editor Preferences
The Ace text editor used within Stroom is used for editing things like XSLTs and viewing stream data. It can now be personalised with the following options:
-
Theme - The colour theme for the editor. The theme options will be applicable to the main user interface theme, i.e. light/dark editor themes. The theme affects the colours used for the syntax highlight content.
-
Key Bindings - Allows you to set the editor to use Vim key bindings for more powerful text editing. If you don’t know what Vim is then it is best to stick to Standard. If you would like to learn how to use Vim, install
vimtutor. Note: The Ace editor does not fully emulate Vim, not all Vim key bindings work and there is limited command mode support. -
Live Auto Completion - Set this to On if you want the editor code completion to make suggestions as you type. When set to Off you need to press Ctrl ^ + Space ␣ to show the suggestion dialog.
Date and Time
You can now change the format used for displaying the date and time in the user interface. You can also set the time zone used for displaying the date and time in the user interface.
Note
Stroom works in
Coordinated Universal Time (UTC)
Coordinated Universal Time (UTC)
Coordinated Universal Time (UTC), also known as Zulu time, is the international standard by which the world regulates clocks and time. It is essentially a successor to Greenwich Mean Time (GMT). UTC has the time zone offset of +00:00 and does not change for daylight saving. All international time zones are relative to UTC.Click to see more details… time internally.
Changing the time zone only affects display of dates/times, not how data is stored or the dates/times in events.
Dashboard Changes
Design Mode
A Design Mode has been introduced to Dashboards Dashboard A Dashboard is a configurable entity for querying one or more Data Sources and displaying the results as a table, a visualisation or some other form.Click to see more details... and is toggled using the button . When a Dashboard is in design mode, the following functionality is enabled:
- Adding components to the Dashboard.
- Removing components from the Dashboard.
- Moving Dashboard components within panes, to new panes or to existing panes.
- Changing the constraints of the Dashboard.
On creation of a new Dashboard, Design Mode will be on so the user has full functionality. On opening an existing Dashboard, Design Mode will be off. This is because typically, Dashboards are viewed more than they are modified.
Visual Constraints
Now it is possible to control the horizontal and vertical constraints of a Dashboard. In Stroom 7.0, a dashboard would always scale to fit the user’s screen. Sometimes it is desirable for the dashboard canvas area to be larger than the screen so that you have to scroll to see it all. For example you may have a dashboard with a large number of component panes and rather than squashing them all into the available space you want to be able to scroll vertically in order to see them all.
It is now possible to change the horizontal and/or vertical constraints to fit the available width/height or to be fixed by clicking the button.
The edges of the canvas can be moved to shrink/grow it.
Explorer Filter Matches
Filtering in the explorer has been changed to highlight the filter matches and to search in folders that themselves are a match. In Stroom v7.0 folders that matched were not expanded. Match highlighting makes it clearer what items have matched.
Document Permissions Screen
The document and folder permissions screens have been re-designed with a better layout and item highlighting to make it clearer which permissions have been selected.
Editor Completion snippets
The number of available editor completion snippets has increased. For a list of the available completion snippets see the Completion Snippet Reference.
Note
Completion snippets are an evolving feature so if you have any requests for generic completion snippets then raise an issue on GitHub and we will consider adding them in.Partitioned Reference Data Stores
In Stroom v7.0 reference data is loaded using a reference loader pipeline and the key/value pairs are stored in a single disk backed reference data store on each Stroom node for fast lookup. This single store approach has led to high contention and performance problems when purge operations are running against it at the same time or multiple reference Feeds are being loaded at the same time.
In Stroom v7.2 the reference data key/value pairs are now stored in multiple reference data stores on each node, with one store per Feed. This reduces contention as reference data for one Feed can be loading while a purge operation is running on the store for another Feed or reference data for multiple Feeds can be loaded concurrently. Performance is still limited by the file system that the stores are hosted on.
All reference data stores are stored in the directory defined by stroom.pipeline.referenceData.lmdb.localDir.
See Also
See the upgrade notes for the reference data stores.
Improved OAuth2.0/OpenID Connect Support
The support for Open ID Connect (OIDC) authentication has been improved in v7.2. Stroom can be integrated with AWS Cognito, MS Azure AD, KeyCloak and other OIDC Identity Providers Identity Provider (IDP) An Identity Provider is a system or service that can authenticate a user and assert their identity. Identity providers can support single sign on (SSO), which allows the user to sign in once to the Identity Provider so they are then authenticated to all systems using that IDP.Click to see more details....
Data receipt in Stroom and Stroom-Proxy can now enforce OIDC token authentication as well as certificate authentication. The data receipt authentication is configured via the properties:
stroom.receive.authenticationRequiredstroom.receive.certificateAuthenticationEnabledstroom.receive.tokenAuthenticationEnabled
Stroom and Stroom-Proxy have also been changed to use OIDC tokens for API endpoints and inter-node communications. This currently requires the OIDC IDP to support the client credentials flow.
