The page that you are currently viewing is for an old version of Stroom (7.4). The documentation for the latest version of Stroom (7.12) can be found using the version drop-down at the top of the screen or by clicking here.
New Features
Look and Feel
New User Interface Design
The user interface has had a bit of a re-design to give it a more modern look and to make it conform to accessibility standards.
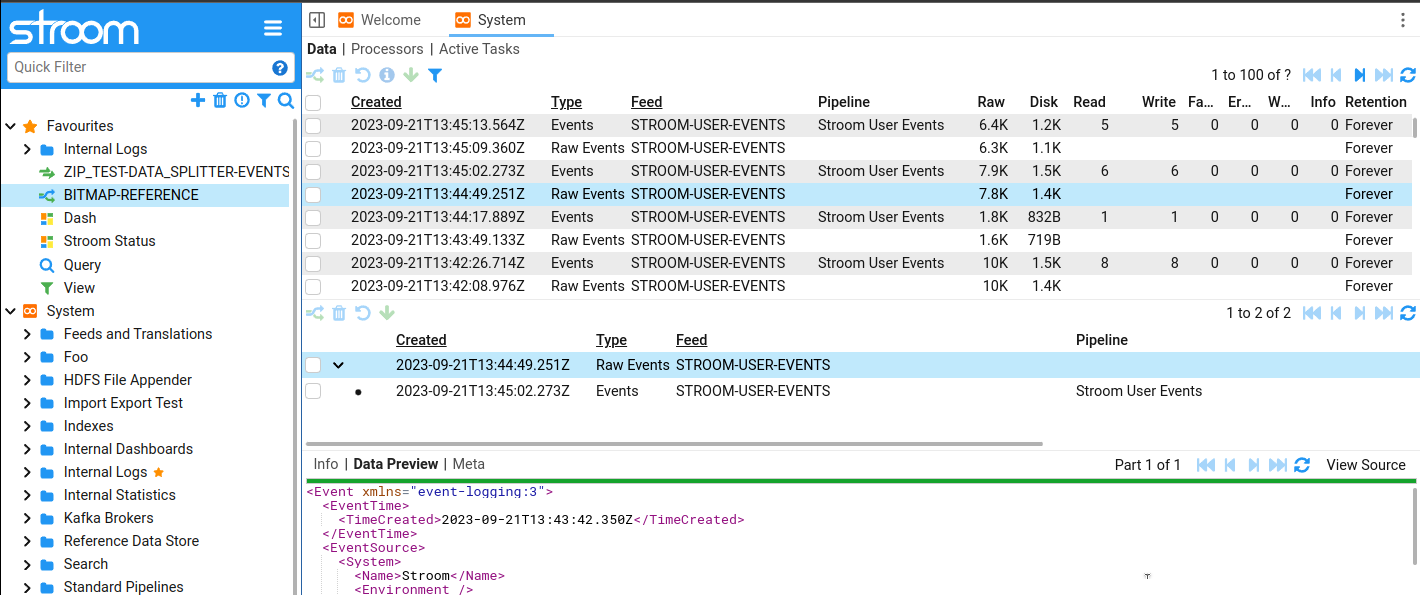
User Preferences
Now you can customise Stroom with your own personal preferences. From the main menu , select:
You can also change the following:
-
Layout Density - This controls the layout spacing to fit more or less user interface elements in the available space.
-
Font - Change font used in Stroom.
-
Font Size - Change the font size used in Stroom.
-
Transparency - Enables partial transparency of dialog windows. Entirely cosmetic.
