This is the multi-page printable view of this section. Click here to print.
User Content
1 - Editing Text
Stroom uses the Ace text editor for editing and viewing text, such as XSLTs, raw data, cooked events, stepping, etc. The editor provides various useful features:
- Syntax highlighting
- Themes
- Find/replace (see Keyboard Shortcuts)
- Code auto-completion
Keyboard shortcuts
See Keyboard Shortcuts for details of the keyboard shortcuts available when using the Ace editor.
Vim key bindings
If you are familiar with the Vi/Vim text editors then it is possible to enable Vim key bindings in Stroom. This can be done in two ways.
Either globally by setting Editor Key Bindings to Vim in your user preferences:
Or within an editor using the context menu. This latter option allows you to temporarily change your bindings.
The Ace editor does not support all features of Vim however the core navigation/editing key bindings are present. The key supported features of Vim are:
- Visual mode and visual block mode.
- Searching with
/(javascript flavour regex) - Search/replace with commands like
:%s/foo/bar/g - Incrementing/decrementing numbers with Ctrl ^ + a / Ctrl ^ + b
- Code (un-)folding with z , o , z , c , etc.
- Text objects, e.g.
>,),],',",pparagraph,wword. - Repetition with the
.command. - Jumping to a line with
:<line no>.
Notable features not supported by the Ace editor:
- The following text objects are not supported
b- Braces, i.e{or[.t- Tags, i.e. XML tags<value>.s- Sentence.
- The
gcommand mode command, i.e.:g/foo/d - Splits
For a list of useful Vim key bindings see this cheat sheet , though not all bindings will be available in Stroom’s Ace editor.
Use of Esc key in Vim mode
The Esc key is bound to the close action in Stroom, so pressing Esc will typically close a popup, dialog, selection box, etc. Dialogs will not be closed if the Ace editor has focus but as Esc is used so frequently with Vim bindings it may be advisable to use an alternative key to exit insert mode to avoid accidental closure. You can use the standard Vim binding of Ctrl ^ + [ or the custom binding of k , b as alternatives to Esc .
Auto-Completion And Snippets
The editor supports a number of different types of auto-completion of text. Completion suggestions are triggered by the following mechanisms:
- Ctrl ^ + Space ␣ - when live auto-complete is disabled.
- Typing - when live auto-complete is enabled.
When completion suggestions are triggered the follow types of completion may be available depending on the text being edited.
- Local - any word/token found in the existing document. Useful if you have typed a long word and need to type it again.
- Keyword - A word/token that has been defined in the syntax highlighting rules for the text type, i.e.
functionis a keyword when editing Javascript. - Snippet - A block of text that has been defined as a snippet for the editor mode (XML, Javascript, etc.).
Snippets
Snippets allow you to quickly enter pre-defined blocks of common text into the editor.
For example when editing an XSLT you may want to insert a call-template with parameters.
To do this using snippets you can do the following:
-
Type
callthen hit Ctrl ^ + Space ␣ . -
In the list of options use the cursor keys to select
call-template with-paramthen hit Enter ↵ or Tab ↹ to insert the snippet. The snippet will look like<xsl:call-template name="template"> <xsl:with-param name="param"></xsl:with-param> </xsl:call-template> -
The cursor will be positioned on the first tab stop (the template name) with the tab stop text selected.
-
At this point you can type in your template name, e.g.
MyTemplate, then hit Tab ↹ to advance to the next tab stop (the param name) -
Now type the name of the param, e.g.
MyParam, then hit Tab ↹ to advance to the last tab stop positioned within the<with-param>ready to enter the param value.
Snippets can be disabled from the list of suggestions by selecting the option in the editor context menu.
Tab triggers
Some snippets can be triggered by typing an abbreviation and then hitting Tab ↹ to insert the snippet. This mechanism is faster than hitting Ctrl ^ + Space ␣ and selecting the snippet, if you can remember the snippet tab trigger abbreviations.
