About Stroom
Stroom provides a number of powerful capabilities:
- Data ingest. Receive and store large volumes of data such as native format logs. Ingested data is always available in its raw form.
- Data transformation pipelines. Create sequences of XSL and text operations, in order to normalise or export data in any format. It is possible to enrich data using lookups and reference data.
- Integrated transformation development. Easily add new data formats and debug the transformations if they don’t work as expected.
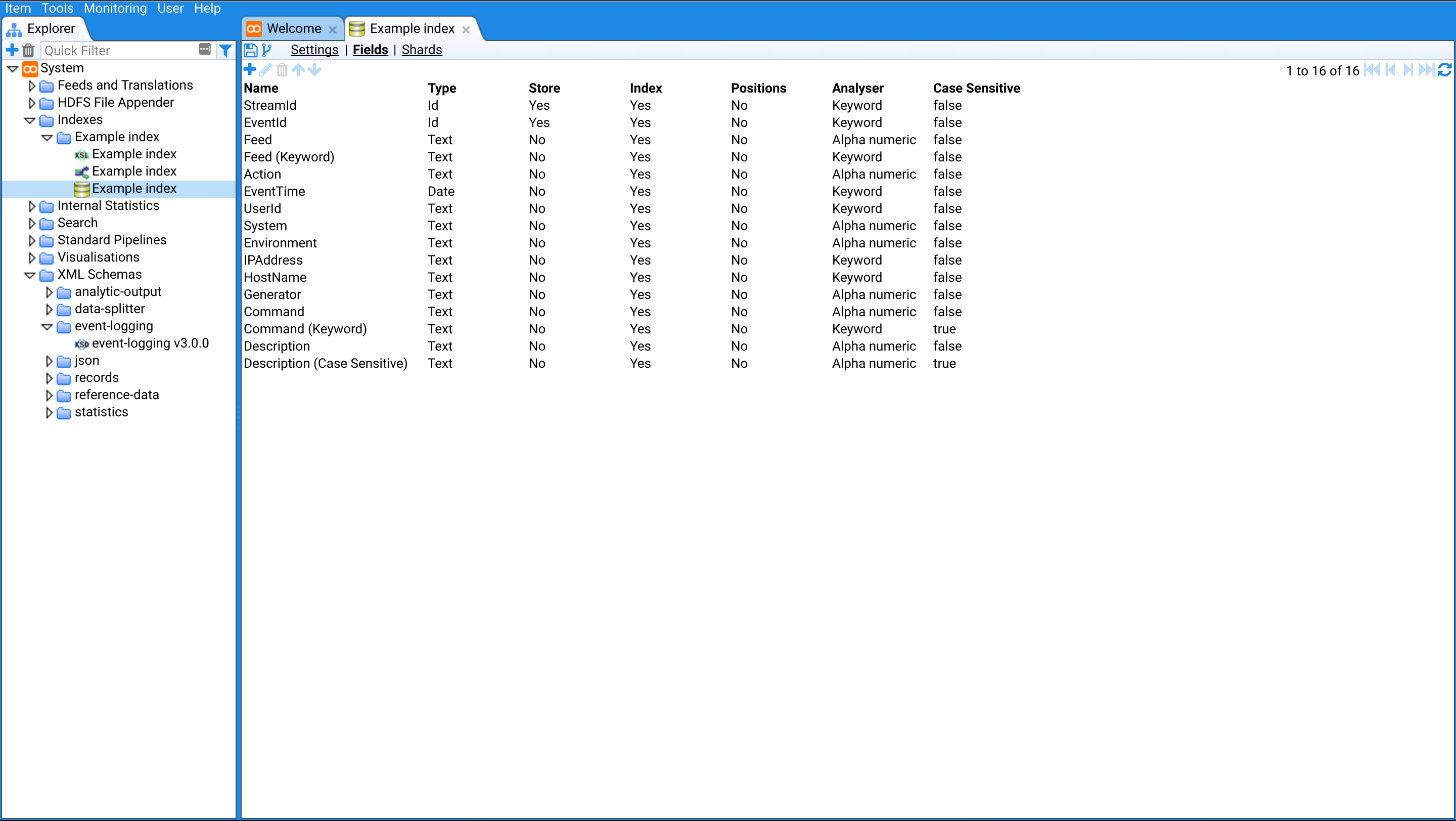
- Scalable Search. Create multiple indexes with different retention periods. These can be sharded across your cluster.