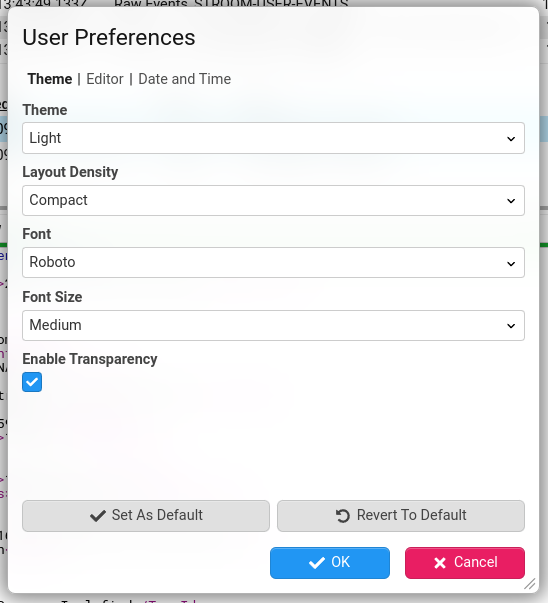
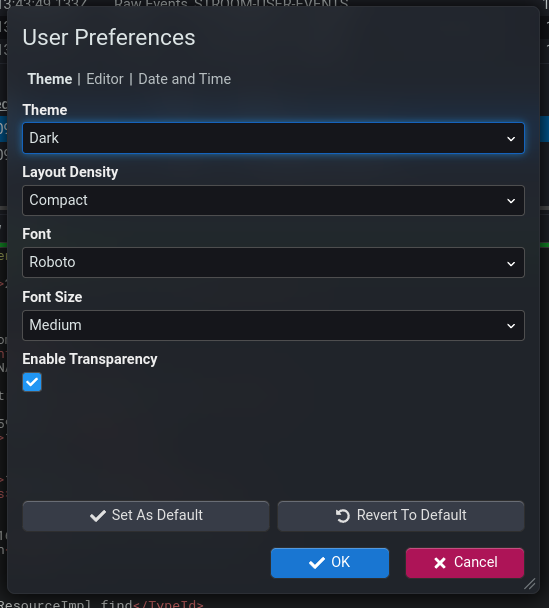
Theme
Choose between the traditional light theme and a new dark theme with light text on a dark background.
Editor Preferences
The Ace text editor used within Stroom is used for editing things like XSLTs and viewing stream data. It can now be personalised with the following options:
-
Theme - The colour theme for the editor. The theme options will be applicable to the main user interface theme, i.e. light/dark editor themes. The theme affects the colours used for the syntax highlight content.
-
Key Bindings - Allows you to set the editor to use Vim key bindings for more powerful text editing. If you don’t know what Vim is then it is best to stick to Standard. If you would like to learn how to use Vim, install
vimtutor. Note: The Ace editor does not fully emulate Vim, not all Vim key bindings work and there is limited command mode support. -
Live Auto Completion - Set this to On if you want the editor code completion to make suggestions as you type. When set to Off you need to press Ctrl ^ + Space ␣ to show the suggestion dialog.
Date and Time
You can now change the format used for displaying the date and time in the user interface. You can also set the time zone used for displaying the date and time in the user interface.
Note
Stroom works in UTC time internally. Changing the time zone only affects display of dates/times, not how data is stored or the dates/times in events.
Dashboard Changes
Design Mode
A Design Mode has been introduced to Dashboards and is toggled using the button . When a Dashboard is in design mode, the following functionality is enabled:
- Adding components to the Dashboard.
- Removing components from the Dashboard.
- Moving Dashboard components within panes, to new panes or to existing panes.
- Changing the constraints of the Dashboard.
On creation of a new Dashboard, Design Mode will be on so the user has full functionality. On opening an existing Dashboard, Design Mode will be off. This is because typically, Dashboards are viewed more than they are modified.
Visual Constraints
Now it is possible to control the horizontal and vertical constraints of a Dashboard. In Stroom 7.0, a dashboard would always scale to fit the user’s screen. Sometimes it is desirable for the dashboard canvas area to be larger than the screen so that you have to scroll to see it all. For example you may have a dashboard with a large number of component panes and rather than squashing them all into the available space you want to be able to scroll vertically in order to see them all.
It is now possible to change the horizontal and/or vertical constraints to fit the available width/height or to be fixed by clicking the button.
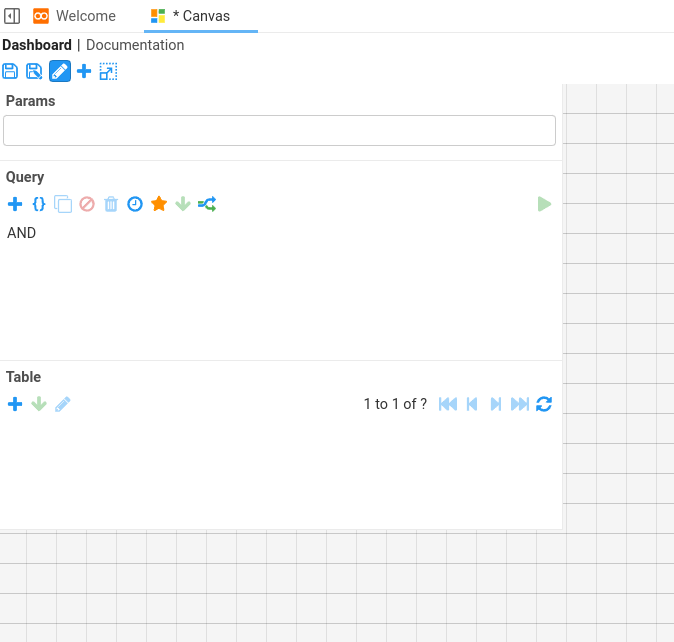
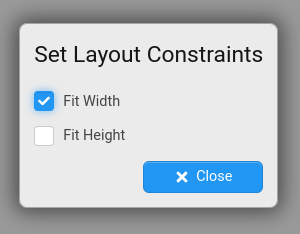
The edges of the canvas can be moved to shrink/grow it.