Available snippets
For a list of the available completion snippets see the Completion Snippet Reference.
Theme
The editor has a number of different themes that control what colours are used for the different elements in syntax highlighted text. The theme can be set User Preferences, from the main menu , select:
The list of themes available match the main Stroom theme, i.e. dark Ace editor themes for a dark Stroom theme.
2 - Naming Conventions
Stroom has been in use by GCHQ for many years and is used to process logs from a large number of different systems. This sections aims to provide some guidelines on how to name and organise your content, e.g. Feeds, XSLTs, Pipelines, Folders, etc. These are not hard rules and you do not have to follow them, however it may help when it comes to sharing content.
See Also
TODO
Complete this section3 - Documenting content
The screen for each Entity in Stroom has a Documentation sub-tab. The purpose of this sub-tab is to allow the user to provide any documentation about the entity that is relevant. For example a user might want to provide information about the system that a Feed receives data from, or document the purpose of a complex XSLT translation.
In previous versions of stroom this documentation was a small and simple Description text field, however now it is a full screen of rich text. This screen defaults to its read-only preview mode, but the user can toggle it to the edit mode to edit the content. In the edit mode, the documentation can be created/edited using plain text, or Markdown . Markdown is a fairly simple markup language for producing richly formatted text from plain text.
There are many variants of markdown that all have subtly different features or syntax. Stroom uses the Showdown markdown converter to render users’ markdown content into formatted text. This link is the definitive source for supported markdown syntax.
Note
The Showdown markdown processor used in stroom is not the same as the markdown processor used within this documentation site (stroom-docs), so there may be some subtle differences in syntax.Example Markdown Content
The following is a brief guide to the most common formatting that can be done with markdown and that is supported in Stroom.
# Markdown Example
This is an example of a markdown document.
## Headings Example
This is at level 2.
### Heading Level 3
This is at level 3.
#### Heading Level 4
This is at level 4.
## Text Styles
**bold**, __bold__, *italic*, _italic_, ***bold and italic***, ~~strike-through~~
## Bullets
Use four spaces to indent a sub-item.
* Bullet 1
* Bullet 1a
* Bullet 2
* Bullet 2a
## Numbered Lists
Use four spaces to indent a sub-item.
Using `1` for all items means the makrdown processor will replace them with the correct number, making it easier to re-order items.
1. Item 1
1. Item 1a
1. Item 1b
1. Item 2
1. Item 2a
1. Item 2b
## Quoted Text
> This is a quote.
Text
> This is another quote.
> It has multiple lines...
>
> ...and gaps and bullets
> * Item 1
> * Item 2
## Tables
Note `---:` to right align a column, `:---:` to center align it.
| Syntax | Description | Value | Fruit |
| ----------- | ----------- | -----:| :----: |
| Row 1 | Title | 1 | Pear |
| Row 2 | Text | 10 | Apple |
| Row 3 | Text | 100 | Kiwi |
| Row 4 | Text | 1000 | Orange |
Table using `<br>` for multi-line cells.
| Name | Description |
|-----------|-----------------|
| Row 1 | Line 1<br>Line2 |
| Row 2 | Line 1<br>Line2 |
## Links
Line: [title](https://www.example.com)
## Simple Lists
Add two spaces to the end of each line to stop each line being treated as a paragraph.
One
Two
Three
## Paragraphs
Lines not separated by a blank line will be joined together with a space between them.
Stroom will wrap long lines when rendered.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
## Task Lists
The `X` indicates a task has been completed.
* [x] Write the press release
* [ ] Update the website
* [ ] Contact the media
## Images
A non-standard syntax is supported to render images at a set size in the form of `<width>x<height>`.
Use a `*` for one of the dimensions to scale it proportionately.

## Separator
This is a horizontal rule separator
---
## Code
Code can be represented in-line like this `echo "hello world"` by surround it with single back-ticks.