Stroom can still be used with its own internal IDP if you do not have an external IDP available.
User Naming Changes
The changes to add integration with external OAuth 2.0/OpenID Connect identity provides has required some changes to the way users in Stroom are identified.
Previously in Stroom a user would have a unique username that would be set when creating the account in Stroom.
This would typically by a human friendly name like jbloggs or similar.
It would be used in all the user/permission management screens to identify the user, for functions like current-user(), for simple audit columns in the database (create_user and update_user) and for the audit events stroom produces.
With the integration to external identity providers this has had to change a little.
Typically in OpenID Connect IDPs the unique identity of a principle (user) is fairly unfriendly
UUID
UUID
A Universally Unique Identifier for uniquely identifying something. UUIDs are used as the identifier in Doc Refs. An example of a UUID is 4ffeb895-53c9-40d6-bf33-3ef025401ad3.Click to see more details....
The user will likely also have a more human friendly identity (sometimes called the preferred_username) that may be something like jblogs or jblogs@somedomain.x.
As per the OpenID Connect specification, this friendly identity may not be unique within the IDP, so Stroom has to assume this also.
In reality this identity is typically unique on the IDP though.
The IDP will often also have a full name for the user, e.g. Joe Bloggs.
Stroom now stores and can display all of these identities.
- Display Name - This is the (potentially non-unique) preferred user name held by the IDP, e.g.
jbloggsorjblogs@somedomain.x. - Full Name - The user’s full name, e.g.
Joe Bloggs, if known by the IDP. - Unique User Identity - The unique identity of the user on the IDP, which may look like
ca650638-b52c-45af-948c-3f34aeeb6f86.
In most screens, Stroom will display the Display Name. This will also be used for any audit purposes. The permissions screen show all three identities so an admin can be sure which user they are dealing with and be able to correlate it with one on the IDP.
User Creation
When using an external IDP, a user visiting Stroom for the first time will result in the creation of a Stroom User record for them. This Stroom User will have no permissions associated with it. To improve the experience for a new user it is preferable for the Stroom administrator to pre-create the Stroom User account in Stroom with the necessary permissions.
This can be done from the Application Permissions screen accessed from the Main menu ().
You can create a single Stroom User by clicking the button.
Or you can create multiple Stroom Users by clicking the button.
In both cases the Unique User ID is mandatory, and this must be obtained from the IDP. The Display Name and Full Name are optional, as these will be obtained automatically from the IDP by Stroom on login. It can be useful to populate them initially to make it easier for the administrator to see who is who in the list of users.
Once the user(s) are created, the appropriate permissions/groups can be assigned to them so that when they log in for the first time they will be able to see the required content and be able to use Stroom.
New Document types
The following new types of document can be created and managed in the explorer tree.
Documentation
It is now possible to create a Documentation entity in the explorer tree. This is designed to hold any text or documentation that the user chooses to write in Markdown Markdown Markdown is a simple markup language for creating rich formatted text using a text editor. Due to the simplicity of the Markdown it is still very readable in its raw form that contains the markup. Markdown is used in Stroom on the Documentation tab of each Document type and in the Documentation Document type.Click to see more details... format. These can be useful for providing documentation within a folder in the tree to collectively describe all the items in that folder, or to provide a useful README type document. It is not possible to add documentation to a folder entity itself, so this is useful substitute.
See Also
See Documenting Content for details on the Markdown syntax.
Elastic Cluster
Elastic Cluster provides a means to define a connection to an Elasticsearch Elasticsearch Elasticsearch is an Open Source and commercial search index product. Stroom can be connected to one or more Elasticsearch clusters so that event indexing and search is handled by Elasticsearch rather than internally.Click to see more details... Cluster. You would create one of these documents for each Elasticsearch cluster that you want to connect to. It defines the location and authentication details for connecting to an elastic cluster.
Thanks to Pete K for his help adding the new Elasticsearch integration features.
Elastic Index
An Elastic Index document is a data source for searching one or more indexes on Elasticsearch.
See Also
New Searchables
A Searchable Searchable A Searchable is the term given the special searchable data sources that appear at the root of the explorer tree picker when selecting a data source. These data sources are special internal data sources that are not user managed content, unlike an Index. They provide the means to search various aspects of Stroom’s internals, such as the Meta Store or Processor Tasks.Click to see more details... is one of the data sources that appear at the top level of the tree pickers but not in the explorer tree.
Analytics
Adds the ability to query data from Table Builder type Analytic Rules.
New Pipeline Elements
DynamicIndexingFilter
DynamicIndexingFilterThis filter element is used by Views and Analytic Rules. Unlike IndexingFilter where you have to specify all the fields in the index up front for them to visible to the user in a Dashboard, DynamicIndexingFilter allows fields to be dynamically created in the XSLT based on the event being indexed. These dynamic fields are then ‘discovered’ after the event has been added to the index.