Explorer Filter Matches
Filtering in the explorer has been changed to highlight the filter matches and to search in folders that themselves are a match. In Stroom v7.0 folders that matched were not expanded. Match highlighting makes it clearer what items have matched.
Document Permissions Screen
The document and folder permissions screens have been re-designed with a better layout and item highlighting to make it clearer which permissions have been selected.
Editor Completion snippets
The number of available editor completion snippets has increased. For a list of the available completion snippets see the Completion Snippet Reference.
Note
Completion snippets are an evolving feature so if you have an requests for generic completion snippets then raise an issue on GitHub and we will consider adding them in.Partitioned Reference Data Stores
In Stroom v7.0 reference data is loaded using a reference loader pipeline and the key/value pairs are stored in a single disk backed reference data store on each Stroom node for fast lookup. This single store approach has led to high contention and performance problems when purge operations are running against it at the same time or multiple reference Feeds are being loaded at the same time.
In Stroom v7.2 the reference data key/value pairs are now stored in multiple reference data stores on each node, with one store per Feed. This reduces contention as reference data for one Feed can be loading while a purge operation is running on the store for another Feed or reference data for multiple Feeds can be loaded concurrently. Performance is still limited by the file system that the stores are hosted on.
All reference data stores are stored in the directory defined by stroom.pipeline.referenceData.lmdb.localDir.
See Also
See the upgrade notes for the reference data stores.
Improved OAuth2.0/OpenID Connect Support
The support for Open ID Connect (OIDC) authentication has been improved in v7.2. Stroom can be integrated with AWS Cognito, MS Azure AD, KeyCloak and other OIDC Identity Providers (IDPs) .
Data receipt in Stroom and Stroom-Proxy can now enforce OIDC token authentication as well as certificate authentication. The data receipt authentication is configured via the properties:
stroom.receive.authenticationRequiredstroom.receive.certificateAuthenticationEnabledstroom.receive.tokenAuthenticationEnabled
Stroom and Stroom-Proxy have also been changed to use OIDC tokens for API endpoints and inter-node communications. This currently requires the OIDC IDP to support the client credentials flow.
Stroom can still be used with its own internal IDP if you do not have an external IDP available.
User Naming Changes
The changes to add integration with external OAuth 2.0/OpenID Connect identity provides has required some changes to the way users in Stroom are identified.
Previously in Stroom a user would have a unique username that would be set when creating the account in Stroom.
This would typically by a human friendly name like jbloggs or similar.
It would be used in all the user/permission management screens to identify the user, for functions like current-user(), for simple audit columns in the database (create_user and update_user) and for the audit events stroom produces.
With the integration to external identity providers this has had to change a little.
Typically in OpenID Connect IDPs the unique identity of a principle (user) is fairly unfriendly
UUID
.
The user will likely also have a more human friendly identity (sometimes called the preferred_username) that may be something like jblogs or jblogs@somedomain.x.
As per the OpenID Connect specification, this friendly identity may not be unique within the IDP, so Stroom has to assume this also.
In reality this identity is typically unique on the IDP though.
The IDP will often also have a full name for the user, e.g. Joe Bloggs.
Stroom now stores and can display all of these identities.
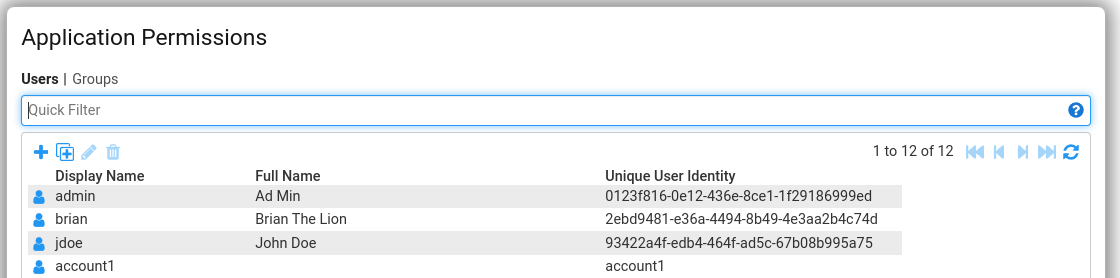
- Display Name - This is the (potentially non-unique) preferred user name held by the IDP, e.g.
jbloggsorjblogs@somedomain.x. - Full Name - The user’s full name, e.g.