Multi-line blocks of code can rendered with the appropriate syntax highlighting using a fenced block comprising three back-ticks.
Specify the language after the first set of three back ticks, or `text` for plain text.
Only certain languages are supported in Stroom.
**JSON**
```json
{
"key1": "some text",
"key2": 123
}
```
**XML**
```xml
<record>
<data name="dateTime" value="2020-09-28T14:30:33.476" />
<data name="machineIp" value="19.141.201.14" />
</record>
```
**bash**
```bash
#!/bin/bash
now="$(date)"
computer_name="$(hostname)"
echo "Current date and time : $now"
echo "Computer name : $computer_name"
```
Wrapping
Long paragraphs will be wrapped
Code Syntax Highlighting
This is an example of a fenced code block.
```xml
<record>
<data name="dateTime" value="2020-09-28T14:30:33.476" />
</record>
```
In this example, xml defines the language used within the fenced block.
Stroom supports the following languages for fenced code blocks.
If you require additional languages then please raised a ticket
here
. If your language is not currently supported or is just plain text then use text.
- text
- sh
- bash
- xml
- css
- javascript
- csv
- regex
- powershell
- sql
- json
- yaml
- properties
- toml
Fenced blocks with content that is wider than the pane will result in the fenced block having its own horizontal scroll bar.
Escaping Characters
It is common to use _ characters in
Feed
names, however if there are two of these in a word then the markdown processor will interpret them as italic markup.
To prevent this, either surround the word with back ticks to be rendered as code or escape each underscore with a \, i.e. THIS\_IS\_MY\_FEED. THIS_IS_MY_FEED.
HTML
While it is possible to use HTML in the documentation, its use is not recomended as it increases the complexity of the documentation content and requires that other users have knowledge of HTML. Markdown should be sufficient for most cases, with the possible exception of complex tables where HTML may be prefereable.
Note
No form of HTML scripting (i.e. Javascript) is supported within the documentation content.4 - Finding Things
Explorer Tree
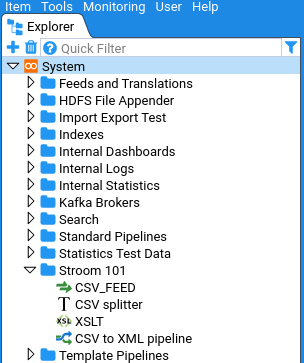
The Explorer Tree in stroom is the primary means of finding user created content, for example Feeds, XSLTs, Pipelines, etc.
Branches of the Explorer Tree can be expanded and collapsed to reveal/hide the content at different levels.
Filtering by Type
The Explorer Tree can be filtered by the type of content, e.g. to display only Feeds, or only Feeds and XSLTs. This is done by clicking the filter icon . The following is an example of filtering by Feeds and XSLTs.
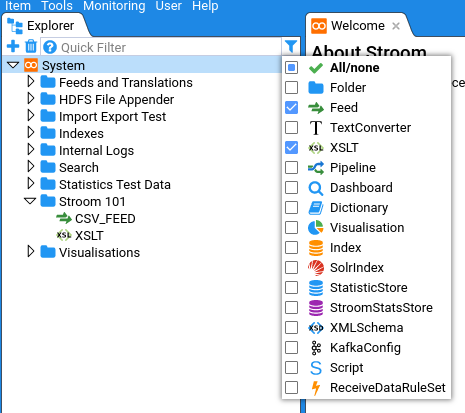
Clicking All/None toggles between all types selected and no types selected.
Filtering by type can also be achieved using the Quick Filter by entering the type name (or a partial form of the type name), prefixed with type:.
I.e:
type:feed
For example:
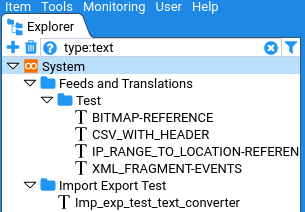
NOTE: If both the type picker and the Quick Filter are used to filter on type then the two filters will be combined as an AND.