DynamicSearchResultOutputFilter
DynamicSearchResultOutputFilterThis filter element is used by Views and Analytic Rules. Unlike SearchResultOutputFilter this element can discover the fields found in the extracted event when the extraction pipeline creates fields that are not present in the index. These discovered field are then available for the user to pick from in the Dashboard/Query.
ElasticIndexingFilter
ElasticIndexingFilterElasticIndexingFilter is used to pass fields from an event to an Elasticsearch cluster to index.
See Also
Explorer Tree
Various enhancements have been made to the explorer tree.
Favourites
Users now have the ability to mark explorer tree entities as favourites. Favourites are user specific so each user can define their own favourites. This feature is useful for quick access to commonly used entities. Any entity or Folder at any level in the explorer tree can be set as a favourite. Favourites are also visible in the various entity pickers used in Stroom, e.g. Feed pickers.
An entity/folder can be added or removed from the favourites section using the context menu items :
An entity that is a favourite is marked with a in the main tree.
A change to a child item of a folder marked as a favourite will be reflected in both the main tree and the favourites section. All items marked as a favourite will appear as a top level item underneath the Favourites root, even if they have an ancestor folder that is also a favourite.
Thanks to Pete K for adding this new feature.
Document Tagging
You can now add tags to entities or folders in the explorer tree. Tags provide an additional means of searching for entities or folders. It allows entities/folders that reside in different folders to be associated together in one or more ways.
The tags on an entity/folder can be managed from the explorer tree context menu item:
The explorer tree can be filtered by tag using the field prefix tag:, i.e. tag:extraction.
If multiple entities/folders are selected in the explorer tree then the following menu items are available:
Pre-populated Tag Filters
Stroom comes pre-configured with some default tags.
The property that sets these is stroom.explorer.suggestedTags.
The defaults for this property are dynamic, extraction and reference-loader
These pre-configured tags are also used in some of the tree pickers in stroom to provide extra filtering of entities in the picker.
For example when selecting a Pipeline on an XSLT Filter the filter on the tree picker to select the pipeline will be pre-populated with tag:reference-loader so only reference loader pipelines are included.
The following properties control the tags used to pre-populate tree picker filters:
stroom.ui.query.dashboardPipelineSelectorIncludedTagsstroom.ui.query.viewPipelineSelectorIncludedTagsstroom.ui.referencePipelineSelectorIncludedTags
See Also
See the migration task Tagging Entities for details on how to set up these pre-configured tags.
Copy Link to Clipboard
It is now possible to easily copy a direct link to a Document from the explorer tree. Direct links are useful if for example you want to share a link to a particular stroom dashboard.
To create a direct link, right click on the document you want a link for in the explorer tree and select:
You can then paste the link into a browser to jump directly to that document (authenticating as required).
Dependencies
It is now possible to jump to the Dependencies screen to see the dependencies or dependants of a particular document. In the explorer tree right click on a document and select one of:
This will open the Dependencies screen with a filter pre-populated to show all documents that are dependencies of the selected document.
This will open the Dependencies screen with a filter pre-populated to show all documents that depend on the selected document.
Broken Dependency Alerts
It is now possible to see alert icons in the explorer tree to highlight documents that have broken dependencies. The user can hover over these icons to display more information about the broken dependency. The explorer tree will show the alert icon against all documents with a broken dependency and all of its ancestor folders.
A broken dependency means a document (e.g. an XSLT) has a dependency on another document (e.g. a reference loader Pipeline) but that document does not exist. Broken dependencies can occur when a user deletes a document that other documents depend on, or by a partial import of content.
This feature is disabled by default as it can have a significant effect on performance of the explorer tree with large trees.
To enable this feature, set the property stroom.explorer.dependencyWarningsEnabled to true.
Once enabled at the system level by the property, the display of alerts in the tree can be enabled/disabled by the user using the Toggle Alerts button.
Entity Documentation
It is now possible to add documentation to all entities Entity Typically refers to an item that can be created in the Explorer Tree, e.g. a Feed, a Pipeline, a Dashboard, etc. May also be known as a Document.Click to see more details.../ documents Document Typically refers to an item that can be created in the Explorer Tree, e.g. a Feed, a Pipeline, a Dashboard, etc. May also be known as an Entity.Click to see more details... in the explorer tree, e.g. adding documentation on a Feed. Each entity now has a Documentation sub-tab where the user can enter any documentation they choose about that entity. The documentation is written in Markdown Markdown Markdown is a simple markup language for creating rich formatted text using a text editor. Due to the simplicity of the Markdown it is still very readable in its raw form that contains the markup. Markdown is used in Stroom on the Documentation tab of each Document type and in the Documentation Document type.Click to see more details... syntax. It is not possible to add documentation to a Folder but you can create one or more a Documentation entities as a child item of that folder, see Documentation.
See Also
See Documenting Content for details on the Markdown syntax.
Find Content
You can now search the content of entities in the explorer tree, e.g. searching within XSLTs, Dictionaries, Pipeline structure, etc. This feature is available from the main menu :
It can also be accessed by hitting Ctrl ^ + Shift ⇧ + f (unless an editor pane has focus).