Joe Bloggs, if known by the IDP. - Unique User Identity - The unique identity of the user on the IDP, which may look like
ca650638-b52c-45af-948c-3f34aeeb6f86.
In most screens, Stroom will display the Display Name. This will also be used for any audit purposes. The permissions screen show all three identities so an admin can be sure which user they are dealing with and be able to correlate it with one on the IDP.
User Creation
When using an external IDP, a user visiting Stroom for the first time will result in the creation of a Stroom User record for them. This Stroom User will have no permissions associated with it. To improve the experience for a new user it is preferable for the Stroom administrator to pre-create the Stroom User account in Stroom with the necessary permissions.
This can be done from the Application Permissions screen accessed from the Main menu ().
You can create a single Stroom User by clicking the button.
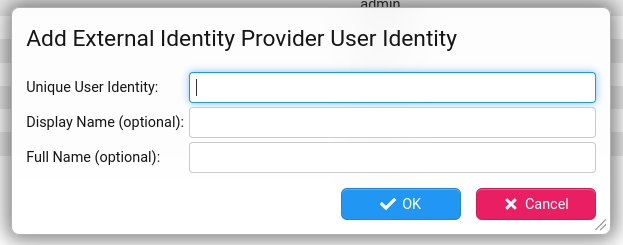
Or you can create multiple Stroom Users by clicking the button.
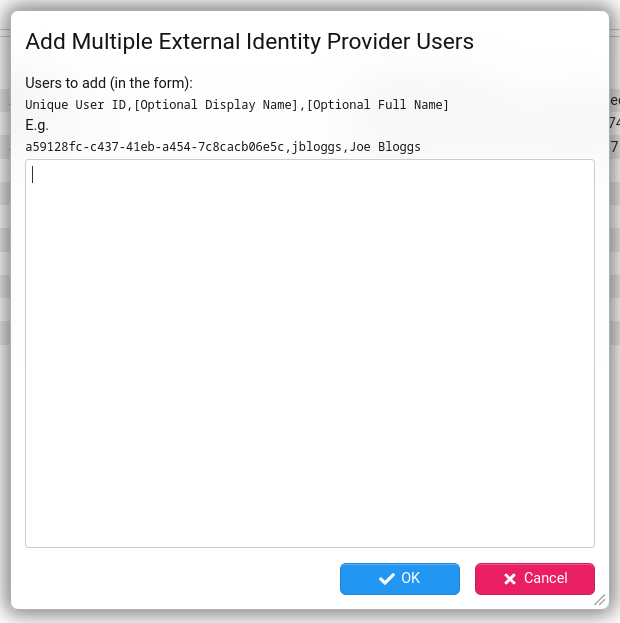
In both cases the Unique User ID is mandatory, and this must be obtained from the IDP. The Display Name and Full Name are optional, as these will be obtained automatically from the IDP by Stroom on login. It can be useful to populate them initially to make it easier for the administrator to see who is who in the list of users.
Once the user(s) are created, the appropriate permissions/groups can be assigned to them so that when they log in for the first time they will be able to see the required content and be able to use Stroom.
New Document types
The following new types of document can be created and managed in the explorer tree.
Documentation
It is now possible to create a Documentation entity in the explorer tree. This is designed to hold any text or documentation that the user chooses to write in Markdown format. These can be useful for providing documentation within a folder in the tree to collectively describe all the items in that folder, or to provide a useful README type document. It is not possible to add documentation to a folder entity itself, so this is useful substitute.
See Also
See Documenting Content for details on the Markdown syntax.
Elastic Cluster
Elastic Cluster provides a means to define a connection to an Elasticsearch Cluster. You would create one of these documents for each Elasticsearch cluster that you want to connect to. It defines the location and authentication details for connecting to an elastic cluster.