Filtering by Name
The Explorer Tree can be filtered by the name of the entity. This is done by entering some text in the Quick Filter field. The tree will then be updated to only show entities matching the Quick Filter. The way the matching works for entity names is described in Common Fuzzy Matching
Filtering by UUID
What is a UUID?
The Explorer Tree can be filtered by the UUID of the entity. The UUID Universally unique identifier is an identifier that can be relied on to be unique both within the system and universally across all other systems. Stroom uses UUIDs as the primary identifier for all content (Feeds, XSLTs, Pipelines, etc.) created in Stroom. An entity’s UUID is generated randomly by Stroom upon creation and is fixed for the life of that entity.
When an entity is exported it is exported with its UUID and if it is then imported into another instance of Stroom the same UUID will be used. The name of an entity can be changed within Stroom but its UUID remains un-changed.
With the exception of Feeds, Stroom allows multiple entities to have the same name. This is because entities may exist that a user does not have access to see so restricting their choice of names based on existing invisible entities would be confusing. Where there are multiple entities with the same name the UUID can be used to distinguish between them.
The UUID of an entity can be viewed using the context menu for the entity. The context menu is accessed by right-clicking on the entity.
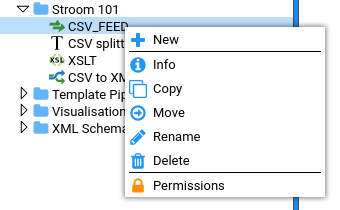
Clicking Info displays the entities UUID.
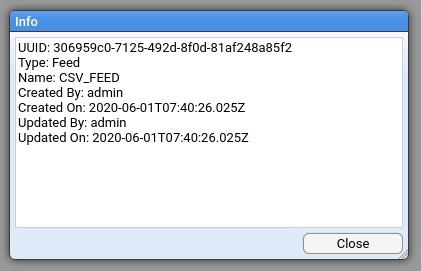
The UUID can be copied by selecting it and then pressing Ctrl ^ + c .
UUID Quick Filter Matching
In the Explorer Tree Quick Filter you can filter by UUIDs in the following ways:
To show the entity matching a UUID, enter the full UUID value (with dashes) prefixed with the field qualifier uuid, e.g. uuid:a95e5c59-2a3a-4f14-9b26-2911c6043028.
To filter on part of a UUID you can do uuid:/2a3a to find an entity whose UUID contains 2a3a or uuid:^2a3a to find an entity whose UUID starts with 2a3a.
Quick Filters
Quick Filter controls are used in a number of screens in Stroom. The most prominent use of a Quick Filter is in the Explorer Tree as described above. Quick filters allow for quick searching of a data set or a list of items using a text based query language. The basis of the query language is described in Common Fuzzy Matching.
A number of the Quick Filters are used for filter tables of data that have a number of fields.
The quick filter query language supports matching in specified fields.
Each Quick Filter will have a number of named fields that it can filter on.
The field to match on is specified by prefixing the match term with the name of the field followed by a :, i.e. type:.
Multiple field matches can be used, each separate by a space.
E.g:
name:^xml name:events$ type:feed
In the above example the filter will match on items with a name beginning xml, a name ending events and a type partially matching feed.
All the match terms are combined together with an AND operator. The same field can be used multiple times in the match. The list of filterable fields and their qualifier names (sometimes a shortened form) are listed by clicking on the help icon .
One or more of the fields will be defined as default fields. This means the if no qualifier is entered the match will be applied to all default fields using an OR operator. Sometimes all fields may be considered default which means a match term will be tested against all fields and an item will be included in the results if one or more of those fields match.
For example if the Quick Filter has fields Name, Type and Status, of which Name and Type are default:
feed status:ok
The above would match items where the Name OR Type fields match feed AND the Status field matches ok.