It is useful for finding which pipelines are using a certain element, or what XSLTs are using a certain stroom: function.
This is an early evolution of this feature and it is likely to be improved with time.
Search Result Stores
When a Dashboard/Query search is run, the results are written to a Search Results Store for that query. This stores reside on disk to reduce the memory used by queries. The Search Result Stores are stored on a single Stroom node and get created when a query is executed in a Dashboard, Query or Analytic Rule.
This screen provides an administrator with an overview of all the stores currently in existence in the Stroom cluster, showing details on their state and size. It can also be used to stop queries that are currently running or to delete the store entirely. Stores get deleted when the user closes the Dashboard or Query that created them.
Pipeline Stepper Improvements
The pipeline stepper has had a few user interface tweaks to make it easier to use.
Log Pane
When there are errors, warnings or info messages on a pipeline element they will now also be displayed in a pane at the bottom. This makes it easer to see all messages in one place.

The editor still displays icons with hover tips in the gutter on the appropriate line where the message has an associated line number.
The log pane can be hidden by clicking the icon.
Highlighting
The pipeline displayed at the top of the stepper now highlights elements that have log messages against them. This makes it easier to see when there is a problem with an element as you step through the data. The elements are given a coloured border according to the highest severity message on that element:
- Info - Blue
- Warning - Yellow
- Error - Red
- Fatal Error - Red (pulsating)

Filtering
Stroom has always had the ability to filter the data being stepped, however the feature was a little hidden (the Mange Step Filters icon).
Now you can right click on a pipeline element to manage the filters on that element. You can also clear its filters or the filters on all elements.
The pipeline now shows which elements have an active filter by displaying a filter icon.
Server Tasks
Auto Refresh
You can now enable/disable the auto-refreshing of the Server Tasks table using the button. Auto refresh is enabled by default. Disabling it is useful when you want to delete a task, as it will stop the table being refreshed just before you hit delete.
Line Wrapping
You can now enable/disable line wrapping in the Name and Info cells using the button. Line wrapping is disabled by default. Enabling this is useful to see long Info cell values.
Info Popup
The Info popup has been changed to include the value from the Info column.
Proxy
Stroom-Proxy v7.2 has undergone a significant re-write in an attempt to address certain performance issues, make it more flexible and to allow data to be forked to many destinations.
Warning
There are some known performance issues with Stroom-Proxy v7.2 so it is not yet production ready, therefore until these are addressed you are advised to continue using Stroom-Proxy v7.0.12.2 - Preview Features (experimental)
New Document types
Warning
The following features are usable but should be considered experimental at this point. The functionality may be subject to future changes that may break any content created with this version.View
A View is a document type that has been added in to make using Dashboards and Queries easier. It encapsulates the data source and an optional extraction pipeline.
Previously a user wanting to create a Dashboard to query Stroom’s indexes would need to first select the Index to use as the data source then select an extraction pipeline. The indexes do not typically store the full event, so extraction pipelines retrieve the full event from the stream store for each matching event returned by the index. Users should not need to understand the distinction between what is held in the index and what has to be exacted, nor should they need to know how to do that extraction.
A View abstracts the user from this process. They can be configured by an admin or more senior user so that a standard user can just select an appropriate View as the data source in a Dashboard or Query and the View will silently handle the retrieval/extraction of data.
Views are also used by Analytic Rules so need to define a Meta filter that controls the streams that will be processed by the analytic. This filer should mirror the processor filter expression used to control data processed by the Index that the View is using. These two filters may be amalgamated in a future version of Stroom.
Query
The Query feature provides a new way to query data in Stroom. It is a functional but evolving feature that is likely to be enhanced further in future versions.
Rather than using the query expression builder and table column expressions as used in Dashboards, it uses the new text based Stroom Query Language to define the query.
Stroom Query Language (StroomQL)
This is an example of a StroomQL query. It replaces the old dashboard expression ’tree’ and table column expressions. StroomQL has the advantage of being quicker to construct and is easier to copy from one query to another (whole or in part) as it is just plain text.
Editing StroomQL queries in the editor is also made easier by the code completion (using ctrl+space) to suggest data sources, fields, functions and StroomQL language terms.
StroomQl queries can be executed easily with ctrl+enter or shift+enter.
Analytic Rule
Analytic Rules allow the user to create scheduled or streaming Analytic Rule that will fire alerts when events matching the rule are seen.
Analytic rules rely on the new Stroom Query Language to define what events will match the rule. An Analytic Rule can be created directly from a Query by clicking the Create Analytic Rule icon.
12.3 - Breaking Changes
Warning
Please read this section carefully in case any of the changes affect you.Quoted Strings in Dashboard Table Expressions
Quoted strings in dashboard table expressions can now be expressed with single and double quotes.
As part of this change apostrophes in text are no longer escaped with an additional apostrophe (''), but instead require a leading \ before them if they are in a single quoted string, i.e:
'O''Neill' must be changed to 'O\'Neill'
In many cases it is preferable to use double quotes if the string in question has an apostrophe.