- Statistics. Record counts or values of items over time, providing answers to questions such as “how many times has a specific machine provided data in the last hour/day/month?”
- Dashboards. Run queries against your indexes or statistics and view the results within custom visualisations.
Benefits
System event data can come from many kinds of technology, this makes it highly heterogeneous with many different formats in use. As technologies are invented, new event types and log formats must be understood and processed correctly. Technology changes so rapidly that the auditing team risks being left behind.
Stroom is designed to offer a way to mitigate this risk, and has matured into an application that scales well to billions of events a day - sufficient to ingest and process the system events generated by the IT of a large organisation.
The person who introduces a new log format is probably best placed to describe it. Stroom provides these experts with tools that make it easy to normalise data, essentially crowdsourcing the problem. An organisation can ask their employees to configure Stroom whenever they introduce a new technology, and have confidence that it will be able to be properly audited.
System Overview
The following is a high level overview of how Stroom and its proxies ingest data.

Processing Overview
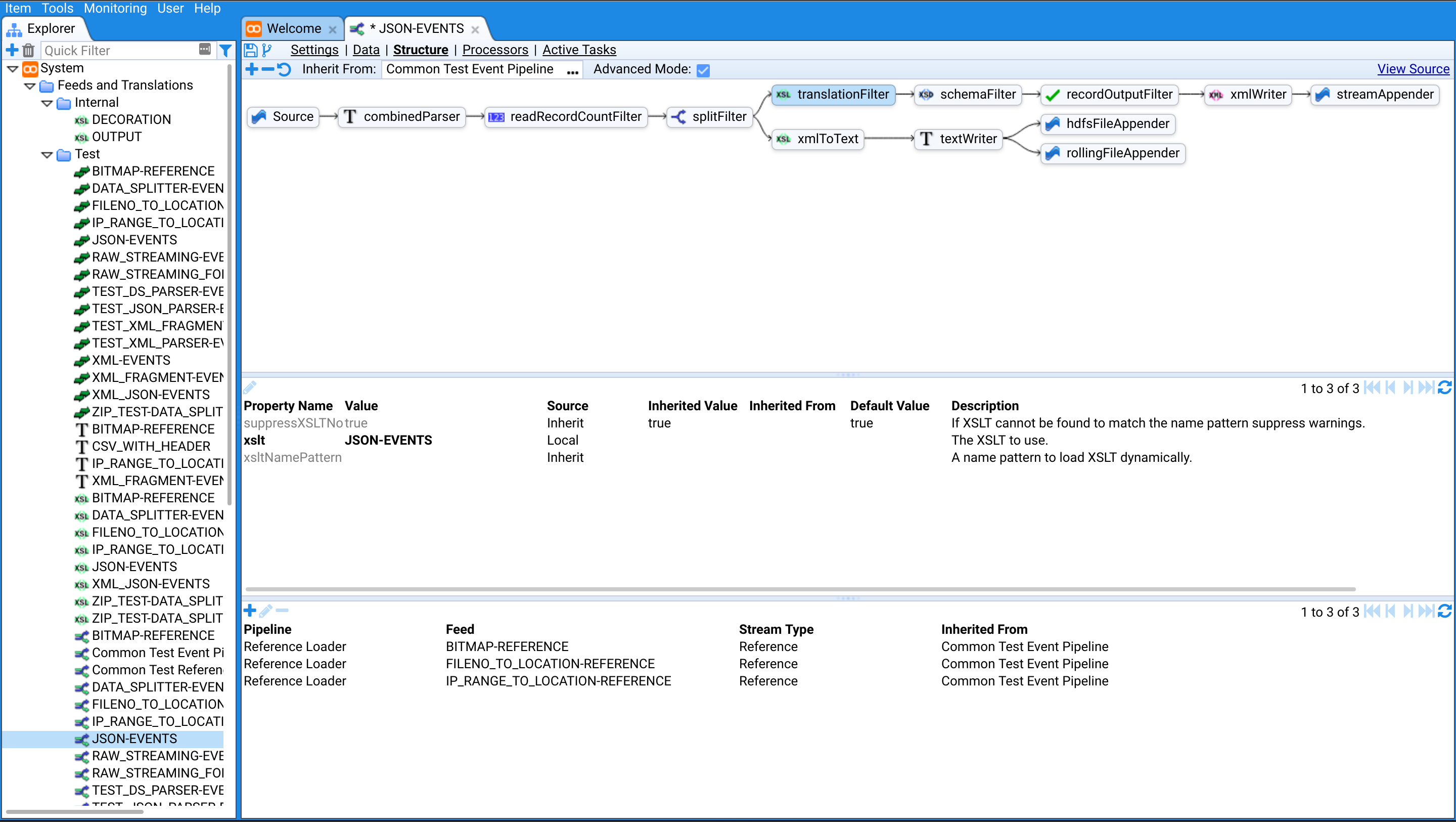
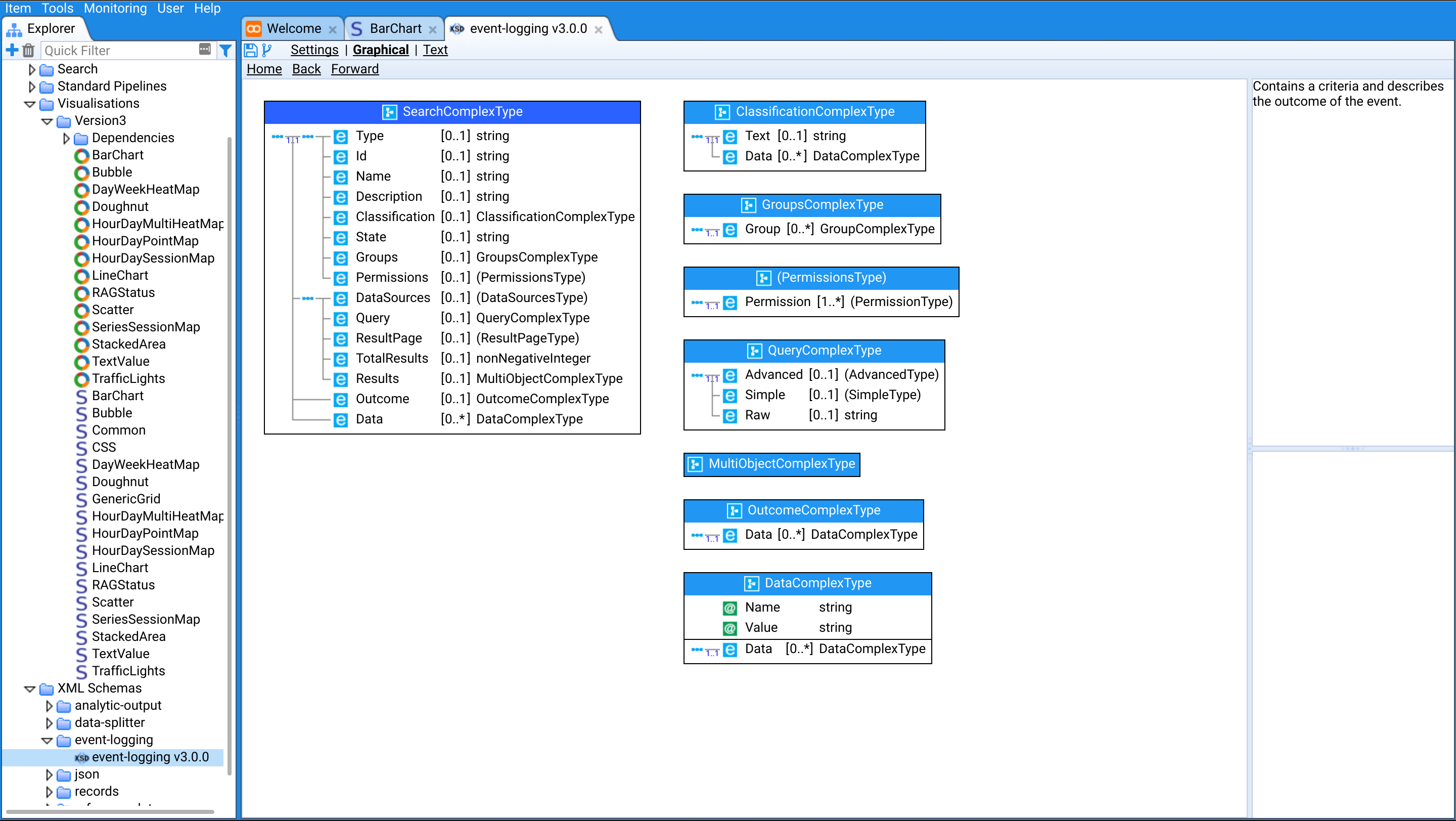
Stroom has a highly configurable pipeline based processor that allows the user to configure multiple processing pathways for ingested data. Raw data can be processed to “cook” it into a normalised form, meaning data originating from hundreds of different log formats can then be processed in the same way. Central to the normalisation process is the event-logging event-logging XML Schema that serves as the common form for all cooked data. Cooked data can be further processed to transform/index/aggregate/analyse it, e.g. for storage in another form or for sending it to external systems.