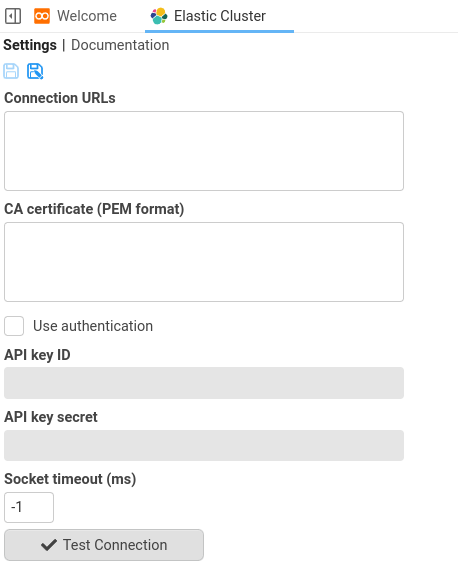
Thanks to Pete K for his help adding the new Elasticsearch integration features.
Elastic Index
An Elastic Index document is a data source for searching one or more indexes on Elasticsearch.
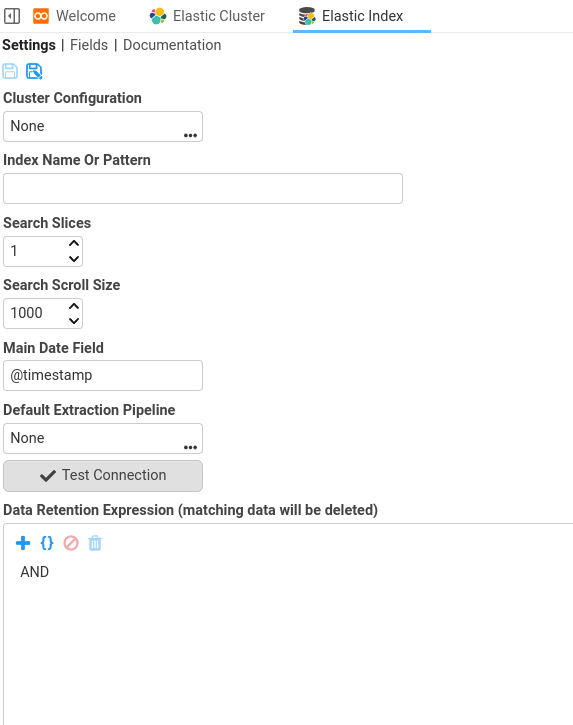
See Also
New Searchables
A Searchable is one of the data sources that appear at the top level of the tree pickers but not in the explorer tree.
Analytics
Adds the ability to query data from Table Builder type Analytic Rules.
New Pipeline Elements
DynamicIndexingFilter
DynamicIndexingFilterThis filter element is used by Views and Analytic Rules. Unlike IndexingFilter where you have to specify all the fields in the index up front for them to visible to the user in a Dashboard, DynamicIndexingFilter allows fields to be dynamically created in the XSLT based on the event being indexed. These dynamic fields are then ‘discovered’ after the event has been added to the index.
DynamicSearchResultOutputFilter
DynamicSearchResultOutputFilterThis filter element is used by Views and Analytic Rules. Unlike SearchResultOutputFilter this element can discover the fields found in the extracted event when the extraction pipeline creates fields that are not present in the index. These discovered field are then available for the user to pick from in the Dashboard/Query.
ElasticIndexingFilter
ElasticIndexingFilterElasticIndexingFilter is used to pass fields from an event to an Elasticsearch cluster to index.
See Also
Explorer Tree
Various enhancements have been made to the explorer tree.
Favourites
Users now have the ability to mark explorer tree entities as favourites. Favourites are user specific so each user can define their own favourites. This feature is useful for quick access to commonly used entities. Any entity or Folder at any level in the explorer tree can be set as a favourite. Favourites are also visible in the various entity pickers used in Stroom, e.g. Feed pickers.
An entity/folder can be added or removed from the favourites section using the context menu items :
An entity that is a favourite is marked with a in the main tree.
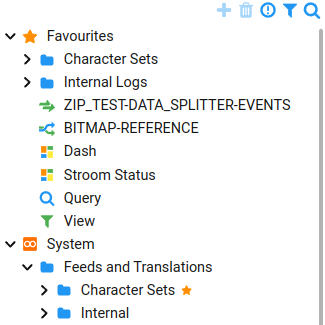
A change to a child item of a folder marked as a favourite will be reflected in both the main tree and the favourites section. All items marked as a favourite will appear as a top level item underneath the Favourites root, even if they have an ancestor folder that is also a favourite.
Thanks to Pete K for adding this new feature.