Note that the use of \ as an escape character also means that any existing \ characters will need to be escaped with a preceding \ so \ must now become \\, i.e:
c:\Windows\System32 must be changed to c:\\Windows\\System32
The new Find Content feature can be used to find affected Dashboards.
Search API Change
The APIs for running searches against Stroom data sources have changed in a breaking way. This is due to a change in the way running queries are identified.
Previously the client calling the API would generate a unique key for the query and included it in the searchRequest object.
This key would then be used again if the client wanted to make further requests for results for the same running query.
"key" : {
"uuid": "e244d45c-4086-463b-b1a8-10c8c7d7d6c7"
},
In v7.2 the query key is now generated by Stroom rather than the client.
In the first search request for a query, the client should now omit the key field from the request.
Stroom will generate a unique key for the running query and return it in the response.
However, in any subsequent requests for that running query, the client should include the key field, using the value from the previous response.
If you have static request JSON files then you can easily remove the key field using
jq
as follows:
12.4 - Upgrade Notes
Warning
Please read this section carefully in case any of it is relevant to your Stroom instance.Java Version
Stroom v7.2 requires Java v17. Previous versions of Stroom used Java v15 or lower. You will need to upgrade Java on the Stroom and Stroom-Proxy hosts to the latest patch release of Java v17.
Regex Performance Issue in XSLT Processing
v7.2 of Stroom uses a newer version of the Saxon XML processing library. Saxon is used for all pipeline processing. There is a bug in this version of Saxon which means that case insensitive regular expression matching performs very badly, i.e. it can be orders of magnitude slower than a case sensitive regex. This bug has been reported to Saxon and has been fixed but not yet released. It is likely a future release of Stroom will include a new version of Saxon that addresses this issue.
The performance issue will show itself when multiple pipelines with effected XSLTs are being processed concurrently.
This impacts XSLT/Xpath functions like matches() that use the i flag for case insensitive matching.
If you do not use any case-insensitive regular expressions in your XSLTs then you do not need to do anything.
Until Stroom is changed to used a new version of Saxon with a fix, you will have to change the XSLTs that use the i flag in one of the following ways:
-
Re-write the regular expression to use case sensitive matching, E.g:
matches('CATHODE', '^cat.*', 'i')=>matches('CATHODE', '^[cC][aA][tT].*')
This is the preferred option, but may not be possible for all regular expressions. -
Add the flag
;jto force Saxon to use the Java regular expression engine instead of the Saxon one, E.g:
matches('CATHODE', '^cat.*', 'i')=>matches('CATHODE', '^cat.*', 'i;j')
As this involves changing the regular expression engine it is possible that there will be subtle differences in the behaviour between the Saxon and Java engines. Regular expression engines are notorious for having subtle differences as there is no one standard for regular expressions.
Tagging Entities
As described in Document Tagging Stroom now pre-populates the filter of some of the tree pickers with pre-configured tags to limit the entities returned. If you do nothing then after upgrade these tree pickers will show no matching entities to the user.
You have two options:
-
Tag entities with the pre-configured tags so they are visible in the tree pickers.
To do this you need to find and tag the following entities:
- Tag all reference loader pipelines (those using the
ReferenceDataFilter
pipeline element) with
reference-loader(or whatever value(s) is/are set instroom.ui.referencePipelineSelectorIncludedTags). - Tag all extraction pipelines (those using the
SearchResultOutputFilter
pipeline element) with
extraction(or whatever value(s) is/are set instroom.ui.query.dashboardPipelineSelectorIncludedTags).
Any new entities matching the above criteria also need to be tagged in this way to ensure users see the correct entities. The new Find Content is useful for tracking down Pipelines that contain a certain element.
The property
stroom.ui.query.viewPipelineSelectorIncludedTagsis not an issue for an upgrade to v7.2 as Views did not exist prior to this version. All new dynamic extraction pipeline entities (those using the DynamicSearchResultOutputFilter pipeline element) need to be tagged withdynamicandextraction(or whatever value(s) is/are set instroom.ui.query.viewPipelineSelectorIncludedTags) - Tag all reference loader pipelines (those using the
ReferenceDataFilter
pipeline element) with
-
Change the system properties to not pre-populate the filters. If you do not want to use this feature then you can just clear the values of the following properties:
stroom.ui.query.dashboardPipelineSelectorIncludedTagsstroom.ui.query.viewPipelineSelectorIncludedTagsstroom.ui.referencePipelineSelectorIncludedTags
Reference Data Store
See Partitioned Reference Data Stores for details of the changes to reference data stores.
No intervention is required on upgrade for this change, this section is for information purposes only, however it is recommended that you take a backup copy of the existing reference data store files before booting the new version of Stroom.
To do this, make a copy of the files in the directory specified by stroom.pipeline.referenceData.lmdb.localDir.
If there is a problem then you can replace the store with the copy and try again.
Stroom will automatically migrate reference data from the legacy single data store into multiple Feed specific stores.