The main processing stages are:
Parsing
Data is received in many forms, CSV, JSON, XML, etc. so it is first parsed into a simple XML form that mirrors the raw data. Data Splitter is a powerful parser within Stroom for parsing all kinds of text based logs, be they delimited, fixed width, or have complex multi-line records. XML and JSON data can be handled by their respective parsers.
Translation
The translation process can involve a number of steps. The first step is to translate the simple XML into the common event-logging XML form, e.g. transforming Windows event logs and Linux auditd logs into a common form. For bespoke log formats this translation step can be authored by the owners of the system sending the log. The translation stage typically also involves the decoration of the event using reference data lookups, e.g. looking up a user ID in richer user reference data provided by a human resources system or looking up a hostname to provide location data for the device.
Writers, Filters & Appenders
Once the events are in a common decorated form they can be further transformed into other formats for indexing, statistic aggregation or for sending on to external systems. Typically cooked events will be stored in their cooked form and transformed into an abstraction suitable for indexing.
Re-Processing
All processed data in stroom can be re-processed at any time, e.g. following improvements to a translation step.
Architecture
Stroom 5.x is a Java web application that runs on Apache Tomcat, with Apache Lucene indexes over a compressed data store. It uses two MySQL RDBMSs to persist application configuration and metadata.
Stroom v6.x uses a more service oriented architecture with a number of additional peripheral services such as stroom-auth, stroom-stats, stroom-query-elastic, stroom-annotations, etc. The core Stroom application and the majority of the services all run on Dropwizard using embedded Jetty.
Stroom v7.x maintains most of the core architecture of v6 but now has the authentication service and UI integrated into it to simplify the deployment. Some elements of the GWT based UI are being re-implemented using modern web frameworks (React/Typescript). v7 also makes much heavier use of REST APIs for all client-server interaction.
Currently Stroom has only been tested with Google Chrome. For this reason some functionality may not work correctly in other browsers. Now that Stroom is an open source project, support for other browsers will be improved.
There are several optional components for different use cases:
- Stroom Proxy - An application that receives and forwards data to Stroom.
- Stroom Stats - An HBase based service for storing and querying aggregates of event data (still in development).
- Stroom Annotations - A service for recording data relating to events or records in Stroom (still in development).
- Stroom Query Elastic - A service to allow Stroom dashboards to query Elastic Search indexes.
- Stroom Agent - An application that extracts data from sources.
- Event Logging XML Schema - A common language for describing audit events.
- Event Logging JAXB Library - A Java library to help client systems send events to Stroom.
- Content Packs - Transformation packages for standard log formats (e.g. Windows, Linux) into Logging Events XML.
User Interface
Stroom has a rich and powerful web based user interface that allows users to:
- Configure and manage the processing pipelines.
- Develop content for the processing pipelines, e.g. XSLTs, data splitters.
- Create dashboards to query and visualise the data held in stroom
- Lucene index
- Solr indexes
- Statistics store
- Reference data store
- Meta data
- Data store
- Manage user permissions
Some screenshots of the application can be seen here.
State of the Project
Stroom v5 was the first open source release of Stroom and v5.5 is still being supported.
Stroom v6.1 is the current latest stable release of Stroom and this is in use in production environments.
Stroom v7.0 is currently in active development with regular beta releases available for testing.
Future
Although Stroom is a mature product it is receiving more active development effort than ever. Work is underway to evolve the existing architecture and add new features:
- Better integration with cloud services e.g. AWS.
- A rule engine for notifying analysts about particular event scenarios
- Scalable temporal state storage that could be used by rules or dashboards
- New visualisations to improve analysis
- A modularised, micro-service-based architecture
- Further integration with the Hadoop ecosystem
Developers and Contributors
If you want to contribute to the development of Stroom or its related repositories please see here.
For details of how get started setting up a Stroom development environment see here.