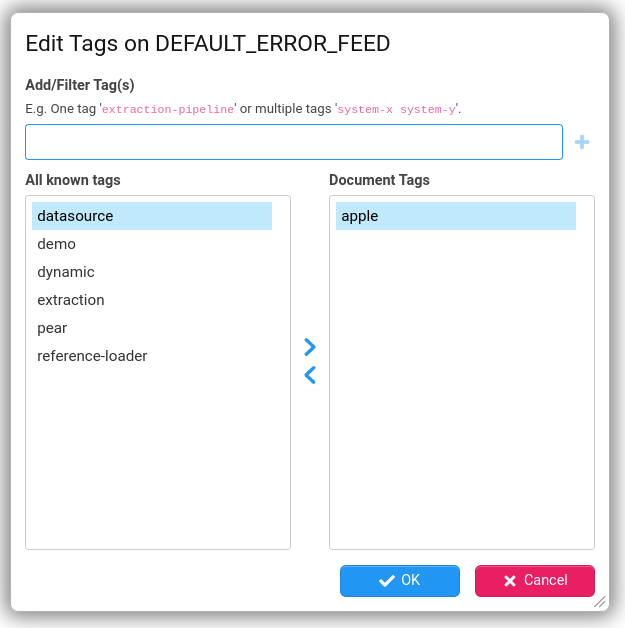
Document Tagging
You can now add tags to entities or folders in the explorer tree. Tags provide an additional means of searching for entities or folders. It allows entities/folders that reside in different folders to be associated together in one or more ways.
The tags on an entity/folder can be managed from the explorer tree context menu item:
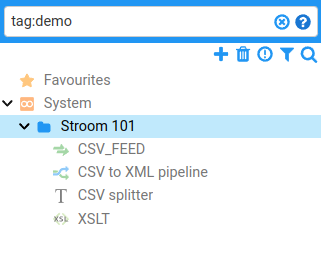
The explorer tree can be filtered by tag using the field prefix tag:, i.e. tag:extraction.
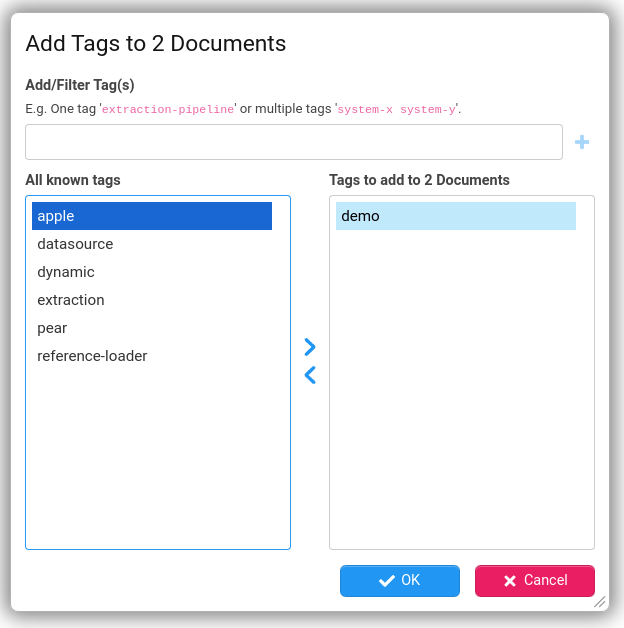
If multiple entities/folders are selected in the explorer tree then the following menu items are available:
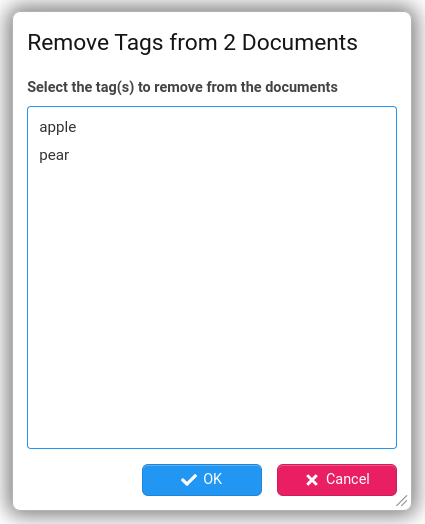
Pre-populated Tag Filters
Stroom comes pre-configured with some default tags.
The property that sets these is stroom.explorer.suggestedTags.
The defaults for this property are dynamic, extraction and reference-loader
These pre-configured tags are also used in some of the tree pickers in stroom to provide extra filtering of entities in the picker.
For example when selecting a Pipeline on an XSLT Filter the filter on the tree picker to select the pipeline will be pre-populated with tag:reference-loader so only reference loader pipelines are included.