The legacy store exists in the directory configured by stroom.pipeline.referenceData.lmdb.localDir.
Each feed specific store will be in a sub-directory with a name like USER-DETAILS-REFERENCE___309e1ca0-7a5f-4f05-847b-b706805d758c (i.e. a file system safe version of the Feed name and the Feed’s
UUID
UUID
A Universally Unique Identifier for uniquely identifying something. UUIDs are used as the identifier in Doc Refs. An example of a UUID is 4ffeb895-53c9-40d6-bf33-3ef025401ad3.Click to see more details....
The migration happens on an as-needed basis. When a lookup is called from an XSLT, if the required reference stream is found to exist in the legacy store then it will be copied into the appropriate Feed specific store (creating the store if required). After being copied, the stream in the legacy store will be marked as available for purge so will get purged on the next run of the job Ref Data Off-heap Store Purge.
When Stroom boots it will delete a legacy store if it is found to be empty, so eventually the legacy store will cease to exist.
Depending on the speed of the local storage used for the reference data stores, the migration of streams and the subsequent purge from the legacy store may slow down processing until all the required migrations have happened. The migration is a trade-off between the additional time it would take to re-load all the reference streams (rather than just copying them from the legacy store) and the dedicated lock on the legacy store that all migrations need to acquire.
If you experience performance problems with reference data migrations or would prefer not to migrate the date then you can simply delete the legacy stores prior to running Stroom v7.2 for the first time.
The legacy store can be found in the directory configured by stroom.pipeline.referenceData.lmdb.localDir.
Simply delete the files data.mdb and lock.mdb (if present).
With the store deleted, stroom will simply load all reference streams as required with no migration.
Database Migrations
When Stroom boots for the first time with a new version it will run any required database migrations to bring the database schema up to the correct version.
Warning
It is highly recommended to ensure you have a database backup in place before booting stroom with a new version. This is to mitigate against any problems with the migration. It is also recommended to test the migration against a copy of your database to ensure that there are no problems when you do it for real.On boot, Stroom will ensure that the migrations are only run by a single node in the cluster. This will be the node that reaches that point in the boot process first. All other nodes will wait until that is complete before proceeding with the boot process.
It is recommended however to use a single node to execute the migration.
To avoid Stroom starting up and beginning processing you can use the migrate command to just migrate the database and not fully boot Stroom.
See migrate command for more details.
Migration Scripts
For information purposes only, the following is a list of all the database migrations that will be run when upgrading from v7.0 to v7.2.0. The migration script files can be viewed at github.com/gchq/stroom .
7.1.0
stroom-config
V07_01_00_001__preferences.sql - stroom-config/stroom-config-global-impl-db/src/main/resources/stroom/config/global/impl/db/migration/V07_01_00_001__preferences.sql
stroom-explorer
V07_01_00_005__explorer_favourite.sql - stroom-explorer/stroom-explorer-impl-db/src/main/resources/stroom/explorer/impl/db/migration/V07_01_00_005__explorer_favourite.sql
stroom-security
V07_01_00_001__add_stroom_user_cols.sql - stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_01_00_001__add_stroom_user_cols.sql
V07_01_00_002__rename_preferred_username_col.sql - stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_01_00_002__rename_preferred_username_col.sql
7.2.0
stroom-analytics
V07_02_00_001__analytics.sql - stroom-analytics/stroom-analytics-impl-db/src/main/resources/stroom/analytics/impl/db/migration/V07_02_00_001__analytics.sql
stroom-annotation
V07_02_00_005__annotation_assigned_migration_to_uuid.sql - stroom-annotation/stroom-annotation-impl-db/src/main/resources/stroom/annotation/impl/db/migration/V07_02_00_005__annotation_assigned_migration_to_uuid.sql
V07_02_00_010__annotation_entry_assigned_migration_to_uuid.sql - stroom-annotation/stroom-annotation-impl-db/src/main/resources/stroom/annotation/impl/db/migration/V07_02_00_010__annotation_entry_assigned_migration_to_uuid.sql
stroom-config
V07_02_00_005__preferences_column_rename.sql - stroom-config/stroom-config-global-impl-db/src/main/resources/stroom/config/global/impl/db/migration/V07_02_00_005__preferences_column_rename.sql
stroom-dashboard
V07_02_00_005__query_add_owner_uuid.sql - stroom-dashboard/stroom-storedquery-impl-db/src/main/resources/stroom/storedquery/impl/db/migration/V07_02_00_005__query_add_owner_uuid.sql
V07_02_00_006__query_add_uuid.sql - stroom-dashboard/stroom-storedquery-impl-db/src/main/resources/stroom/storedquery/impl/db/migration/V07_02_00_006__query_add_uuid.sql
stroom-explorer
V07_02_00_005__remove_datasource_tag.sql - stroom-explorer/stroom-explorer-impl-db/src/main/resources/stroom/explorer/impl/db/migration/V07_02_00_005__remove_datasource_tag.sql
stroom-security
V07_02_00_100__query_add_owners.sql - stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_02_00_100__query_add_owners.sql
V07_02_00_101__processor_filter_add_owners.sql - stroom-security/stroom-security-impl-db/src/main/resources/stroom/security/impl/db/migration/V07_02_00_101__processor_filter_add_owners.sql
12.5 - Change Log
For a detailed list of all the changes in v7.2 see: v7.2 CHANGELOG
13 - Version 7.1
For a detailed list of the changes in v7.1 see the changelog
TODO
Complete this section14 - Version 7.0
For a detailed list of the changes in v7.0 see the changelog
Integrated Authentication
The previously standalone (in v6) stroom-auth-service and stroom-auth-ui services have been integrated into the core stroom application. This simplifies the installation and configuration of Stroom.