Match Negation
Each match item can be negated using the ! prefix.
This is also described in Common Fuzzy Matching.
The prefix is applied after the field qualifier.
E.g:
name:xml source:!/default
In the above example it would match on items where the Name field matched xml and the Source field does NOT match the regex pattern default.
Spaces and Quotes
If your match term contains a space then you can surround the match term with double quotes.
Also if your match term contains a double quote you can escape it with a \ character.
The following would be valid for example.
"name:csv splitter" "default field match" "symbol:\""
Multiple Terms
If multiple terms are provided for the same field then an AND is used to combine them. This can be useful where you are not sure of the order of words within the items being filtered.
For example:
User input: spain plain rain
Will match:
The rain in spain stays mainly in the plain
^^^^ ^^^^^ ^^^^^
rainspainplain
^^^^^^^^^^^^^^
spain plain rain
^^^^^ ^^^^^ ^^^^
raining spain plain
^^^^^^^ ^^^^^ ^^^^^
Won’t match: sprain, rain, spain
OR Logic
There is no support for combining terms with an OR. However you can acheive this using a sinlge regular expression term. For example
User input: status:/(disabled|locked)
Will match:
Locked
^^^^^^
Disabled
^^^^^^^^
Won’t match: A MAN, HUMAN
Suggestion Input Fields
Stroom uses a number of suggestion input fields, such as when selecting Feeds, Pipelines, types, status values, etc. in the pipeline processor filter screen.
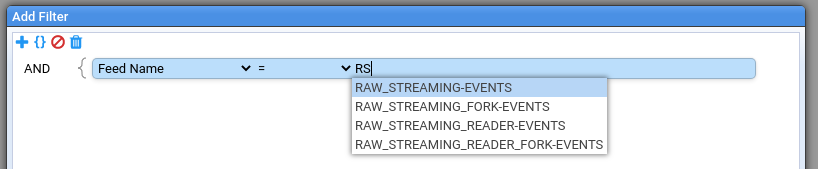
These fields will typically display the full list of values or a truncated list where the total number of value is too large. Entering text in one of these fields will use the fuzzy matching algorithm to partially/fully match on values. See CommonFuzzy Matching below for details of how the matching works.
Common Fuzzy Matching
A common fuzzy matching mechanism is used in a number of places in Stroom. It is used for partially matching the user input to a list of a list of possible values.
In some instances, the list of matched items will be truncated to a more manageable size with the expectation that the filter will be refined.
The fuzzy matching employs a number of approaches that are attempted in the following order:
NOTE: In the following examples the ^ character is used to indicate which characters have been matched.
No Input
If no input is provided all items will match.
Contains (Default)
If no prefixes or suffixes are used then all characters in the user input will need to be contained as a whole somewhere within the string being tested. The matching is case insensitive.
User input: bad
Will match:
bad angry dog
^^^
BAD
^^^
very badly
^^^
Very bad
^^^
Won’t match: dab, ba d, ba
Characters Anywhere Matching
If the user input is prefixed with a ~ (tilde) character then characters anywher matching will be employed.
The matching is case insensitive.
User input: bad
Will match:
Big Angry Dog
^ ^ ^
bad angry dog
^^^
BAD
^^^
badly
^^^
Very bad
^^^
b a d
^ ^ ^
bbaadd
^ ^ ^
Won’t match: dab, ba
Word Boundary Matching
If the user input is prefixed with a ? character then word boundary matching will be employed.
This approache uses upper case letters to denote the start of a word.
If you know the some or all of words in the item you are looking for, and their order, then condensing those words down to their first letters (capitalised) makes this a more targeted way to find what you want than the characters anywhere matching above.
Words can either be separated by characters like _- ()[]., or be distinguished with lowerCamelCase or upperCamelCase format.
An upper case letter in the input denotes the beginning of a word and any subsequent lower case characters are treated as contiguously following the character at the start of the word.