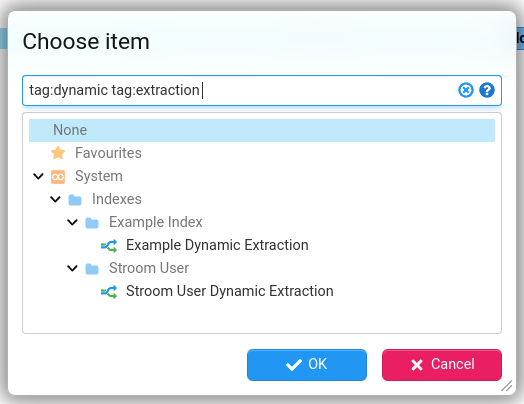
The following properties control the tags used to pre-populate tree picker filters:
stroom.ui.query.dashboardPipelineSelectorIncludedTagsstroom.ui.query.viewPipelineSelectorIncludedTagsstroom.ui.referencePipelineSelectorIncludedTags
See Also
See the migration task Tagging Entities for details on how to set up these pre-configured tags.
Copy Link to Clipboard
It is not possible to easily copy a direct link to a Document from the explorer tree. Direct links are useful if for example you want to share a link to a particular stroom dashboard.
To create a direct link, right click on the document you want a link for in the explorer tree and select:
You can then paste the link into a browser to jump directly to that document (authenticating as required).
Dependencies
It is not possible to jump to the Dependencies screen to see the dependencies or dependants of a particular document. In the explorer tree right click on a document and select one of:
This will open the Dependencies screen with a filter pre-populated to show all documents that are dependencies of the selected document.
This will open the Dependencies screen with a filter pre-populated to show all documents that depend on the selected document.
Broken Dependency Alerts
It is now possible to see alert icons in the explorer tree to highlight documents that have broken dependencies. The user can hover over these icons to display more information about the broken dependency. The explorer tree will show the alert icon against all documents with a broken dependency and all of its ancestor folders.
A broken dependency means a document (e.g. an XSLT) has a dependency on another document (e.g. a reference loader Pipeline) but that document does not exist. Broken dependencies can occur when a user deletes a document that other documents depend on, or by a partial import of content.
This feature is disabled by default as it can have a significant effect on performance of the explorer tree with large trees.
To enable this feature, set the property stroom.explorer.dependencyWarningsEnabled to true.
Once enabled at the system level by the property, the display of alerts in the tree can be enabled/disabled by the user using the Toggle Alerts button.
Entity Documentation
It is now possible to add documentation to all entities / documents in the explorer tree, e.g. adding documentation on a Feed. Each entity now has a Documentation sub-tab where the user can enter any documentation they choose about that entity. The documentation is written in Markdown syntax. It is not possible to add documentation to a Folder but you can create one or more a Documentation entities as a child item of that folder, see Documentation.
See Also
See Documenting Content for details on the Markdown syntax.
Find Content
You can now search the content of entities in the explorer tree, e.g. searching within XSLTs, Dictionaries, Pipeline structure, etc. This feature is available from the main menu :
It can also be accessed by hitting Ctrl ^ + Shift ⇧ + f (unless an editor pane has focus).
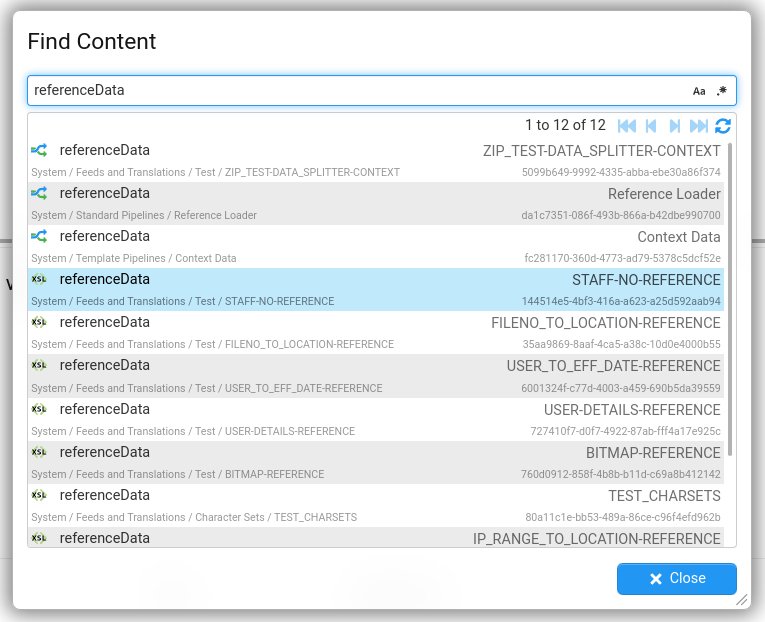
It is useful for finding which pipelines are using a certain element, or what XSLTs are using a certain stroom: function.