Configuration Properties Improvements
Configuration is now provided by YAML files on boot
Previously Stroom used a flat .conf file to manage the application configuration.
Application logging was configured either via a .yml file (in v6) or in an .xml file (in v5).
Now Stroom uses a single .yml file to configure the application and logging.
This file is different to the .yml files(s) used in the docker compose configuration.
The YAML file provides a more logical hierarchical structure and support for typed values (longs, doubles, maps, lists, etc.).
The YAML configuration is intended for configuration items that are either needed to bootstrap Stroom or have values that are specific to a node. Cluster wide configuration properties are still stored in the database and managed via the UI.
There has been a change to the precedence of the configuration properties held in different locations (YAML, database, default) and this is described in Properties.
Stroom Home and relative paths
The concept of Stroom Home has been introduced.
Stroom Home allows for one path to be configured and for all other configurable paths to default to being a child of this path.
This keeps all configured directories in one place by default.
Each configured directory can be set to an absolute path if a location outside Stroom Home is required.
If a relative path is used it will be relative to Stroom Home.
Stroom Home can be configured with the property stroom.path.home.
Improved Properties UI screens that tell you the values over the cluster
Previously the Properties UI screens could only tell you the values held within the database and not the value that a node was actually using. The Properties screens have been improved to tell you the source of a property value and where multiple values exist across the cluster, which nodes have what values. See Properties.
Validation of Configuration Property Values
Validation of configuration property values is now possible. The validation rules are defined in the application code and allow for things like:
- Ensuring that a regex pattern is a valid pattern
- Setting maximum or minimum values to numeric properties.
- Ensuring a property has a value.
Validation will be enforced on application boot or when a value is edited via the UI.
Hot Loading of Node Configuration
Now that node specific configuration is managed via the YAML configuration file Stroom will detect changes to this file and update the configuration properties accordingly. Some properties however do not support being changed at runtime so will still require either the whole system or the UI nodes to be restarted.
Data retention impact summary
The Data_Retention screen now provides an Impact Summary tab that will show you a summary of what will be deleted by the current active rules. The summary is based on the rules as they currently are in the UI, so it allows you to see the impact before saving rule changes. The summary is a count of the number of streams that will be deleted by each rule, broken down by feed and stream type. In very large systems with a lot of data or where complex rules are in place the summary may take a some time (minutes) to produce.
See Data Retention for more details.
Fuzzy Finding in Quick Filters and Suggestion Text Fields
A richer fuzzy find algorithm has been added to the Quick filter search fields. It has also been added to some text input fields with suggestion fields, e.g. Feed Name input fields. This makes finding values or rows in a table faster and more precise.
See Finding Things for more details.
New (off-heap) memory efficient reference data
The reference data feature in previous versions of Stroom loaded the reference data on demand and held it in Java’s heap memory. In large systems or in pipelines doing reference data lookups across a wide time range this can lead to very large heap sizes.
In v7 Stroom now uses an off-heap, disk backed store (LMDB) for the reference data.
This removes all reference data (with the exception of context lookups) from the Java heap, so the -Xmx value can be reduced.
In large systems this can mean keeping your -Xmx value below the 32Gb threshold to further reduce the memory usage.
Because the store is disk backed frequently used reference data can be kept in the store to reduce the loading overhead.
As the reference data is held off-heap, Stroom can make use of all available free RAM for the reference data.
See Reference Data
Reference Data API
A RESTful API has been added for the reference data store. This primarily allows reference lookups to be performed by external systems.
Text editor improvements
The Ace text editor is used widely in Stroom for such things as editing XSLTs, editing dashboard column expressions, viewing stream data and stepping. There have been a number of improvements to this editor.
See Editing and Viewing Text Data
Editor context menu
Additional options have been added to the context menu in the text editor:
- Toggle soft line wrapping of long lines.
- Toggle viewing hidden characters, e.g. tabs, spaces, line breaks.
- Toggle Vim key bindings. The Ace editor does not implement all Vim functionality but supports the core key bindings.
- Toggle auto-completion. Completion is triggered using
ctrl+space. - Toggle live auto-completion. Completion is triggered as you type.
- Toggle the inclusion of snippets in the auto-complete suggestions.