User input: ?OTheiMa
Will match:
the cat sat on their mat
^ ^^^^ ^^
ON THEIR MAT
^ ^^^^ ^^
Of their magic
^ ^^^^ ^^
o thei ma
^ ^^^^ ^^
onTheirMat
^ ^^^^ ^^
OnTheirMat
^ ^^^^ ^^
Won’t match: On the mat, the cat sat on there mat, On their moat
User input: ?MFN
Will match:
MY_FEED_NAME
^ ^ ^
MY FEED NAME
^ ^ ^
MY_FEED_OTHER_NAME
^ ^ ^
THIS_IS_MY_FEED_NAME_TOO
^ ^ ^
myFeedName
^ ^ ^
MyFeedName
^ ^ ^
also-my-feed-name
^ ^ ^
MFN
^^^
stroom.something.somethingElse.maxFileNumber
^ ^ ^
Won’t match: myfeedname, MY FEEDNAME
Regular Expression Matching
If the user input is prefixed with a / character then the remaining user input is treated as a Java syntax regular expression.
An string will be considered a match if any part of it matches the regular expression pattern.
The regular expression operates in case insensitive mode.
For more details on the syntax of java regular expressions see this internet link https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/util/regex/Pattern.html.
User input: /(^|wo)man
Will match:
MAN
^^^
A WOMAN
^^^^^
Manly
^^^
Womanly
^^^^^
Won’t match: A MAN, HUMAN
Exact Match
If the user input is prefixed with a ^ character and suffixed with a $ character then a case-insensitive exact match will be used.
E.g:
User input: ^xml-events$
Will match:
xml-events
^^^^^^^^^^
XML-EVENTS
^^^^^^^^^^
Won’t match: xslt-events, XML EVENTS, SOME-XML-EVENTS, AN-XML-EVENTS-PIPELINE
Note: Despite the similarity in syntax, this is NOT regular expression matching.
Starts With
If the user input is prefixed with a ^ character then a case-insensitive starts with match will be used.
E.g:
User input: ^events
Will match:
events
^^^^^^
EVENTS_FEED
^^^^^^
events-xslt
^^^^^^
Won’t match: xslt-events, JSON_EVENTS
Note: Despite the similarity in syntax, this is NOT regular expression matching.
Ends With
If the user input is suffixed with a $ character then a case-insensitive ends with match will be used.
E.g:
User input: events$
Will match:
events
^^^^^^
xslt-events
^^^^^^
JSON_EVENTS
^^^^^^
Won’t match: EVENTS_FEED, events-xslt
Note: Despite the similarity in syntax, this is NOT regular expression matching.
Wild-Carded Case Sensitive Exact Matching
If one or more * characters are found in the user input then this form of matching will be used.
This form of matching is to support those fields that accept wild-carded values, e.g. a whild-carded feed name expression term.
In this instance you are NOT picking a value from the suggestion list but entering a wild-carded value that will be evaluated when the expression/filter is actually used.
The user may want an expression term that matches on all feeds starting with XML_, in which case they would enter XML_*.
To give an indication of what it would match on if the list of feeds remains the same, the list of suggested items will reflect the wild-carded input.
User input: XML_*
Will match:
XML_
^^^^
XML_EVENTS
^^^^
Won’t match: BAD_XML_EVENTS, XML-EVENTS, xml_events
User input: XML_*EVENTS*
Will match:
XML_EVENTS
^^^^^^^^^^
XML_SEC_EVENTS
^^^^ ^^^^^^
XML_SEC_EVENTS_FEED
^^^^ ^^^^^^
Won’t match: BAD_XML_EVENTS, xml_events
Match Negation
A match can be negated, ie. the NOT operator using the prefix !.
This prefix can be applied before all the match prefixes listed above.
E.g:
!/(error|warn)
In the above example it will match everything except those matched by the regex pattern (error|warn).