This is an early evolution of this feature and it is likely to be improved with time.
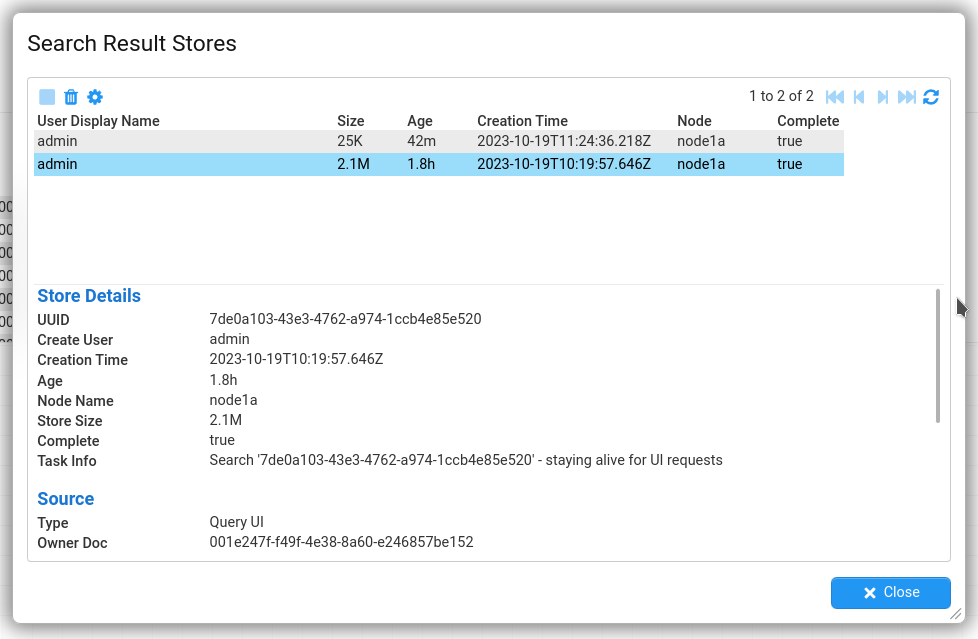
Search Result Stores
When a Dashboard/Query search is run, the results are written to a Search Results Store for that query. This stores reside on disk to reduce the memory used by queries. The Search Result Stores are stored on a single Stroom node and get created when a query is executed in a Dashboard, Query or Analytic Rule.
This screen provides an administrator with an overview of all the stores currently in existence in the Stroom cluster, showing details on their state and size. It can also be used to stop queries that are currently running or to delete the store entirely. Stores get deleted when the user closes the Dashboard or Query that created them.
Pipeline Stepper Improvements
The pipeline stepper has had a few user interface tweaks to make it easier to use.
Log Pane
When there are errors, warnings or info messages on a pipeline element they will now also be displayed in a pane at the bottom. This makes it easer to see all messages in one place.

The editor still displays icons with hover tips in the gutter on the appropriate line where the message has an associated line number.
The log pane can be hidden by clicking the icon.
Highlighting
The pipeline displayed at the top of the stepper now highlights elements that have log messages against them. This makes it easier to see when there is a problem with an element as you step through the data. The elements are given a coloured border according to the highest severity message on that element:
- Info - Blue
- Warning - Yellow
- Error - Red
- Fatal Error - Red (pulsating)

Filtering
Stroom has always had the ability to filter the data being stepped, however the feature was a little hidden (the Mange Step Filters icon).
Now you can right click on a pipeline element to manage the filters on that element. You can also clear its filters or the filters on all elements.
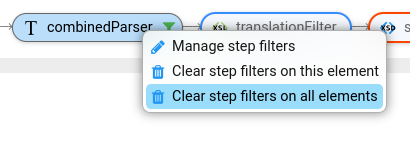
The pipeline now shows which elements have an active filter by displaying a filter icon.
Server Tasks
Auto Refresh
You can now enable/disable the auto-refreshing of the Server Tasks table using the button. Auto refresh is enabled by default. Disabling it is useful when you want to delete a task, as it will stop the table being refreshed just before you hit delete.
Line Wrapping
You can now enable/disable line wrapping in the Name and Info cells using the button. Line wrapping is disable by default. Enabling this is useful to see long Info cell values.
Info Popup
The Info popup has been changed to include the value from the Info column.
Proxy
Stroom-Proxy v7.2 has undergone a significant re-write in an attempt to address certain performance issues, make it more flexible and to allow data to be forked to many destinations.