Auto-completion and snippets
Most editor screens now support basic auto-completion of existing words found in the text. Some editor screens, such as XSLT, dashboard column expressions and Javascript scripts also support keyword and snippet completion.
Data viewing improvements
The way data is viewed in Stroom has changed to improve the viewing of large files or files with no line breaks. Previously a set number of lines of data would be fetched for display on the page in the Data Viewer. This did not work for data that has no line breaks as Stroom would then try to fetch all data.
In v7 Stroom works at the character level so can fetch a reasonable number of characters for display whether they are all one line or spread over multiple lines.
The viewing of data has been separated into two mechanisms, Data Preview and Source View.
See Editing and Viewing Text Data
Data Preview
This is the default view of the data. It displays the first n characters (configurable) of the data. It will attempt the format the data, e.g. showing pretty-printed XML. You cannot navigate around the data.
Source View
This view is intended for seeing the actual data in its raw un-formatted form and for navigating around it. This view provides navigation controls to define the range of data being display, e.g. from a character offset, line number or line and column.
You can now query data, server tasks and processing tasks on dashboards
TODO
Complete this sectionData actions such as delete, download, reprocess now provide an impact summary before proceeding.
TODO
Complete this sectionIndex volume groups for easier index volume assignment
TODO
Complete this sectionKafka Integration
New Kafka Configuration Entity
Integration with Apache Kafka was introduced in v6 however the way the connection to Kafka cluster(s) is configured has been improved. We have introduced a new entity type called Kafka Configuration that can be created/managed via the explorer tree. This means Stroom can integrate with many Kafka clusters or connect to a cluster using different sets of Kafka Configuration properties. The Kafka Configuration entity provides an editor for setting all the Kafka specific configuration properties. Pipeline elements that use Kafka now provide a means to select the Kafka Configuration to use.
TODO
Add user guide section on Kafka configurationAn Improved Pipeline Element for Sending Data to Kafka
The previous Kafka pipeline elements in v6 have been replaced with a single StandardKafkaProducer element. The new element allows for the dynamic construction of a Kafka Producer message via an XML document conforming to the kafka-records XmlSchema. With this new element events can be translated into kafka records which will be then given to the Kafka Producer to send to the Kafka Cluster. This allows for complete control of things like timestamps, topics, keys, values, etc.
TODO
Add user guide section on Kafka Standard ProducerNo limitations on data reprocessing
TODO
Complete this sectionImproved REST API
A rich REST API for all UI accessible functions
The architecture of the Stroom UI has been changed such that all communication between the UI and the back end is via REST calls. This means all of these REST calls are available as an API for users of Stroom to take advantage of. It opens up the possibility for interacting with Stroom via scripts or from other applications.
Swagger UI to document REST API methods
The Swagger UI and specification file have been improved to include all of the API methods available in Stroom.
Improved architecture with separate modules with individual DB access to spread load.
The architecture of the core Stroom application has been fundamentally changed in v7 to internally break up the application into its functional areas. This separation makes for a more logical code base and allows for the possibility of each functional area having its own database instance, if required.
Java 12
Stroom v7 now runs on the Java 12 JVM.
MySQL 8 support.
Stroom v7 has been changed to support MySQL v8, opening up the possibility of using features like group replication.
15 - Version 6.1
For a detailed list of the changes in v6.1 see the changelog
TODO
Version 6.1 release notes need populating.16 - Version 6.0
For a detailed list of the changes in v6.0 see the changelog
OAuth 2.0/OpenID Connect authentication
Authentication for Stroom provided by an external service rather than a service internal to Stroom. This change allows support for broader corporate authentication schemes and is a key requirement for enabling the future microservice architecture for Stroom.
API keys for third party clients
Anyone wishing to make use of the data exposed by Stroom’s services can request an API key. This key acts as a password for their own applications. It allows administrators to secure and manage access to Stroom’s data.
HBase backed statistics store
This new implementation of statistics (Stroom-Stats) provides a vastly more scalable time series DB for large scale collection of Stroom’s data aggregated to various time buckets. Stroom-Stats uses Kafka for ingesting the source data.
Data receipt filtering
Data arriving in Stroom has meta data that can be matched against a policy so that certain actions can be taken. This could be to receive, drop or reject the data.
Filtering of data also applies to Stroom proxy where each proxy can get a filtering policy from an upstream proxy or a Stroom instance.
Data retention policies
The length of time that data will be retained in Stroom’s stream store can be defined by creating data retention rules. These rules match streams based on their meta data and will automatically delete data once the retention period associated with the rule is exceeded.
Dashboard linking
Links can be created in dashboards to jump to other dashboards or other external sites that provide additional contextual information.
Search API
The search system used by Dashboards can be used via a restful API. This provides access to data stored in search indices (including the ability to extract data) and statistics stores. The data fetched via the search API can be received and processed via an external system.
Kafka appender and filter
New pipeline elements for writing XML or text data to a Kafka topic. This provides more options for using Stroom’s data in other systems.