Stroom Content
A lot of the power of Stroom comes from the content that is developed within it. The content includes XSLT transformations, data-splitter definitions, dashboards, visualisations, processing pipeline definitions, etc. The content developed within Stroom can be exported and shared between other Stroom installations. The content can be packaged into convenient content pack zip files.
Generic Stroom content is available here
Stroom visualisations (for use in dashboards) are available here
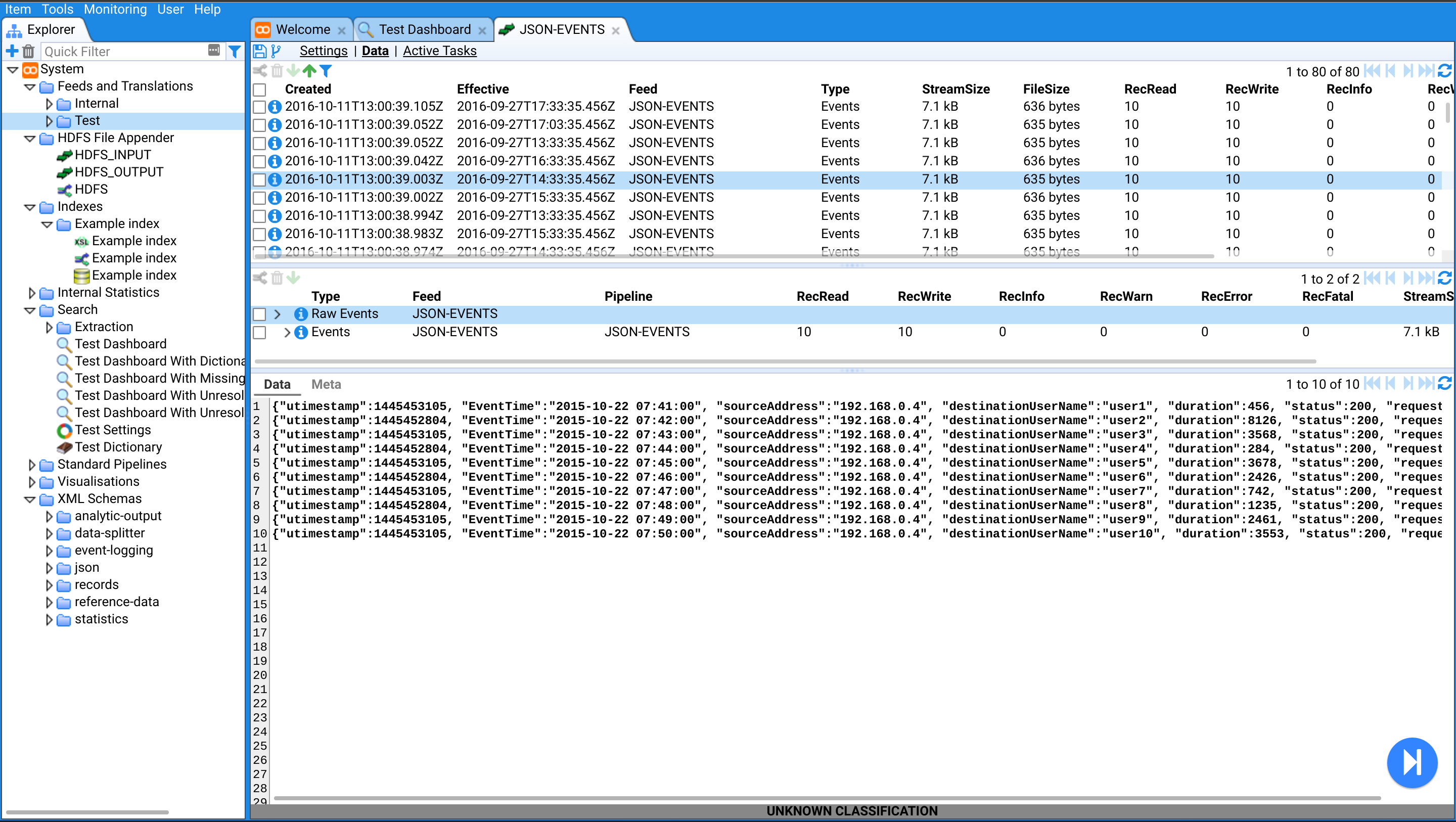
Screenshots
Some screen shots of Stroom in action.